Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Структуры данных
|
|
MЕТОДИЧЕСКОЕ ПОСОБИЕ
Для выполнения пробной работы на практике
По получению рабочей специальности
«Оператор ЭВМ»
(нетипизированные файлы, кольцевые списки)
по специальности 230105
«Программное обеспечение вычислительной техники и автоматизированных систем»
Рассмотрено на заседании
ПЦК специальности 230105
ППЦК Н.А.Жилкина
Разработал Л.Г.Эллер
Содержание
1 Введение …………………….………………………………………………………. 3
2 Задание для пробной работы …………………………………………………….... 10
3 Описание и структура программы ………………………………………………... 13
3.1 Описание и структура модуля mType …………………………………...…. 20
3.2 Описание и структура модуля StrData ………………………………..…….. 22
3.3 Описание и структура модуля JOB …………………………………………. 23
3.4 Описание и структура модуля Spisok ……………………………………….. 24
3.5 Описание и структура модуля Data …………………………………………. 25
3.6 Описание и структура модуля Docum (для курсовой работы) ……………. 27
Список литературы ………………………………………………………………….. 28
ВВЕДЕНИЕ
Практика для получения рабочей специальности «Оператор ЭВМ» проводится на учебно-вычислительном центре.
Время прохождения: 3 курс (6 семестр).
Продолжительность: 4 недели (144 часа).
Целью практики является обучение применению полученных знаний и умений при решении комплексных задач, связанных со сферой профессиональной деятельности будущих специалистов.
Результатом практики является выполнение, оформление и защита пробной работы.
Темой пробной работы является создание и ведение базы данных, определяемой вариантом задания.
База данных – это, собственно, хранилище информации. Для создания и ведения базы данных необходимо составить обслуживающие программы, позволяющие выполнять типичные работы с базой данных:
- создание базы данных;
- редактирование базы данных:
Ø добавление новых записей в базу;
Ø удаление записей из базы;
Ø корректировка значений, содержащихся в полях записей
- манипулирование базой данных:
Ø просмотр всей базы;
Ø сортировка записей БД по определенному ключу и так далее
- поиск в базе данных.
Совокупность базы данных и обслуживающих базу программ формируют информационно-поисковую систему или автоматизированную систему управления базой данных.
Структуры данных
Для хранения данных базы используются файлы. Поскольку при работе с БД используются записи различных структур, для универсальности программы рационально использовать бестиповые (нетипизированные) файлы.
Нетипизированные файлы объявляются как файловые переменные типа File и отличаются тем, что для них не указан тип компонентов. Отсутствие типа делает эти файлы, с одной стороны, совместимыми с любыми другими файлами, а с другой – позволяет организовать высокоскоростной обмен данными между диском и памятью.
Файловую переменную необходимо связать с конкретным физическим именем файла, используя процедуру Assign. При о ткрытии файла процедурой Reset или Rewrite можно указать длину записи нетипизированного файла в байтах. Если не будет явно указана длина записи, по умолчанию устанавливается размер буфера передачи данных равным 128 байтам.
Для явного задания буфера передачи данных надо при открытии файла воспользоваться расширенной записью процедур:
Reset (var F: file; sizebuf: word);
или
Rewrite (var F: file; sizebuf: word);
Параметр sizebuf задаёт число байтов, считываемых из файла за одно обращение к нему или записываемых в него. Максимальный размер блока не может превышать 64 килобайт. Минимальный блок, который может быть записан или прочитан из файла – 1 байт.
При работе с нетипизированными файлами могут применяться все процедуры и функции, доступные типизированным файлам, за исключением Read и Write, которые заменяются высокоскоростными процедурами BlockRead и BlockWrite.
Для обращения к этим процедурам используются следующие конструкции:
- для чтения BlockRead (< файловая пер.>, < буфер>, < N> {, < NN> });
- для записи BlockWrite (< файловая пер.>, < буфер>, < N> {, < NN> });
где
< файловая пер.> – файловая переменная;
< буфер> – буфер: имя переменной, которая будет участвовать в обмене данными;
< N> – количество записей, которые должны быть переданы за одно обращение;
< NN> – необязательный параметр, содержащий при выходе из процедуры количество фактически обработанных записей.
За одно обращение к соответствующей процедуре может быть передано
(N * < размер буфера>) байтов, но не более 64 килобайт.
Если операция чтения или записи прошла удачно, то значение NN должно быть равно соответствующему значению N. В противном случае произошла ошибка ввода-вывода или обнаружен конец файла при чтении. Таким образом, эти параметры могут быть использованы для контроля правильности ввода-вывода.
Пример использования:
………………
type pzap = ^tzap;
tzap = record
pole1: …;
pole2: …;
pole3: …;
end;
Var p: pzap;
x: tzap;
sizebuf: word;
f: file;
………………
assign(f, ’f.dat’); { связать файл с файловой переменной }
sizebuf: =sizeof (p^); { определить размер данных типа zap }
new(p); readzap(p); { ввести данные в p^ }
rewrite(f, sizebuf); { открыть файл для записи }
blockwrite(f, p^, 1); { записать данные p^ в файл }
………………
сlose(f); { закрыть файл }
………………
reset(f, sizebuf); { открыть файл для чтения }
blockread(f, x, 1); { прочитать данные из файла }
сlose(f); { закрыть файл }
………………
Функция sizeof возвращает длину в байтах указанного объекта sizeof (А), где А – имя переменной, типа или функции.
При обработке базы данных для увеличения быстродействия выполнения программы и рационального использования памяти следует применять списковые динамические структуры (разновидность списка определяется заданием, для примера рассматривается двунаправленное кольцо).
Для того чтобы список не зависел от данных информационной части, целесообразно применять указатели на данные. В целях гибкости списка применяется структура списка, приведенная на рисунке 1.
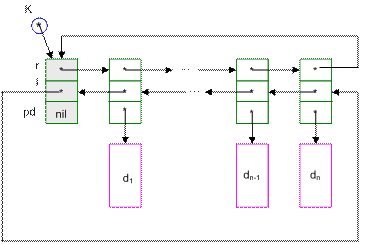
Рисунок 1 – Структура двунаправленного кольца
Описание структуры объектов списка:
type pObj = ^Obj;
Obj = record
r: pObj; { указатель на правый объект }
l: pObj; { указатель на левый объект }
pd: pointer; { указатель на данные }
end;
var k: pObj; { указатель на начало кольца }
Предварительно список должен быть проинициализирован. Инициализация списка приведена на рисунке 2
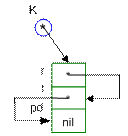
Рисунок 2 – Инициализация двунаправленного кольца
В Турбо Паскале можно объявлять указатель и не связывать его при этом с каким-либо конкретным типом данных.
Для этого служит стандартный тип Pointer. Указатели такого типа называются нетипизированными. Поскольку нетипизированные указатели не связаны с конкретным типом, с их помощью удобно размещать данные, структура и тип которых меняются в ходе работы программы.
Для дальнейшей работы с данными, необходимо типизированному указателю присвоить значение нетипизированного.
Пример использования:
procedure write_zap(p: pointer);
var pz: pzap;
begin
pz: =p;
writeln(pz^.pole1, pz^.pole2, pz^.pole3); { вывод полей записи }
end;
procedure OutSp(k: pObj);
var t: pObj;
begin
t: =k^.r;
while t< > k do
begin
write_zap(t^.pd);
t: =t^.r;
end;
end;
При резервировании места в динамической памяти используется процедура new, параметром которого может быть только типизированный указатель.
Для работы с нетипизированными указателями используются процедуры:
1) GetMem (var p: pointer; size: word); – отводит в динамической памяти место в size байт и присваивает начальный адрес выделенной памяти указателю p.
2) FreeMem (var p: pointer; size: word); – освобождает size байт в динамической памяти, начиная с адреса, содержащегося в указателе p.