Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Теоретические основы
|
|
Одной из широко используемых методик кластеризации является разделительная кластеризация (англ.: partitioning clustering) в соответствии с которой для выборки данных, содержащей n записей (объектов), задается число кластеров k, которое должно быть сформировано. Затем алгоритм разбивает все объекты выборки на k разделов(k < n), которые и представляют собой кластеры.
Одним из наиболее простых и эффективных алгоритмов кластеризации является алгоритм k- means(Mac-Queen, 1967) или в русскоязычном варианте k -средних (от англ. mean – среднее значение). Он состоит из четырех шагов.
1. Задается число кластеров k, которое должно быть сформировано из объектов исходной выборки.
2. Случайным образом выбирается k записей исходной выборки, которые будут служить начальными центрами кластеров. Такие начальные точки, из которых потом «вырастает» кластер, называют «семенами» (от англ. seeds – семена, посевы). Каждая такая запись будет представлять собой своего рода «эмбрион» кластера, состоящий только из одного элемента.

Рисунок 1 – графическое представление случайного выбора центров для 3 кластеров (точки A, B, C)
3. Для каждой записи исходной выборки определяется ближайший к ней центр кластера, т.е. вычисляется расстояние между записями и центрами кластеров. Правило, по которому производится вычисление расстояния в многомерном пространстве признаков, называется метрикой. Рассмотрим наиболее часто применяемые метрики.
3.1. Евклидово расстояние (метрика L2). Использует для вычисления расстояний следующее правило:
 ,
,
Где x =(x1, x2, …, xm), y =(y1, y2, …, ym) – наборы (векторы) значений признаков двух записей. Поскольку множество точек, равноудаленных от некоторого центра при использовании евклидовой метрики будет образовывать сферу(или круг в двумерном случае), то и кластеры, полученные с использованием евклидова расстояния, также будут иметь форму, близкую к сферической.
3.2. Расстояние Манхэттена (англ.: Manhattan distance) или метрика L1:

Фактически это кратчайшее расстояние между двумя точками, пройденное по линиям,
параллельным осям координатной системы (рисунок 2). Преимущество метрики L1 заключается в том, что ее использование позволяет снизить влияние аномальных значений на работу алгоритмов. Кластеры, построенные на основе расстояния
Манхэттена, стремятся к кубической форме.

Рисунок 2 - Расстояние Манхэттена (метрика L1)
3.3. Функция отличия (англ: different function) используется как мера расстояния для категориальных признаков. Она задается следующим образом:
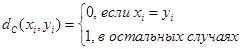 ,
,
где xi и yi – категориальные значения.
4. Производится вычисление центроидов – центров тяжести кластеров. Это делается путем простого определения средних значений каждого признака для всех записей в кластере. Например, если в кластер вошли три записи с наборами признаков (x1, y1), (x2, y2), (x3, y3), то координаты его центроида будут рассчитываться следующим образом:

Затем старый центр кластера смещается в его центроид. На рисунке 2 новые центры тяжести кластеров представлены в виде крестиков. Таким образом, центроиды становятся новыми центрами кластеров для следующей итерации алгоритма.
Шаги 3 и 4 повторяются до тех пор, пока выполнение алгоритма не будет прервано.
Остановка алгоритма производится:
- Когда границы кластеров и расположения центроидов не перестанут изменяться от итерации к итерации, т.е. на каждой итерации в каждом кластере будет оставаться один и тот же набор записей. На практике алгоритм k-meansобычно находит набор
стабильных кластеров за несколько десятков итераций.
- Когда достигнут критерий сходимости. Чаще всего используется критерий суммы квадратов ошибок между центроидом кластера и всеми вошедшими в него записями, т.е.

где  - произвольная точка данных, принадлежащая кластеру Ci, mi – центроид данного кластера. Иными словами, алгоритм остановится тогда, когда ошибка E достигнет достаточно малого значения.
- произвольная точка данных, принадлежащая кластеру Ci, mi – центроид данного кластера. Иными словами, алгоритм остановится тогда, когда ошибка E достигнет достаточно малого значения.

Рисунок 2 – Определение центров тяжести кластеров (центроидов) и новых границ кластеров
Нормализация данных.
Предположим, что у нас есть 2 потребителя с возрастом 37 и 44 лет и доходом в $90, 000 и $62, 000 соответственно. Если мы хотим измерить Евклидово расстояние между точками (37, 90000) и (44, 62000), мы увидим, что в данном случае переменная доход «доминирует» над переменной возраст и ее изменение сильно сказывается на расстоянии. Нам необходима какая-нибудь стратегия для решения данной проблемы, иначе наш анализ даст неверный результат. Решение данной проблемы это приведение наших значений к сравнимым шкалам.
Существует много подходов для нормализации данных. Например, нормализация минимума-максимума. Для данной нормализации используется следующая формула
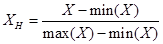 ,
,
где Xн — это нормализованное значение, min(X) и max(X) – минимальная и максимальная координата по всему множеству X.
Пример работы алгоритма k-means, разбивающего объекты на 4 кластера, приведен на рисунке 3. Центры кластеров отмечены знаком «х», каждому кластеру соответствует свой цвет.
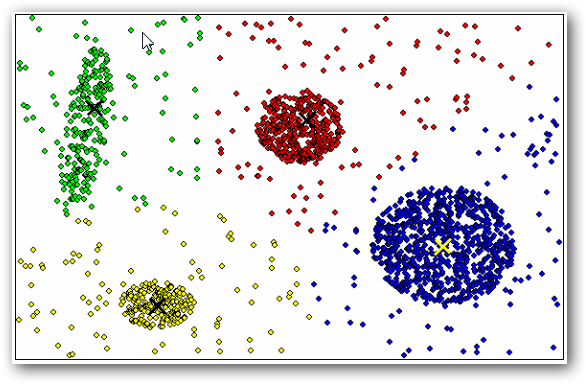
Рисунок 3 - Пример работы алгоритма k-means
Достоинства k-means:
- Умеренные вычислительные затраты, которые растут линейно с увеличением числа записей исходной выборки данных. Вычислительная сложность алгоритма определяется как k x n x l, где k – число кластеров, n – число записей и l – число итераций.
- Результаты его работы не зависят от порядка следования записей в исходной выборке.
Недостатки k-means:
- Отсутствие четких критериев выбора числа кластеров, целевой функции их инициализации и модификации.
- Чувствительность алгоритма к шумам и аномальным значениям в данных, поскольку они способны значительно повлиять на среднее значение, используемое при вычислении положений центроидов. (Чтобы снизить влияние таких факторов, как шумы и аномальные значения, иногда на каждой итерации используют не среднее значение признаков, а их медиану. Данная модификация алгоритма называется k-mediods (k-медиан).