Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Ініціалізація
|
|
Кіровоград – 2016 р.
Мета: Ознайомитися з поняттям інтелектуального агента та одним з методів його навчання – Q-learning
Завдання 1
Відповідно до свого варіанта побудувати математичну модель інтелектуального агента та його зовнішнього середовища:
– записати множину станів інтелектуального агента та цільовий стан;
– зобразити зовнішнє середовище агента у вигляді графа, в якому стани – вузли, а дії – ребра;
– записати матрицю суміжності побудованого графа.
Проілюструвати роботу алгоритму Q-навчання розрахунками без програмної реалізації. Для цього показати 2 спроби агента досягти цільової мети. Перший раз, обираючи маршрут цілком довільним чином (так як пам’ять агента порожня), другий раз – враховуючи здобуту пам’ять агента. Розрахунки повинні містити обчислення винагород за дії агента, значення матриці Q та зображення графа зовнішнього середовища з позначенням шляху агента і змінених значень ваг ребер.

Рисунок 6 – Інтелектуальний агент
Як видно з рисунку 6 маємо 2 входи, 2 виходи, 8 кімнат, початкова та кінцева цілі агента та 13 спроб.
В даній кімнаті станом агента буде перебування його в тій чи іншій кімнаті, або вулиці, а дією - вихід/вхід у ті чи інші двері.
Тобто в агента є 9 можливих станів:
0 стан - перебування на вулиці;
1 стан - перебування у кімнаті №0;
2 стан - перебування у кімнаті №1;
3 стан - перебування у кімнаті №2;
4 стан - перебування у кімнаті №3;
5 стан - перебування у кімнаті №4;
6 стан - перебування у кімнаті №5;
7 стан - перебування у кімнаті №6;
8 стан - перебування у кімнаті №7.
Цільовий стан - 8 стан (перебування в кімнаті 7).
Представимо зовнішнє середовище агента у вигляді графа, в якому стани - вузли, а дії - ребра (рисунок 6.1).
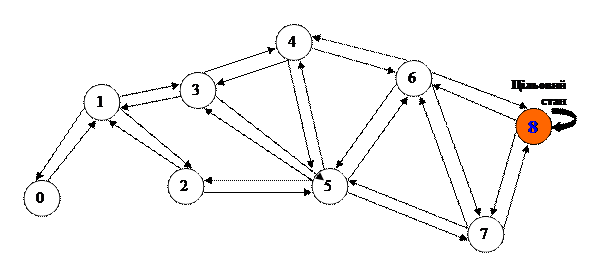
РИСУНОК 6.1 – ЗОВНІШНЄ СЕРЕДОВИЩЕ АГЕНТА
В якій би кімнаті не опинився агент, він повинен знайти вихід до обраної цілі в будівлі кімнати 7. А якщо агент вже знаходиться в кімнаті 7, то повинен залишатися там - тому 8-ма вершина має петлю (рисунок 6.1).
Привласнимо кожному ребру вагу. Ребра, що ведуть до цільового стану, мають одержати вагу 100, всі інші - вагу 0 (рисунок 6.2).

РИСУНОК 6.2 – Вага ребра
Тепер побудуємо матрицю суміжності даного графа (рисунок 6.3). Якщо вершини не зв’язані ребром, ставимо біля них у матриці (-1). Одержана матриця і є R матрицею.
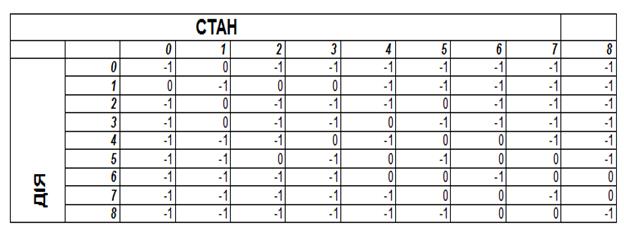
РИСУНОК 6.3 – МАТРИЦЯ СУМІЖНОСТІ І НЕ СУМІЖНОСТІ РЕБЕР
Індекси рядків R матриці вказують на номер стану агента, а індекси стовпчиків - на номер дії.
Розглянемо покроково одну з можливих послідовностей дій агента.
Ініціалізація
1) Ініціалізація матриці R:
R= 
РИСУНОК 6.4 – ІНІЦІАЛІЗАЦІЯ МАТРИЦІ
2) Ініціалізація матриці Q (для наочності припустимо, що пам’ять агента вже містить записи про розташування цільового стану):
Q= 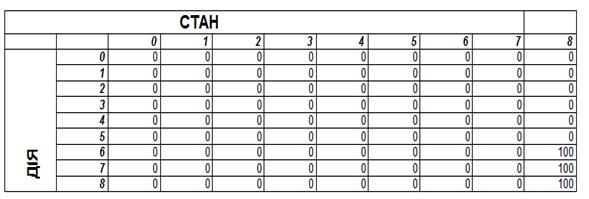
РИСУНОК 6.5 – ІНІЦІАЛІЗАЦІЯ МАТРИЦІ ЦІЛЬОВОГО СТАНУ
3) Ініціалізація параметра швидкості навчання Gamma = 0, 8.
1 крок. Агент випадковим чином опинився у кімнаті №5.

Рисунок 6.6- Агент у кімнаті 5
З матриці R агент дізнається про свої можливі дії. Оскільки агент перебуває в 4 стані, то його можливі дії містяться в 5-му рядку матриці. Зі стану 5 агент може перейти в стани: 2, 3, 4, 6, 7 тобто здійснити дії (5, 2), (5, 3) (5, 4). (5, 6). (5, 7). Оскільки агент ще не знає, який стан наблизить його до цільового стану, він обирає дію випадково.
Припустимо, що агент випадковим чином обрав дію (5, 2).
R= 
РИСУНОК 6.7 – ЗМІНА СТАНУ

Рисунок 6.8 – обрання дії 2
2 крок. На другому кроці агент обирає наступну дію та одержує винагороду за попередню дію.
Зараз агент перебуває в 2 стані. З даного стану він може перейти в стан 1 та стан 5. Отже агент вибирає перехід у стан 1, тобто дію (2, 1).
R= 
РИСУНОК 6.9 – Знаходження у стані 2
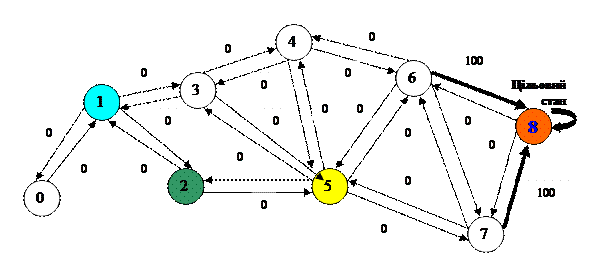
Рисунок 6.10 – ОБРАННЯ СТАНУ 1
Винагорода за попередню дію (здійснену на кроці 1) обчислюється по наступній формулі:
Q[5, 2] = R[5, 2] + 0, 8 * MAX(Q[2, 5], Q [2, 1]) = 0 + 0, 8 * (0*0) = 0
В матрицю Q, тобто пам’ять агента записується інформація про корисність дії (5, 2).
Q= 
РИСУНОК 6.11 – Запис про корисність дії

Рисунок 6.12 – Зображення користносты дыъ
3 крок. На другому кроці агент знову обирає наступну дію та одержує винагороду за попередню дію.
Агент перебуває в 1 стані. Можливі дії - (1, 0), (1, 2), (1, 3). Агент обирає дію (1, 3).
Винагорода за попередню дію (здійснену на кроці 2) обчислюється по наступній формулі:
Q[2, 1] = R[2, 1] + 0, 8 * MAX(Q[1, 0], Q [1, 2], Q [1, 3]) = 0 + 0, 8 * 0 = 0

РИСУНОК 6.13 – Матриця 2.1

РИСУНОК 6.14 – Обрання 3 дії
4 крок. На 3 кроці агент знову обирає наступну дію та одержує винагороду за попередню дію.
Агент перебуває в 3 стані. Можливі дії - (3, 1), (3, 4), (3, 5). Агент обирає дію (3, 4).
Винагорода за попередню дію (здійснену на кроці 3) обчислюється по наступній формулі:
Q[1, 3] = R[1, 3] + 0, 8 * MAX(Q[1, 0], Q [1, 2], Q [1, 3]) = 0 + 0, 8 * 0 = 0

РИСУНОК 6.15 – МАТРИЦЯ 1.3

РИСУНОК 6.16 – Обрання 4 дії
5 крок. На 4 кроці агент знову обирає наступну дію та одержує винагороду за попередню дію.
Агент перебуває в 4 стані. Можливі дії - (4, 3), (4, 5), (4, 6). Агент обирає дію (4, 6).
Винагорода за попередню дію (здійснену на кроці 4) обчислюється по наступній формулі:
Q[3, 4] = R[3, 4] + 0, 8 * MAX(Q[4, 3], Q [4, 5], Q [4, 6]) = 0 + 0, 8 * 0 = 0

РИСУНОК 6.17 – матриця 3.4

РИСУНОК 6.18 – обрання 6 дії
6 крок. На 5 кроці агент знову обирає наступну дію та одержує винагороду за попередню дію.
Агент перебуває в 6 стані. Оскільки стан 6 відмічений вагою 100 то агент розуміє, що даний стан є цільовим. Отже агент видирає перехід у цільовий стан, тобто дію 6.8 Можливі дії - (6, 4), (6, 5), (6, 7). (6.8)
Винагорода за попередню дію (здійснену на кроці 4) обчислюється по наступній формулі:
Q[4, 6] = R[4, 6] + 0, 8 * MAX(Q[6, 4], Q [6, 5], Q [6, 7], Q [6, 8]) = 0 + 0, 8 * 0*0*0*100 = 80

РИСУНОК 6.19 – Матриця 4.6

РИСУНОК 6.20 – обрання 8 дії
7 крок. На 6 кроці агент знову обирає наступну дію та одержує винагороду за попередню дію.
Агент перебуває в 8 стані. Можливі дії - (8, 6), (8, 7) агент обирає дію 8.7
Винагорода за попередню дію (здійснену на кроці 5) обчислюється по наступній формулі:
Q[6, 8] = R[6, 8] + 0, 8 * MAX(Q[8, 6], Q [8, 7]) = 100+0, 8*(0*100)= 180

РИСУНОК 6.21 – Матриця 6.8

РИСУНОК 6.22 – Обрання 7 дії
8 крок. На 7 кроці агент знову обирає наступну дію та одержує винагороду за попередню дію.
Агент перебуває в 7 стані. Можливі дії - (7, 5), (7, 6) (7.8) агент обирає дію 7.8 Винагорода за попередню дію (здійснену на кроці 6) обчислюється по наступній формулі:
Q[8, 7] = R[8, 7] + 0, 8 * MAX(Q[7, 5], Q [7, 6] [7, 8]) = 100+0, 8*(0*0*100)= 180

РИСУНОК 6.23 – МАТРИЦЯ 8.7

РИСУНОК 6.24 – ОБРАНН9 8 ДІЇ
9 крок. На 8 кроці Агент перебуває в 8 стані і завершує свої дії отриманням ковбаси) Можливі дії - (8, 6), (8, 7) Винагорода за попередню дію (здійснену на кроці 6) обчислюється по наступній формулі:
Q[8, 8] = R[8, 8] + 0, 8 * MAX(Q[8, 6], Q [8, 7]) = 100+0, 8*(0*0*100)= 180
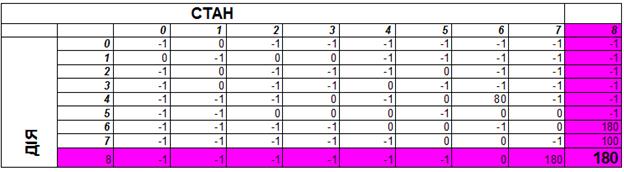
РИСУНОК 6.25 – матриця 8.8
РИСУНОК 6.26 – ОТРИМАННЯ КОТОМ КОВБАСИ
Тепер у пам’яті агента міститься інформація про корисність дій (4, 6), (6, 8) та (7, 8), (8, 8).
Продемонструю кінцеву матрицю суміжності та кінцевий граф шляху

РИСУНОК 6.27 – КІНЦЕВА МАТРИЦЯ ОБЧИСЛЕНЬ
РИСУНОК 6.28 – КІНЦЕВИЙ ГРАФ ДІЙ