Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Примеры топологической сортировки
|
|
Техническая задача разбивается на ряд подзадач, при этом выполнение одних подзадач должно предшествовать выполнению других подзадач. Топологическая сортировка означает выполнение подзадач в таком порядке, чтобы перед началом выполнения каждой подзадачи все необходимые для этого подзадачи были уже выполнены.
В программе некоторые процедуры могут вызывать другие процедуры. Топологическая сортировка предполагает расположение описаний процедур в таком порядке, чтобы вызываемые процедуры описывались раньше тех, которые их вызывают.
Под топологической сортировкой понимается сортировка элементов, для которых определен частичный порядок, т.е. упорядочивание задано не для всех, а только для некоторых пар элементов.
Предполагается, что существует множество из 3-х элементов a, b и c, которое удовлетворяет трем правилам:
- транзитивность: если a < b и b < c, то a < c;
- асимметричность: если a < b, то не b < a;
- антирефлексивность: невозможность a < a.
Цель топологической сортировки - преобразование частичного порядка в линейный. Графически процесс топологической сортировки показан на рисунках 4 и 5.
Рисунок 4. Исходное множество

Рисунок 5. Результат топологической сортировки
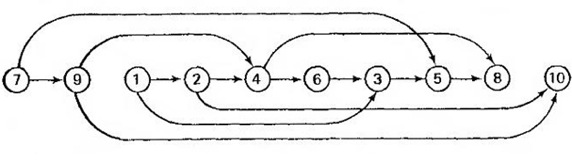
Топологическая сортировка начинается с того, что во множестве выбирается элемент, которому не предшествует никакой другой. Этот элемент помещается в начало списка и исключается из множества. В оставшемся множестве опять выбирается такой же по свойству элемент, и все повторяется до тех пор, пока множество не станет пустым. Для подобного алгоритма потребуются две структуры, первая будет называться лидером (leader), а вторая - ведомой (trailer).
Листинг 2. Структуры для топологической сортировки
| struct trailer{ struct leader * id; struct trailer * next; }; struct leader{ int key; int count; struct leader * next; struct trailer * trail; }; |
Элемент исходного множества, содержащийся в нем только один раз, является лидером, а остальные — ведомыми. Первоначально исходное множество задается в виде списка пар, как показано в листинге 3.
Листинг 3. Исходное множество
| 1 < 22 < 44 < 6 1 < 33 < 5... |
На первом шаге эти пары читаются и создается список лидеров. Затем для каждого лидера формируется свой список ведомых. На платформе Unix есть специальная консольная утилита tsort, которая получает на вход список пар и выдает конечный линейный список.
Листинг 4. Использование утилиты tsort
| $ tsort < < EOF> 3 8> 3 10> 5 11> 7 8> 7 11> 8 9> 11 2> 11 9> 11 10> EOF3571181029 |
В начало
Задача Иосифа Флавия
Иосиф Флавий - это исторический деятель, живший в первом веке нашей эры, с которым была связана одна драматическая история. Об этой истории можно прочесть по > > следующей ссылке< < [https://ru.wikipedia.org/wiki/%D0%97%D0%B0%D0%B4%D0%B0%D1%87%D0%B0_%D0%98%D0%BE%D1%81%D0%B8%D1%84%D0%B0_%D0%A4%D0%BB%D0%B0%D0%B2%D0%B8%D1%8F], но в рамках статьи больший интерес представляет математическая задача, связанная с этой историей. В этой задаче предлагается вычислить, какой элемент останется последним в списке, если из списка последовательно будет удаляться каждый третий элемент, как показано на рисунке 6.
Рисунок 6. Задача Иосифа Флавия

На рисунке 6, если начать отсчет с нулевого индекса, продвигаться по часовой стрелке и уничтожать каждый третий элемент, то останутся только элементы с индексами 1 и 7. Для моделирования этой ситуации можно взять кольцевой связный список или обычный массив. В связном списке удалить элемент гораздо проще, чем найти последний узел, который останется после удаления всех узлов, не удаляя физически элементов из списка.
В представленном алгоритме для решения задачи Иосифа Флавия для поиска последнего «оставшегося в живых» элемента используется двусвязный круговой список. В процессе поиска происходит динамическое удаление элементов из списка и перестройка связей для поддержки целостности списка. Оба варианта решения задачи на языках Си и Python находятся в файлах last_man_standing_task.c и last_man_standing_task.py, упакованных в архив sources.zip, прикрепленный к статье. Реализация алгоритма на языке Python получилась в два раза компактнее, чем на языке Си.
В начало
Использование связных списков в ядре Linux
В ядре Linux применяется особая реализация связных списков, в которой используются специальные алгоритмы для добавления/удаления элементов в список. В листинге 5 показан элемент связного списка, включающий структуру list_head.
Листинг 5. Элемент связного списка, используемого в ядре Linux
| struct mystruct { int data; struct list_head mylist; }; |
Если структуру list_head добавить к любой другой структуре, то эта структура станет частью связного списка. В листинге 6 создаются два элемента связного списка и инициализируются двумя различными способами.
Листинг 6. Два способа инициализации
| struct mystruct first = {.data = 10,.mylist = LIST_HEAD_INIT(first.mylist) }; struct mystruct second; second.data = 20; INIT_LIST_HEAD(& second.mylist); |
Метод LIST_HEAD_INIT, используемый в первом варианте, - это следующий макрос:
| #define LIST_HEAD_INIT(name) { & (name), & (name) } |
В ядре Linux макросы используются вместо обычных функций, так как макросы позволяют сгенерировать более эффективный код, что положительно сказывается на производительности. Во втором варианте используется inline-функция, приведенная в листинге 7.
Листинг 7. Функция для инициализации списка
| static inline void INIT_LIST_HEAD(struct list_head *list){ list-> next = list; list-> prev = list; } |
Как видно из определения, создаваемый список является двусвязным, так как в нем содержатся указатели на следующий и предыдущий элементы. Использование inline-функции вместо обычной также окажет положительное влияние на производительность. Когда компилятор будет генерировать исполняемый код этой функции, то он поместит его в объектном файле непосредственно в то место, где была вызвана эта функция. Благодаря этому не потребуется тратить ресурсы на вызов функции.
Для создания самого списка, также будет использоваться макрос - LIST_HEAD:
| #define LIST_HEAD(name) struct list_head name = LIST_HEAD_INIT(name) |
А для добавления элементов будет использоваться inline-функция list_add, которая служит «оболочкой» для вызова еще одной функции __list_add.
Листинг 8. Функции для добавления элементов в список
| static inline void list_add(struct list_head *new, struct list_head *head) { __list_add(new, head, head-> next); } static inline void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next){ next-> prev = new; new-> next = next; new-> prev = prev; prev-> next = new; } |
Теперь можно добавить элементы в только что созданный список:
| list_add (& first.mylist, & mylinkedlist); list_add (& second.mylist, & mylinkedlist); |
В результате получится связный список, состоящий из 2-х элементов, и указатель на первый элемент в переменной mylinkedlist. Для просмотра содержимого списка или выполнения итерации также используются макросы с целью получения быстрого и эффективного исполняемого кода.
Листинг 9. Макрос для просмотра содержимого списка
| #define list_for_each(pos, head) \ for (pos = (head)-> next; prefetch(pos-> next), pos! = (head); \ pos = pos-> next) |