Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Общая схема построения алгоритмов метода группового учета аргументов (МГУА).
|
|
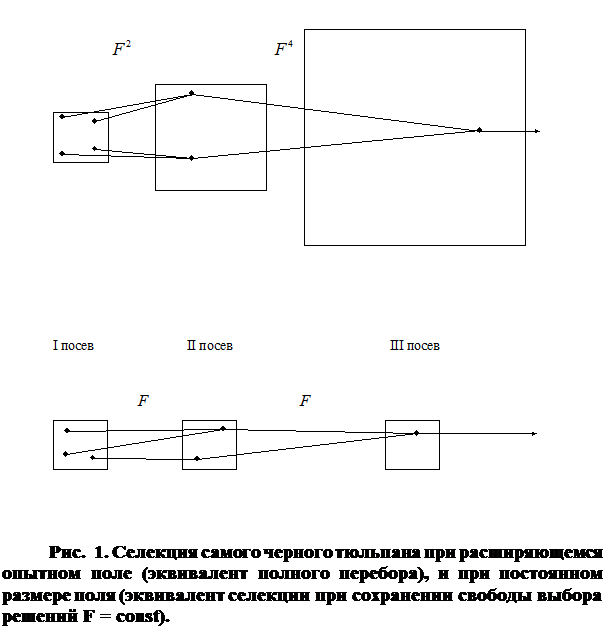 Заимствование алгоритмов переработки информации у природы является одной из основных идей кибернетики. " Гипотеза селекции" утверждает, что алгоритм массовой селекции растений или животных является оптимальным алгоритмом переработки информации в сложных задачах. При массовой селекции высевается некоторое количество семян. В результате опыления образуются сложные наследственные комбинации. Селекционеры выбирают некоторую часть растений, у которых интересующее их свойство выражено больше всего (эвристический критерий). Семена этих растений собирают и снова высевают для образования новых, еще более сложных комбинаций. Через несколько поколений селекция останавливается и ее результат является оптимальным. Если чрезмерно продолжать селекцию, то наступит «инцухт» — вырождение растений. Существует оптимальное число поколений и оптимальное количество семян, отбираемых в каждом из них.
Заимствование алгоритмов переработки информации у природы является одной из основных идей кибернетики. " Гипотеза селекции" утверждает, что алгоритм массовой селекции растений или животных является оптимальным алгоритмом переработки информации в сложных задачах. При массовой селекции высевается некоторое количество семян. В результате опыления образуются сложные наследственные комбинации. Селекционеры выбирают некоторую часть растений, у которых интересующее их свойство выражено больше всего (эвристический критерий). Семена этих растений собирают и снова высевают для образования новых, еще более сложных комбинаций. Через несколько поколений селекция останавливается и ее результат является оптимальным. Если чрезмерно продолжать селекцию, то наступит «инцухт» — вырождение растений. Существует оптимальное число поколений и оптимальное количество семян, отбираемых в каждом из них.
Алгоритмы МГУА воспроизводят схему массовой селекции [5], показанной на Рис. 6. В них есть генераторы усложняющихся из ряда в ряд комбинаций и пороговые самоотборы лучших из них. Так называемое «полное» описание объекта
j = f(x1, x2, x3, ¼, xm),
где f — некоторая элементарная функция, например степенной полином, заменяется несколькими рядами " частных" описаний:
1-ряд селекции: y1= f(x1x2), y2= f(x1x3),..., ys= f(xm-1xm),
2-ряд селекции: z1= f(y1y2), z2= f(y1y2),..., zp= f(ys-1ys), где s=c2, p=cs2 и т.д.
Входные аргументы и промежуточные переменные сопрягаются попарно, и сложность комбинаций на каждом ряду обработки информации возрастает (как при массовой селекции), пока не будет получена единственная модель оптимальной сложности.
Каждое частное описание является функцией только двух аргументов. Поэтому его коэффициенты легко определить по данным обучающей последовательности при малом числе узлов интерполяции [4]. Исключая промежуточные переменные (если это удается), можно получить " аналог" полного описания. Математика не запрещает обе эти операции. Например, по десяти узлам интерполяции можно получить в результате оценки коэффициентов полинома сотой степени и т. д.
Из ряда в ряд селекции пропускается только некоторое количество самых регулярных переменных. Степень регулярности оценивается по величине среднеквадратичной ошибки (средней для всех выбираемых в каждом поколении переменных или для одной самой точной переменой) на отдельной проверочной последовательности данных. Иногда в качестве показателя регулярности используется коэффициент корреляции.
Ряды селекции наращиваются до тех пор, пока регулярность повышается. Как только достигнут минимум ошибки, селекцию, во избежание " инцухта", следует остановить. Практически рекомендуется остановить селекцию даже несколько раньше достижения полного минимума, как только ошибка начинает падать слишком медленно. Это приводит к более простым и более достоверным уравнениям.