Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Огляд методів аналізу та моніторингу мережевого трафіку
|
|
Найбільш поширені методи фільтрації мережевих даних. Декотрі з них використовуються на підприємстві, мають свої переваги та недоліки. Тому далі їх буде розглянуто детальніше.
У наступних розділах обговорюються два способи моніторингу мережі: перший - маршрутизатор-орієнтований, другий - не орієнтований на маршрутизатори. Функціональність моніторингу, який вбудований в самі маршрутизатори і не вимагає додаткової установки програмного або апаратного забезпечення, називають методами, заснованими на маршрутизаторі. Чи не засновані на маршрутизаторах методи вимагають установки апаратного та програмного забезпечення та надають велику гнучкість. Обидві техніки обговорюються нижче у відповідних розділах.
2.1.1 Методи моніторингу засновані на маршрутизаторі
Методи моніторингу засновані на маршрутизаторі - жорстко задані (вшиті) в маршрутизаторах і, отже, мають низьку гнучкість. Короткий опис найбільш часто використовуваних методів такого моніторингу наведені нижче. Кожен метод розвивався багато років перш ніж стати стандартизованим способом моніторингу.
Протокол простого мережевого моніторингу (SNMP), RFC 1157
SNMP - протокол прикладного рівня, який є частиною протоколу TCP / IP. Він дозволяє адміністраторам керувати продуктивністю мережі, знаходити і усувати мережеві проблеми, планувати зростання мережі. Він збирає статистику по трафіку до кінцевого хоста через пасивні датчики, які реалізуються разом з маршрутизатором. У той час, як існують дві версії (SNMPv1 і SNMPv2), даний розділ описує тільки SNMPv1. SNMPv2 побудований на SNMPv1 і пропонує ряд удосконалень, таких як додавання операцій з протоколами. Стандартизується ще один варіант версії SNMP. Версія 3 (SNMPv3) знаходиться на стадії розгляду.
Для протоколу SNMP притаманні три ключові компоненти: керовані пристрої (Managed Devices), агенти (Agents) та системи управління мережею (Network Management Systems - NMSs). Вони показані на рис. 1.

Рисунок. 2.1 - Компоненти SNMP
Керовані пристрої включають в себе SNMP-агента і можуть складатися з маршрутизаторів, перемикачів, комутаторів, концентраторів, персональних комп'ютерів, принтерів і інших елементів, подібних цим. Вони несуть відповідальність за збір інформації і роблять її доступною для системи управління мережею (NMS).
Агенти включають в себе програмне забезпечення, яке володіє інформацією з управління, і переводять цю інформацію в форму, сумісну з SNMP. Вони закриті для пристрою керування.
Системи управління мережею (NMS) виконують додатки, які займаються моніторингом та контролем пристроїв керування. Ресурси процесора і пам'яті, які необхідні для управління мережею, надаються NMS. Для будь керованої мережі повинна бути створена хоча б одна система управління. SNMP може діяти виключно як NMS, або агент, або може виконувати свої обов'язки або ін.
Існує 4 основних команди, які використовуються SNMP NMS для моніторингу та контролю керованих пристроїв: читання, запис, переривання та операції перетину. Операція читання розглядає змінні, які зберігаються керованими пристроями. Команда записи змінює значення змінних, які зберігаються керованими пристроями. Операції перетину володіють інформацією про те, які змінні керованих пристроїв підтримують, і збирають інформацію з підтримуваних таблиць змінних. Операція переривання використовується керованими пристроями для того, щоб повідомити NMS про настання певних подій.
SNMP використовує 4 протокольні операції в порядку дії: Get, Get Next, Set і Trap. Команда Get використовується, коли NMS видає запит на інформацію для керованих пристроїв. SNMPv1-запит складається з заголовка повідомлення і одиниці даних протоколу (PDU). PDU-повідомлення містить інформацію, яка необхідна для успішного виконання запиту, який буде або отримувати інформацію від агента, або здавати значення в агента. Керований пристрій використовує SNMP агентів, розташованих у ньому, для отримання необхідної інформації і потім посилає повідомлення NMS'у, з відповіддю на запит. Якщо агент не володіє будь якою інформацією стосовно запитом, він нічого не повертає. Команда Get Next буде отримувати значення наступного примірника об'єкта. Для NMS також можливо надсилати запит (операція Set), коли встановлюється значення елементів без агентів. Коли агент повинен повідомити NMS-події, він буде використовувати операцію Trap.
Як говорилося раніше, SNMP - протокол рівня додатків, який використовує пасивні сенсори, щоб допомогти адміністратору простежити за мережевим трафіком і продуктивністю мережі. Хоча, SNMP може бути корисним інструментом для мережевого адміністратора, він створює можливість для загрози безпеці, тому що він позбавлений можливості аутентифікації. Він відрізняється від віддаленого моніторингу (RMON), який обговорюється в наступному розділі, тим, що RMON працює на мережевому рівні і нижче, а не на прикладному.
Віддалений моніторинг (RMON), RFS 1757
RMON включає в себе різні мережеві монітори та консольні системи для зміни даних, отриманих в ході моніторингу мережі. Це розширення для SNMP інформаційної бази даних з управління (MIB). На відміну від SNMP, який повинен посилати запити про надання інформації, RMON може настроювати сигнали, які будуть «моніторити» мережу, засновану на певному критерії. RMON надає адміністраторам можливості управляти локальними мережами також добре, як віддаленими від однієї певної локації / точки. Його монітори для мережевого рівня наведені нижче. RMON має дві версії RMON і RMON2. Однак у даній статті йдеться тільки про RMON. RMON2 дозволяє проводити моніторинг на всіх мережевих рівнях. Він фокусується на IP-трафіку і трафіку прикладного рівня.
Хоча існує 3 ключові компоненти моніторингової середовища RMON, тут наводяться тільки два з них. Вони показані на рис. 2 нижче.

Рисунок. 2.2 - Компоненти RMON
Два компонента RMON це датчик, також відомий як агент або монітор, і клієнт, також відомий як керуюча станція (станція управління). На відміну від SNMP датчик або агент RMON збирає та зберігає мережеву інформацію. Датчик - це вбудоване в мережевий пристрій (наприклад маршрутизатор або перемикач) програмне забезпечення. Датчик може запускатися також і на персональному комп'ютері. Датчик повинен міститися для кожного різного сегмента локальної або глобальної мережі, оскільки вони здатні бачити трафік, який проходить тільки через їхні канали, але вони не знають про трафік за їх межами. Клієнт - це зазвичай керуюча станція, яка пов'язана з датчиком, що використовують SNMP для отримання та корекції RMON-даних.
RMON використовує 9 різних груп моніторингу для отримання інформації про мережу.
Statistics - статистика виміряна датчиком для кожного інтерфейсу моніторингу для даного пристрою. History - облік періодичних статистичних вибірок з мережі і зберігання їх для пошуку. Alarm - періодично бере статистичні зразки і порівнює їх з набором порогових значень для генерації події. Host - містить статистичні дані, пов'язані з кожним хостом, виявленим в мережі. HostTopN - готує таблиці, які описують вершину хостів (головний хост). Filters - включає фільтрацію пакетів, грунтуючись на фільтровому рівнянні для захоплення подій. Packetcapture - захоплення пакетів після їх проходження через канал. Events - контроль генерації та реєстрація подій від пристрою. Tokenring - підтримка кільцевих лексем.
Як встановлено вище, RMON, будується на протоколі SNMP. Хоча моніторинг трафіку може бути виконаний за допомогою цього методу, аналітичні дані про інформацію, отримані SNMP і RMON мають низьку продуктивність. Утиліта Netflow, яка обговорюється в наступному розділі, працює успішно з багатьма пакетами аналітичного програмного забезпечення, щоб зробити роботу адміністратора набагато простіше.
Netflow, RFS 3954
Netflow - це розширення, яке було представлено в маршрутизаторах Cisco, які надають можливість збирати IP мережевий трафік, якщо це задано в інтерфейсі. Аналізуючи дані, які надаються Netflow, мережевий адміністратор може визначити такі речі як: джерело і приймач трафіку, клас сервісу, причини переповненості. Netflow включає в себе 3 компоненти: Flow Caching (кешируєтся потік), Flow Collector (збирач інформації про потоки) і Data Analyzer (аналізатор даних). Рис. 3 показує інфраструктуру Netflow. Кожен компонент, показаний на малюнку, пояснюється нижче.

Рисунок 2.3 - Інфраструктура NetFlow
Flow Caching аналізує і збирає дані про IP потоках, які входять в інтерфейс, і перетворює дані для експорту.
З Netflow-пакетів може бути отримана наступна інформація:
- адреса джерела і одержувача;
- номер входить і виходить пристрою;
- номер порту джерела і приймача;
- протокол 4 рівня;
- кількість пакетів в потоці;
- кількість байтів в потоці;
- тимчасової штамп в потоці;
- номер автономної системи (AS) джерела і приймача;
- тип сервісу (ToS) і прапор TCP.
Перший пакет потоку, що проходить через стандартний шлях перемикання, обробляється для створення кеша. Пакети з подібними характеристиками потоку використовуються для створення запису про потік, яка поміщається в кеш для всіх активних потоків. Ця запис зазначає кількість пакетів і кількість байт в кожному потоці. Кешувального інформація потім періодично експортується в FlowCollector (збирач потоків).
Flow Collector - відповідальний за збір, фільтрування та зберігання даних. Він включає в себе історію про інформацію про потоки, які були підключені за допомогою інтерфейсу. Зниження обсягу даних також відбувається за допомогою FlowCollector'а за допомогою обраних фільтрів і агрегації.
Data Analyzer (аналізатор даних) необхідний, коли потрібно представити дані. Як показано на малюнку, зібрані дані можуть використовуватися для різних цілей, навіть відмінних від моніторингу мережі, таких як планування, облік і побудова мережі.
Перевага Netflow над іншими способами моніторингу, такими як SNMP і RMON, в тому, що в ній існує програмні пакети, призначені для різного аналізу трафіку, які існують для отримання даних від Netflow-пакетів та подання їх до більш доброзичливому для користувача вигляді.
При використанні інструментів, таких як Netflow Analyzer (це тільки один інструмент, який доступний для аналізірованіяNetflow-пакетів), інформація, наведена вище, може бути отримана від Netflow-пакетів для створення діаграм і звичайних графіків, які адміністратор може вивчити для більшого розуміння про його мережі. Найбільша перевага використання Netflow на відміну від доступних аналітичних пакетів в тому, що в даному випадку можуть бути побудовані численні графіки, що описують активність мережі в будь-який момент часу.
2.1.2 Технології не засновані на маршрутизаторах
Хоча технологією, не вбудовані в маршрутизатор все ж обмежені у своїх можливостях, вони пропонують велику гнучкість, ніж технології вбудовані в маршрутизатори. Ці методи класифікуються як активні і пасивні.
Активний моніторинг повідомляє проблеми в мережі, збираючи вимірювання між двома кінцевими точками. Система активного вимірювання має справу з такими метриками, як: корисність, маршрутизатори / маршрути, затримка пакетів, повтор пакетів, втрати пакетів, нестійка синхронізація між прибуттям, вимірювання пропускної здатності.
Головним чином використання інструментів, такі як команда ping, яка вимірює затримку і втрати пакетів, і traceroute, яка допомагає визначити топологію мережі, є прикладом основних активних інструментів вимірювання. Обидва ці інструменту посилають пробні ICMP-пакети до точки призначення і чекають, коли ця точка відповість відправнику. Рис. 4 - приклад команди ping, яка використовує активний спосіб вимірювання, посилаючи Echo-запит від джерела через мережу у встановлену точку. Потім одержувач посилає Echo-запит назад джерелу від якого прийшов запит.

Рисунок 2.4 - Команда ping (активний вимір)
Даний метод може не тільки збирати одиничні метрики про активний вимірі, а й може визначати топологію мережі. Ще один важливий приклад активного виміру - утиліта iperf. Iperf - це утиліта, яка вимірює якість пропускної здатності TCP і UDP протоколів. Вона повідомляє пропускну здатність каналу, існуючу затримку і втрати пакетів.
Проблема, яка існує з активним моніторингом, - це те, що представлені проби в мережі можуть втручатися в нормальний трафік. Часто час активних проб обробляється інакше, ніж нормальний трафік, що ставить під питання значущість наданої інформації від цих проб.
Згідно загальної інформації, описаної вище, активний моніторинг - це надзвичайно рідкісний метод моніторингу, взятий окремо. Пасивний моніторинг навпроти не вимагає великих мережевих витрат.
Пасивний моніторинг на відміну від активності не додає трафік в мережу і не змінює трафік, який вже існує в мережі. Також на відміну від активного моніторингу, пасивний збирає інформацію тільки про одну точці в мережі. Вимірювання відбуваються набагато краще, ніж між двома точками, при активному моніторингу. Рис. 5 показує установку системи пасивного моніторингу, де монітор розміщений на одиничному каналі між двома кінцевими точками і спостерігає трафік коли той проходить по каналу.

Рисунок 2.5 - Встановлення пасивного моніторингу
Пасивні вимірювання мають справу з такою інформацією, як: трафік і суміш протоколів, кількість бітів (бітрейт), синхронізація пакетів і час між прибуттям. Пасивний моніторинг може бути здійснений, за допомогою будь-якої програми, витягаючої пакети.
Хоча пасивний моніторинг не має витрат, які має активний моніторинг, він має свої недоліки. З пасивним моніторингом, вимірювання можуть бути проаналізовані тільки оф-лайн і вони не представляють колекцію. Це створює проблему, пов'язану з обробкою великих наборів даних, які зібрані під час вимірювання.
Пасивний моніторинг може бути краще активного в тому, що дані службових сигналів не додаються в мережу, але пост-обробка може викликати велику кількість тимчасових витрат. Ось чому існує комбінація цих двох методів моніторингу.
2.2.3 Комбінований моніторинг
Після прочитання розділів вище, можна благополучно переходити до висновку про те, що комбінування активного і пасивного моніторингу - кращий спосіб, ніж використання першого або другого окремо. Комбіновані технології використовують кращі сторони і пасивного, і активного моніторингу середовищ. Дві нові технології, що представляють комбіновані технології моніторингу, описуються нижче. Це «Перегляд ресурсів на кінцях мережі» (WREN) і «Монітор мережі з власної конфігурацією» (SCNM).
Перегляд ресурсів на кінцях мережі (WREN) - використовує комбінацію технік активного і пасивного моніторингу, активно обробляючи дані, коли трафік малий, і пасивно обробляючи дані протягом часу великого трафіку. Він дивиться трафік і від джерела, і від одержувача, що робить можливим більш акуратні вимірювання. WREN використовує трасування пакетів від створеного додатком трафіку для вимірювання корисної пропускної здатності. WREN розбитий на два рівні: основний рівень швидкої обробки пакетів і аналізатор трассіровок користувальницького рівня.
Основний рівень швидкої обробки пакетів відповідає за отримання інформації, пов'язаної з вхідними та вихідними пакетами. Рис. 6 показує список інформації, яка збирається для кожного пакета. До Web100 додається буфер для збору цих характеристик. Доступ до буфера здійснюється за допомогою двох системних викликів. Один виклик починає трасування і надає необхідну інформацію для її збору, поки другий виклик повертає трасування з ядра.

Рисунок 2.6 - Інформація, зібрана на головному рівні трассіровок пакетів
Об'єкт трасування пакетів - здатний координувати обчислення між різними машинами. Одна машина буде активувати роботу іншої машини, задаючи прапор в заголовку минає пакета для початку обробки деякого діапазону пакетів, які вона трассирует. Інша машина буде в свою чергу трассіровать всі пакети, для яких вона бачить, що в заголовку встановлений схожий прапор. Така координація забезпечує те, що інформація про схожих пакетах зберігається в кожній кінцевій точці незалежно від зв'язку і того, що відбувається між ними.
Аналізатор трассіровок користувацького рівня - інший рівень в середовищі WREN. Це компонент, який починає трасування будь-якого пакета, збирає й обробляє повернуті дані на рівні ядра оператора. Згідно проектування, компоненти користувальницького рівня не мають потреби в читанні інформації від об'єкта трасування пакетів весь час. Вони можуть бути проаналізовані негайно після того, як трасування буде завершена, щоб зробити висновок в реальному часі, або дані можуть бути збережені для подальшого аналізу.
Коли трафік малий, WREN буде активно вводити трафік в мережу зберігаючи порядок проходження потоків вимірювання. Після численних досліджень, знайдено, що WREN представляє схожі вимірювання в перенасичених і в не-перенасичених середовищах.
У поточній реалізації WREN, користувачі не принуждаются тільки до захоплення трассіровок, які були ініційовані ними. Хоча будь-який користувач може стежити за трафіком додатків інших користувачів, вони обмежені в інформації, яка може бути отримана від трассіровок інших користувачів. Вони можуть тільки отримати послідовність і підтвердження чисел, але не можуть отримати актуальні сегменти даних з пакетів.
Загалом, WREN - це дуже корисна установка, яка використовує переваги та активного, і пасивного моніторингу. Хоча ця технологія знаходиться на ранньому етапі розвитку, WREN може надати адміністраторам корисні ресурси в моніторингу та аналізі їх мереж. Монітор Власного конфігурування мережі (SCNM) - інший інструментарій, який використовує технології та активного, і пасивного моніторингу.
Мережевий монітор з власної конфігурацією (SCNM) - це інструмент моніторингу, який використовує зв'язок пасивних і активних вимірювань для збору інформації на 3 рівні проникнення, що виходять маршрутизаторів, та інших важливих точок моніторингу мережі. Середа SCNM включає і апаратний, і програмний компонент.
Апаратний засіб встановлюється в критичних точках мережі. Воно відповідає за пасивний збір заголовків пакетів. Програмне забезпечення запускається на кінцевій точці мережі. Рисунок 2.7, наведений нижче, показує програмний компонент SCNM середовища.
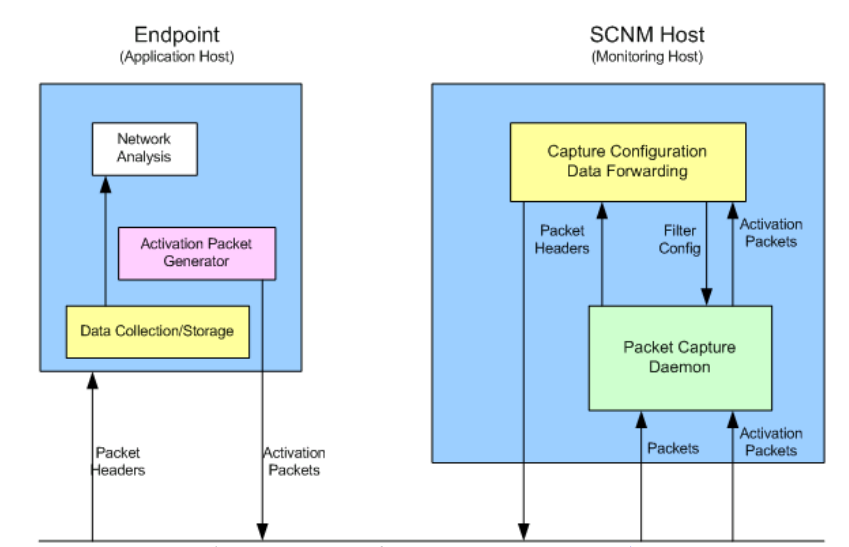
Рисунок 2.7 - Програмний компонент SCNM
Програмне забезпечення відповідає за створення і посилку активованих пакетів, які використовуються для старту моніторингу мережі. Користувачі будуть посилати в мережу пакети активації, що містять деталі про пакети, які вони хочуть отримати для моніторингу та збору. Користувачі не потребують знанні розташування SCNM-хоста, приймаючи за істину те, що всі хости відкриті для «прослушки» пакетів. На основі інформації, яка існує в рамках активаційного пакету, фільтр поміщається в потік збору даних, який також працює в кінцевій точці. Збираються заголовки пакетів мережевого і транспортного рівня, які відповідають фільтру. Фільтр буде автоматично введений в тайм аут, після точно заданого часу, якщо він отримує інші пакети додатки. Служба вибірки пакетів, яка запускається на SCNM-хості, використовує команду tcpdump (подібно програмою вибірки пакетів) у порядку отриманих запитів і записи трафіку, який відповідає запиту.
Коли інструментами пасивного моніторингу визначається проблема, трафік може бути сгенерірованни за допомогою інструментів активного моніторингу, дозволяючи збирати додаються дані для більш детального вивчення проблеми. При розгортанні цього монітора в мережі на кожному маршрутизаторі на протязі шляху, ми може вивчати тільки секції мережі, які мають проблеми.
SCNM призначений для установки і використання, головним чином, адміністраторами. Проте звичайні користувачі можуть використовувати деяку частину цієї функціональності. Хоча звичайні користувачі здатні використовувати частини середовища SCNM моніторингу, їм дозволено дивитися тільки свої власні дані.
На закінчення скажемо, що SCNM - це ще один спосіб комбінованого моніторингу, який використовує і активний, і пасивний методи, щоб допомогти адміністраторам моніторити і аналізувати їх мережі.
2.3 Основні положення інтелектуального аналізу даних
Вищерозглянуті методи дають можливість технічної реалізації фільтрації трафіку, але не звільняють мережевого адміністратора від виконання ручної праці та контролю налаштувань атрибутів процесу фільтрації. Для втілення дійсно інтелектуальної фільтрації до результатів звичайних методів мережевого моніторингу слід застосувати методи інтелектуального аналізу даних, які дозволять уникнути ручних налаштувань за рахунок впровадження машинного навчання.
2.3.1 Основні положення
Data Mining (укр. видобуток даних, інтелектуальний аналіз даних, глибинний аналіз даних) - збірна назва, що використовується для позначення сукупності методів виявлення в даних раніше невідомих, нетривіальних, практично корисних і доступних інтерпретації знань, необхідних для прийняття рішень у різних сферах людської діяльності.
Англійське словосполучення «Data Mining» поки не має усталеного перекладу на російську мову. При передачі російською мовою використовуються наступні словосполучення: просівши інформації, видобуток даних, вилучення даних, а, також, інтелектуальний аналіз даних.
Основу методів Data Mining складають всілякі методи класифікації, моделювання і прогнозування, засновані на застосуванні дерев рішень, штучних нейронних мереж, генетичних алгоритмів, еволюційного програмування, асоціативної пам'яті, нечіткої логіки. До методів Data Mining нерідко відносять статистичні методи (дескриптивний аналіз, кореляційний і регресійний аналіз, факторний аналіз, дисперсійний аналіз, компонентний аналіз, дискримінантний аналіз, аналіз часових рядів, аналіз виживаності, аналіз зв'язків). Такі методи, однак, припускають деякі апріорні уявлення про аналізованих даних, що дещо розходиться з цілями Data Mining (виявлення раніше невідомих нетривіальних і практично корисних знань).
Одне з найважливіших призначень методів Data Mining полягає в наочному поданні результатів обчислень (візуалізація), що дозволяє використовувати інструментарій Data Mining людьми, які мають спеціальної математичної підготовки. У той же час, застосування статистичних методів аналізу даних вимагає доброго володіння теорією ймовірностей і математичної статистикою.
Інтелектуальний аналіз даних являє собою процес виявлення придатних до використання відомостей у великих наборах даних. В інтелектуальному аналізі даних застосовується математичний аналіз для виявлення закономірностей і тенденцій, що існують у даних. Зазвичай такі закономірності не можна виявити при традиційному перегляді даних, оскільки зв'язку занадто складні, або через надмірне обсягу даних.
Постановка завдання
Спочатку завдання ставиться таким чином:
- є достатньо велика база даних;
- передбачається, що в базі даних знаходяться якісь «приховані знання».
Необхідно розробити методи виявлення знань, прихованих у великих обсягах вихідних «сирих» даних. У поточних умовах глобальної конкуренції саме знайдені закономірності (знання) можуть бути джерелом додаткової конкурентної переваги.
Що означає «приховані знання»? Це повинні бути обов'язково знання:
- раніше невідомі - тобто такі знання, які повинні бути новими (а не підтверджують якісь раніше отримані відомості);
- нетривіальні - тобто такі, які не можна просто так побачити (при безпосередньому візуальному аналізі даних або при обчисленні простих статистичних характеристик);
- практично корисні - тобто такі знання, які представляють цінність для дослідника або споживача;
- доступні для інтерпретації - тобто такі знання, які легко представити в наочній для користувача формі і легко пояснити в термінах предметної області.
Ці вимоги в чому визначають суть методів Data mining і те, в якому вигляді і в якому співвідношенні в технології Data mining використовуються системи управління базами даних, статистичні методи аналізу та методи штучного інтелекту.
Ці закономірності і тренди можна зібрати разом і визначити як модель інтелектуального аналізу даних. Моделі інтелектуального аналізу даних можуть застосовуватися до конкретних сценаріями, а саме:
Прогноз: оцінка продажів, прогнозування навантаження сервера або часу простою сервера
Ризики та ймовірності: вибір найбільш придатних замовників для цільової розсилки, визначення точки рівноваги для ризикованих сценаріїв, призначення ймовірностей діагнозами або інших результатів
Рекомендації: визначення продуктів, які з високою часткою ймовірності можуть бути продані разом, створення рекомендацій
Визначення послідовностей: аналіз вибору замовників під час здійснення покупок, прогнозування наступного можливої події
Групування: поділ замовників або подій на кластери пов'язаних елементів, аналіз і прогнозування спільних рис
Побудова моделі інтелектуального аналізу даних є частиною більш масштабного процесу, в який входять всі завдання, від формулювання питань щодо даних і створення моделі для відповідей на ці питання до розгортання моделі в робочому середовищі. Цей процес можна представити як послідовність наступних шести базових кроків.

Рисунок 2.8 – Побудова моделі
Завдання, які вирішуються методами Data Mining, прийнято розділяти на описові (англ. Descriptive) і провісні (англ. Predictive).
В описових завданнях найголовніше - це дати наочне опис наявних прихованих закономірностей, в той час як в провісних завданнях на першому плані стоїть питання про пророкування для тих випадків, для яких даних ще немає.
До описових завдань відносяться:
- пошук асоціативних правил або патернів (зразків);
- групування об'єктів, кластерний аналіз;
- побудова регресійної моделі.
До провісних завдань відносяться:
- класифікація об'єктів (для заздалегідь заданих класів);
- регресійний аналіз, аналіз часових рядів.
Для задач класифікації характерно «навчання з вчителем», при якому побудова (навчання) моделі проводиться за вибіркою, що містить вхідні і вихідні вектори.
Для задач кластеризації та асоціації застосовується «навчання без вчителя», при якому побудова моделі проводиться за вибіркою, в якій немає вихідного параметра. Значення вихідного параметра («відноситься до кластеру...», «схожий на вектор...») підбирається автоматично в процесі навчання.
Для завдань скорочення опису характерна відсутність поділу на вхідні і вихідні вектори. Починаючи з класичних робіт К. Пірсона за методом головних компонент, основна увага приділяється апроксимації даних.
2.3.2 Штучні нейронні мережі
Штучна нейронна мережа (ІНС) - математична модель, а також її програмне або апаратне втілення, побудована за принципом організації та функціонування біологічних нейронних мереж - мереж нервових клітин живого організму. Це поняття виникло при вивченні процесів, що протікають в мозку, і при спробі змоделювати ці процеси. Першою такою спробою були нейронні мережі У. Маккалок і У. Питтса. Після розробки алгоритмів навчання одержувані моделі стали використовувати в практичних цілях: в задачах прогнозування, для розпізнавання образів, в задачах управління та ін.
ІНС являють собою систему з'єднаних і взаємодіючих між собою простих процесорів (штучних нейронів). Такі процесори зазвичай досить прості (особливо в порівнянні з процесорами, використовуваними в персональних комп'ютерах). Кожен процесор подібної мережі має справу тільки з сигналами, які він періодично отримує, і сигналами, які він періодично посилає іншим процесорам. І, тим не менш, будучи з'єднаними в досить велику мережу з керованим взаємодією, такі локально прості процесори разом здатні виконувати досить складні завдання.
З точки зору машинного навчання, нейронна мережа являє собою окремий випадок методів розпізнавання образів, дискримінантного аналізу, методів кластеризації і т. П. З математичної точки зору, навчання нейронних мереж - це багатопараметрична завдання нелінійної оптимізації. З точки зору кібернетики, нейронна мережа використовується в задачах адаптивного управління і як алгоритми для робототехніки. З точки зору розвитку обчислювальної техніки та програмування, нейронна мережа - спосіб вирішення проблеми ефективного паралелізму [2]. А з точки зору штучного інтелекту, ІНС є основою філософської течії коннектівізма і основним напрямком у структурному підході з вивчення можливості побудови (моделювання) природного інтелекту за допомогою комп'ютерних алгоритмів.
Нейронні мережі не програмуються у звичному розумінні цього слова, вони навчаються. Можливість навчання - одна з головних переваг нейронних мереж перед традиційними алгоритмами. Технічно навчання полягає в знаходженні коефіцієнтів зв'язків між нейронами. У процесі навчання нейронна мережа здатна виявляти складні залежності між вхідними даними і вихідними, а також виконувати узагальнення. Це означає, що в разі успішного навчання мережа зможе повернути вірний результат на підставі даних, які були відсутні в навчальній вибірці, а також неповних та / або «зашумленних», частково перекручених даних.
2.4 Висновки до другого розділу
В цьому розділі було проведено дослідження існуючих методів мережевого моніторингу. Для того, щоб зробити фільтрацію трафіку дійсно інтелектуальною, було також вирішено використати один із методів інтелектуального аналізу даних. Для цього проведено короткий екскурс до цього поняття, а також роздавлений один із його методів – штучні нейронні мережі. Цей метод і буде використано у розробці продукту.
Підбираючи приватні інструменти для використання їх в моніторингу мережі, адміністратор повинен спочатку вирішити, чи хоче він використовувати добре зарекомендували себе системи, які вже використовувалися багато років, або нові. Якщо існуючі системи більш відповідне рішення, тоді NetFlow - найбільш корисний інструмент для використання, так як в зв'язки з цією утилітою можуть використовуватися аналізує пакети даних для представлення даних в більш доброзичливому користувачеві вигляді. Тим не менш, якщо адміністратор готовий спробувати нову систему, рішення комбінованого моніторингу, такі як WREN або SCNM, - краще напрямок для подальшої роботи.
Стеження і аналіз мережі зараз необхідні в роботі системної мережі. Адміністратори повинні намагатися утримувати свою мережу в порядку, як для не розрізненої продуктивності всередині компанії, так і для зв'язку з будь-якими існуючими публічними сервісами. Згідно вищеописаної інформації, деяке число маршрутизаторів-орієнтованих технологій і не засновані на маршрутизаторах, придатні для допомоги мережевим адміністраторам в щоденному моніторингу та аналізі їх мереж. Тут коротко описуються SNMP, RMON, і Cisco's NetFlow - приклад декількох технологій, заснованих на маршрутизаторах. Приклади не базованих на маршрутизаторах технологій, які обговорювалися в статті, - це активний, пасивний моніторинг та їх поєднання.
3 ПРОЕКТУВАННЯ ТА РЕАЛІЗАЦІЯ ПРОЕКТУ
У даному розділі розглянуто процес проектування продукту дипломного проекту, включаючи створення вимог та сценаріїв, реалізацію обраних рішень, уведення методів інтелектуального аналізу до вже реалізованих алгоритмів та тестування вихідного продукту.
3.1 Мета та завдання інформаційної системи
Мета – інтелектуальна фільтрація трафіку користувачів мережі.
Завдання – розробити програму, що надає доступ до інтерфейсу перегляду інтернет-статистики, включаючи такі інструменті як сортування, графіки, таблиці тощо; також продукт має здійснювати інтелектуальну фільтрацію трафіку – тобто ведення та редагування прав доступу користувачів без допомоги системного адміністратора.
Вхідний інформаційний потік продукту - це дата, потрібний користувач або відділ, що обирає оператор для відображення, а також елементи навчання програми.
Вихідний інформаційний потік продукту - відображення обраної інформації в різних форматах (цифровий, графічний тощо), автоматичне редагування штрафних очок, зміна декотрих прав користувачів.
3.2 Керування вимогами до дипломної програми
3.2.1 Типи користувачей
Даний програмний продукт має на увазі два типа акторів – «Користувач» та «Розробник». Актор «Користувач» (керівник відділу або системний адміністратор) буде працювати з програмою, використовуючи її можливості (перегляд трафіку з усіма відповідними інструментами, а також навчання програми та редагування її роботи, якщо це потребується). Програма має аутентифікацію за логіном, прив’язаним до працівника, тому користувач без належних прав доступу не зможе працювати з програмою. Актор «Розробник» забезпечує техпідтримку та оновлення/оптимізацію знайдених помилок в роботі продукту.
3.2.2 Функціональні вимоги
Програмний продукт має такі функціональні вимоги:
- підключення користувачами до інтерфейсу за допомогою аутентифікації логін-пароль, що зберігаються у БД підприємства;
- обирання та відображення потрібної дати для перегляду;
- обирання та відображення трафіку конкретного працівника;
- відображення таблиці трафіку;
- відображення графіка трафіку;
- редагування штрафних очок користувачів;
- занесення сайтів у чорний або білий списки.
3.2.3 Моделювання прецедентів

Рис. 3.1 - Діаграма прецедентів.
3.2.4 Нефункціональні вимоги
Даний програмний продукт був розроблений на МП Java, також використовувалися додаткові програмні бібліотеки та технології: Java SDK - JDK, ADT; JSP, WMI, JSF + PrimeFaces. Розроблено на платформі Eclipse.
3.3 Проектування ІС
Даний підрозділ являє собою опис ключових архітектурно значущих рішень пов'язаних з проектом «Інтелектуальна фільтрація трафіку працівників підприємства». Аудиторія, на яку розрахований документ – користувачі програми, або «оператори», що будуть переглядати дані стосовно трафіку, а також навчати програму та контролювати її подальшу роботу після проведеного навчання й перших автоматичних дій.
3.3.1 Ідентифікація архетипу ІС
Архетип цієї програми – Desktop Application (DA). Додаток розроблений під платформу Windows. Додаток виконується на більшості пристроїв – включаючи й такі з обмеженими ресурсами або слабкими апаратними параметрами. Коректні сценарії роботи гарантуються тільки у місцевій мережі підприємства.
3.3.2 Ключові сценарії
Ключові сценарії у порядку початку роботи з програмою:
1) сценарій аутентифікації:
а) відображення полей логін-пароль. У разі успіху перейти до функції 1б.
б) перевірка уведеного паролю. У разі успіху перейти до фунції 2а.
2) сценарій вибору дати:
а) відображення календару. У разі успіху перейти до функції 2б;
б) вибір дати для запиту, у разі успіху перейти до функції 2в;
в) запит до БД. У разі успіху перейти до функції 3а.
3) відображення інформаціі:
а) відображення таблиці трафіку. У разі вибору перехід до функції 3б;
б) вибір конкретного працівника. У разі вибору перехід до функції 4а.
4) робота з працівником:
а) відображення інформації про обраного працівника. У разі успіху перехід до функції 4б;
б) відгуки на всі дії користувача – змінення штрафних очок, редагування чорного/білого листів тощо.
3.3.3 Інтерфейс користувача ІС
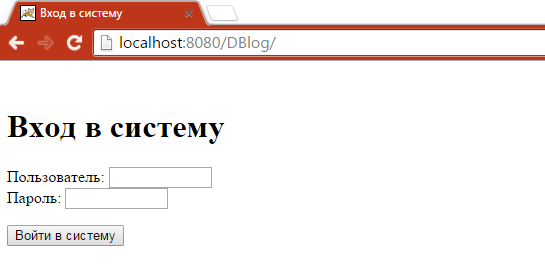
Рисунок 3.1 - Вікно аутентифікації
1 – Поля логіну та паролю
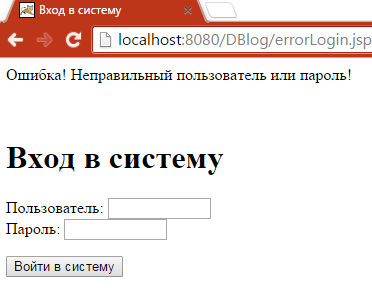
Рисунок 3.2. Повідомлення про невдачу аутентифікації
2 – Текст повідомлення

Рисунок 3.3 - Вікно вибору дати та відділу підприємства
3 – Поля вибору дати
4 – Поля вибору відділу

Рисунок 3.4 - Таблиця загального трафіку
5 – Таблиця статистики
6 – Поле вибору IP для детальної статистики

Рисунок 3.5 - Таблиця детальної статистики трафіку
7 – Таблиця детальної статистики
3.3.3 Організація шарів ІС
Шари ІС:
- верхній (користувальницький, містить все необхідне користувачеві, в тому числі GUI, меню та інші засоби управління). Він включає в себе чотири сторінки: login.jsp (вікно аутентифікації), errorLogin.jsp (вікно з повідомленням про помилку аутентифікації), chooseDate.jsp (вікно вибору дати), table.jsp (вікно зі статистикою трафіку);
- шар роботи з БД (містить клас Check.java (аутентифікація з підключенням до БД, запити до бази). Він містить бібліотеку WMI;
- шар інтеграції в ОС (містить бібліотеки, що організують роботу програми у складі операційної системи) – JSP, JSF, PrimeFaces.
Взаємодія між шарами:
- верхній шар - шар роботи з інтерфейсом програми: аутентифікація та введення дати користувачем - передача їх через запит до шару роботи з БД;
- шар роботи з БД – обробка запитів та передача відповідей до верхнього шару;
- шар інтеграції – підтримка коректної праці програми за допомогою імпортованих бібліотек.
3.3.4 Відображення ключових сценаріїв
Таблиця 3.1 - Ключові сценарії з погляду користувача
| Користувач | Програма | БД | |||||||||||||
|
|
|
3.3.5 Комунікації всередині програми
Рисунок 3.7 - Діаграма послідовності
3.4 Реалізація ІС
У цьому підрозділі розглянуто втілення проекту в конкретний програмний продукт с використовуванням вищезазначених ідей проектування; докладно розписано механізм та правила (логіку) навчання програми для інтелектуальної фільтрації.
3.4.1 Реалізація алгоритму інтелектуального аналізу
Щоб мати змогу впливати на права доступу працівників, до їх записів у БД було додано новий параметр – «рейтинг порушень». Спочатку ця змінна дорівнює «0» для кожного користувача, але може інкрементуватися, якщо даний працівник порушив яке-небудь правило, наприклад, використав забагато трафіку, ніж певний ліміт. Після набору декількох очок у цьому рейтингу програма починає використовувати певні типі санкцій, наприклад, блокування декотрих сайтів. Детальна відповідність між рейтингом та санкціями буде наведено далі. Після аналізу щоденного трафіку було також вирішено увести «чорний список» - перелік доменів, відвідування або скачування з котрих і призводить до появи штрафних очок. Для цього списку створену окрему таблицю в БД, де до кожного сайту-домену також прикріплено новий параметр - свій власний «рейтинг загрози».
3.4.2 Інтерфейс програмного продукту
3.5 Забезпечення якості ІС
Розділ включає вжиті заходи, спрямовані на поліпшення якості ІС через тестування продукту.
3.5.1 Розрахунок метрик ІС
Таблиця 3.2 - Метрики ІС
| Метрика | Одиниця виміру |
| Загальна кількість рядків коду в проекті ІС | |
| Середня кількість рядків коду в одному класі. | 59, 564 |
| Максимальна кількість рядків коду в одному класі. | |
| Середня кількість рядків коду в одному методі. | 8, 429 |
| Максимальна кількість рядків коду в одному методі. | |
| Максимальна глибина дерева успадкування | |
| Середня цикломатична складність методу. | 2, 214 |
| Максимальна цикломатическая складність методу. | |
| Коментування коду | 1, 5% |
| Покриття коду модульними тестами | 73% |
3.5.2 Розробка тест-плану
При розробці та тестуванні ІС були задіяні функціональні (чорний ящик) та модульні тести.
Інструменти тестування– JUnit, а також методом чорного ящику.Тестування проводиться на двух конфігураціях: мобільний прилад, планшет.
Для правильної роботи програми потрібне постійне підключення до Інтернета.
3.5.3 Протокол проведення модульного тестування
Обов'язковою умовою є використання модульних тестів ІС. Кожна компонента ІС повинна бути покрита якомога більшою кількістю модульних тестів (прийнятний рівень 70% від загальної кількості коду, розробленого студентом). Необхідно навести повний список всіх розроблених тестів, із зазначенням, на що спрямований той чи інший тест.
Тест1. Збереження та відновлення стану MainActivity.
Виберемо компоненту, що повинна зберігати своє значення, навіть якщо вікно на деякий час змінило своє положення. У MainActivity це Spinner. Змінимо його значення зі стандартного на будь-яке інше. Воно не повинно змінитися після зупинки та відновлення MainActivity.
Результат тесту: Spinner не змінив свого значення, MainActivity працює вірно.
Тест 2. Збереження та відновлення стану CountryListActivity.
Виберемо компоненту, щоповинназберігати своє значення, навіть якщо вікно на деякий час змінило своє положення. У CountryListActivity це Button. Змінимо його значення зі стандартного на будь-яке інше. Воно не повинно змінитися після зупинки та відновлення CountryListActivity.
Результат тесту: Button не змінив свого значення, CountryListActivity працює вірно.
Тест 3. Збереження та відновлення стану CountryActivity.
Виберемо компоненту, що повинна зберігати своє значення, навіть якщо вікно на деякий час змінило своє положення. У CountryActivity це тільки одна компонента TextView. Змінимо його значення зі стандартного на будь-яке інше. Воно не повинно змінитися після зупинки та відновлення CountryActivity.
Результат тесту: Text View не змінив свого значення, CountryActivity працює вірно.
3.5.4 Протокол проведення функціонального тестування
Тест-кейс 1. Аутентифікація.
Необхідні дії: Уведення логіну й паролю та натискання кнопки.
Очікуваний результат: Перехід до меню з вибором дати.
Результат програми: Перехід до вікна вибора дати.
Тест-кейс 2. Задання потрібної дати.
Необхідні дії: Обирання потрібної дати та натискання кнопки.
Очікуваний результат: Перехід жо наступного вікна, що відображує таблицю трафіку по заданій даті.
Результат програми: Перехід до наступного вікна, що відображає таблицю.
Тест-кейс 3. Перегляд детальної статистики.
Необхідні дії: Уведення IP-адреси та натискання кнопки.
Очікуваний результат: Перехід до вікна детальної статистики.
Результат програми: Перехід до вікна детальної статистики.
3.6 Атрибути якості
Атрибути визначають те, як ІС буде реагувати і забезпечувати якість для різного кола питань. Вони включають в себе засоби управління ІС, безпека, стратегію доставки, стратегію забезпечення якості, стратегію забезпечення забезпечення документації проекту.
3.6.1 Засоби управління ІС
Засобом управління є програма на платформі Windows. У ній реалізовано підключення користувача до БД, можливість вибору відображаємої інформації, відображення її на екрані, додаткові налаштування: вибір типу відображення, що змінює таблиці на графіки та навпаки.
3.6.2. Безпека
У цьому додатку реалізована аутентифікація за допомогою перевірки звя'зки логін-пароль у БД підприємства.
3.6.3. Стратегія доставки:
Установка з файлового серверу місцевої мережі.
3.6.4. Стратегія забезпечення якості:
Оновлення та підтримка користувачей розробником.
3.6.5. Стратегія забезпечення документації проекту:
З програмним продуктом надається інструкція до користування додатком, інструкція для ручної установки програми.
3.6.6 Список використаних технологій
1. JRE. Середовище розробки програм. https://www.oracle.com/ technetwork/java/javase/downloads/jre7-downloads-1880261.html
2. Eclipse IDE. Адреса офіційного сайту - https://www.eclipse.org/. Середа розробки даної програми.
3. PrimeFaces. Бібліотеки JSF. https://primefaces.org/
4. WMI. Windows Management Istrumentation libraires. https://msdn.microsoft.com/en-us/library/wmi.
3.7 Проектна документація
3.3.1 Керівництво користувача.
Дане керівництво призначено для користувачів розроблюваної ІС і містить в собі короткий опис функцій ІС і кроків користувача, необхідних для використання цих функцій.
3.3.1.1 Запуск програми
Запуск програми може відбуватись з робочого столу пристрою. Відразу відкривається головний екран (MainActivity) (Рисунок 3.11).

Рис.3.11. Ярлик програми
Наступне вікно – це login.jsp (Рисунок 3.14). Користувач вводить свої логін та пароль.
Рис.3.11. Аутентифікація
3.3.1.2 Вибір дати та відділу для перегляду.
Після аутентифікації програма переходить до вибору дати сортування..
Рис. 3.15. Вибір дати
3.3.3.2 Системні вимоги до програми
Системні вимоги ІС: OS Windows XP або вище, наявність місцевої мережі.
3.3.3.3 Збірка програми
Дотримуйтесь запропонованих кроків для досягнення найкращого результату в ході установки ІС на цільове обладнання:
1) Скопіюйте даний файл на пристрій.
2) За допомогою стандартного інсталятора встановіть програму.
3.3.3.4 Параметри конфігураційних файлів
Manifest.xml – це необхідний файл у будь-якому проекті. Він визначає глобальні значення для вашого пакета, в ньому ви описуєте, що знаходиться всередині вашої програми - діяльності, сервіси і тд. Ви так само визначаєте, як всі ці елементи взаємодіють з програмою.