Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Обобщенные КС-грамматики и приведение их к удлиняющей
|
|
Форме
КС-грамматика называется обобщенной, если она содержит аннулирующие правила (e - правила), то есть правила вида A® e, где e - пустая цепочка. Обобщенная грамматика зачастую более проста и наглядна. Тем не менее следует помнить, что для любой обобщенной КС-грамматики существует эквивалентная неукорачивающая КС-грамматика.
Теорема 4.6. Каждая КС-грамматика приводима к виду не более чем с одним аннулирующим правилом S® e, которого может и не быть.
Доказательство. Проведем его, как обычно, конструктивно, построением неукорачивающей грамматики.
Во-первых, нужно определить, порождает ли исходная грамматика пустую цепочку. Пусть S - начальный символ исходной грамматики G. Определим в G множество нетерминалов X i, из которых пустую цепочку можно получить за i шагов, и множество новых нетерминалов Zi. Таким образом мы определим аннулирующие нетерминалы.
X0 = { A | $ A® e }, Z0 = X0
X1 = { A | $ A® x, где xÎ X0 }, Z1 = X1\ X0
....................................................................
X i = { A | $ A® x, где xÎ 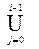 X j }, Z i = X i\ X i-1
X j }, Z i = X i\ X i-1
На каком-то шаге Z i станет равным Æ и процесс формирования аннулирующих нетерминалов можно закончить. Если S Ï X j, где 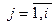 , то e Ï L(G) и правила S® e добавлять не надо. В противном случае, заменим в исходной грамматике во всех правилах S на S1, введем новый исходный нетерминал S и к правилам грамматики G добавим правила S® e ½ S1.
, то e Ï L(G) и правила S® e добавлять не надо. В противном случае, заменим в исходной грамматике во всех правилах S на S1, введем новый исходный нетерминал S и к правилам грамматики G добавим правила S® e ½ S1.
Все остальные правила вида A® e можно удалить. Для этого заменим каждое из правил, правые части которых содержат хотя бы по одному аннулирующему нетерминалу, множеством новых правил. Если правая часть правила содержит k вхождений аннулирующих нетерминалов, то множество, заменяющее это правило, будет состоять из 2k правил, соответствующих всем возможным способам удаления некоторых (или всех) из этих вхождений.
Пусть имеется правило
B® j 1 A 1 j 2 A 2 j 3 ... j k A k j k+1,
где A i (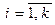 ) - аннулирующие нетерминалы. Добавим к этому правилу следующие правила:
) - аннулирующие нетерминалы. Добавим к этому правилу следующие правила:
B® j 1 j 2 A 2 j 3 ... j k A k j k+1, удалено A 1
B® j 1 A 1 j 2 j 3 ... j k A k j k+1, удалено A 2
..................................
B® j 1 A 1 j 2 A 2 j 3 ... j k j k+1, удалено A k
B® j 1 j 2 j 3 ... j k A k j k+1, удалены A 1, A 2
..................................
B® j 1 j 2 j 3 ... j k j k+1, удалены A 1, A 2,... A k .
Заметим, что в случае неоднозначности, на этом шаге может получиться меньше чем 2k правил. Так, для аннулирующего нетерминала A, правило B® aAA будет заменяться тремя правилами B® aAA ½ aA ½ a, так как в данном случае безразлично первое или второе вхождение A мы рассматриваем.
После такой замены правил для всех правых частей исходной грамматики, содержащих аннулирующие нетерминалы, исключим из грамматики все e - правила, включая те, которые могли появиться при замене.
В результате мы получим грамматику, эквивалентную исходной, что доказывается с использованием теорем 4.1 и 4.3.
Отметим, что мы рассматривали случай, когда аннулирующие нетерминалы имеют и другие альтернативы, кроме перехода в пустую цепочку. Если A ® e единственная альтернатива нетерминала A, то правые части правил, содержащие его вхождение, можно просто исключить. ƒ
В результате применения рассмотренного алгоритма можно получить КС-грамматику, по которой вывод любой непустой цепочки характеризуется тем, что сентенциальная форма, получаемая на каждом шаге вывода, будет не короче предыдущей. Не случайно полученная грамматика носит название неукорачивающей КС-грамматики (НКС-грамматики).
Пример 4.5. Рассмотрим обобщенную КС-грамматику с аксиомой < число>.
< число> ® < знак> < цел.часть>. < др.часть>
< знак> ® + ½ - ½ e
< цел.часть> ® < цел.часть> < цифра> ½ e
< др.часть> ® < цел.часть>
< цифра> ® 0 ½ 1 ½...½ 8 ½ 9 и приведем ее к неукорачивающей форме.
Вначале покажем, что данная грамматика не порождает пустой цепочки. Здесь
X0 = { < знак>, < цел.часть> },
X1 = { < др.часть> },
X2 = Æ и Z2 = Æ.
Среди множеств X - нет нетерминала < число> и, следовательно, правила
< число> ® e добавлять не надо.
Проведем замены правил, правые части которых содержат аннулирующие нетерминалы, а затем удалим e - правила.
В результате получим грамматику
< число> ® < знак> < цел.часть>. < др.часть> ½ < цел.часть>. < др.часть> ½
< знак>. < др.часть> ½ < знак> < цел.часть>. ½. < др.часть> ½
< цел.часть>. ½ < знак>. ½.
< цел.часть> ® < цел.часть> < цифра> ½ < цифра>
< др.часть> ® < цел.часть>
< цифра> ® 0 ½ 1 ½...½ 8 ½ 9
На рис. 4.2 представлены деревья вывода цепочки +.9 по исходной (рис. 4.2 (а)) и результирующей (рис. 4.2 (б)) грамматикам.
Для приведения грамматики к удлиняющей форме необходимо кроме аннулирующих правил исключить и цепные правила. Цепное правило - это правило вида A® B, где A, B Î N.
Теорема 4.7. Для любой КС-грамматики существует эквивалентная ей грамматика без цепных правил.
Доказательство. Пусть в грамматике имеется правило A ® B и A ¹ S (A - не начальный символ грамматики). Тогда все правила вида C ® aAb заменим на правила C ® aBb, а правила A ® B удалим. Если A = S и для B существуют правила B ® j 1 ½ ... ½ j n, то заменим их на S ® j 1 ½ ... ½ j n , после чего S ® B удалим.
Любое такое преобразование правил допустимо исходя из теорем 4.1 - 4.3 и устраняет правила вида A ® B. Повторяем такие преобразования до тех пор, пока в грамматике не останется цепных правил. š
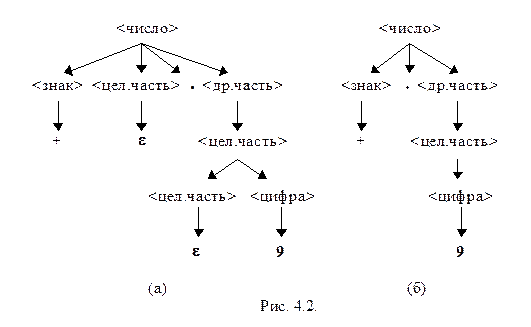 š
š
В результате устранения аннулирующих и цепных правил получается грамматика в удлиняющей форме, где сентенциальная форма на каждом шаге вывода будет длиннее сентенциальной формы на предыдущем шаге. Напомним, что эта форма грамматики использовалась для доказательства теоремы о разрешимости контекстных языков (теорема 1.1).
Пример 4.6. Пусть дана КС-грамматика с правилами
S ® aBa
B ® A ½ Bc
A ® aA ½ bb.
Правило B ® A можно устранить, воспользовавшись результатами теоремы 4.2, и получить грамматику
S ® aBa
B ® aA ½ bb ½ Bc
A ® aA ½ bb š
КС-грамматика G=(N, S, P, S) называется грамматикой без циклов, если в ней нет выводов A Þ + A для AÎ N. КС-грамматика G называется приведенной, если она без циклов, без аннулирующих правил и без тупиков.
Грамматики с e - правилами и циклами иногда труднее анализировать, чем грамматики без таковых. Кроме того, в любой практической ситуации тупики (бесполезные символы) без необходимости увеличивают объем анализатора. Поэтому для некоторых алгоритмов синтаксического анализа, рассматриваемых во второй части пособия, мы будем требовать, чтобы грамматики, фигурирующие в них, были приведенными. Это требование позволяет рассматривать все КС-языки.
Теорема 4.8. Если L - КС-язык, то L=L(G) для некоторой приведенной КС-грамматики G.
Доказательство. Применить к КС-грамматике, определяющей язык L, эквивалентные преобразования по теоремам 4.5 - 4.7. ҳ