Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Построение модели
|
|
Основываясь на модели Мелитца, был проведен эконометрический анализ в пакете Stata13.
Цель анализа: проверить, какие факторы наиболее значимы при оценивании благосостояния страны.
Для анализа были найдены и составлены панельные данные по 28 странам Евросоюза в период с 2004 по 2012 года.[11]
Было принято решение взять именно панельные данные в связи с тем, что они позволяют учитывать и анализировать индивидуальные отличия между экономическими единицами, что нельзя сделать в рамках стандартных регрессионных моделей.
Зависимая переменная:
hdi – индекс человеческого развития
Проверяемые переменные:
itq – внешнеторговая квота (%)
population – численность населения (млн.чел.)
unemplrate – уровень безработных (%)
inflrate – уровень инфляции (%)
fdi – прямые зарубежных инвестиций (млрд. долл. США)
Вспомогательные переменные:
сountry – страны Евросоюза с числовом выражении от 1 до 28
year – рассматриваемый период в числовом выражении от 2004 до 2014
exp – объем экспорта (млрд. долл. США)
imp – объем импорта (млрд. долл. США)
pppgdp – ВВП на душу населения по ППС (млрд. долл. США)
seg – сегмент стран (i, где i=1, 2, 3)
Всего: 308 наблюдений по каждой из переменных

В таблице представлены основные статистические показатели: количество наблюдаемых эффектов; среднее значение; стандартное отклонение; минимальное и максимальное значения.
Составим простую линейную регрессию:

Согласно полученным результатам, регрессия значима и все оценки состоятельны. Качество подгонки модели к наблюдаемым переменным, между тем, не очень хорошее (Adj R2= 0, 423).
Чтобы улучшить качество подгонки и избежать ассиметрии, перейдем к логарифмической линейной регрессии. Для этого сгенерируем новые переменные и построим регрессионную модель с ними:
Новые переменные:
lhdi =log(hdi)
litq =log(itq)
lpop =log(population)
lun =log(unemplrate)
linf =log(inflrate)
fdi =log(fdi)
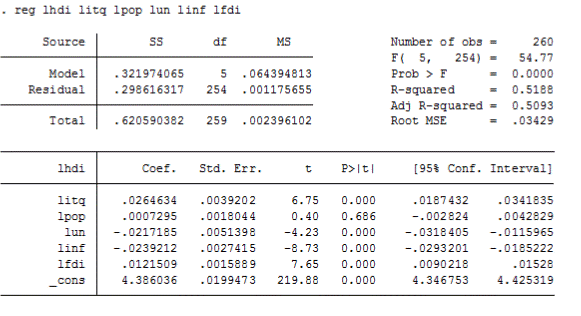
Регрессия значима и качество подгонки стало лучше (0, 5093). Но такая переменная, отвечающая за численность населения, стала незначимой.
Проверим модель на гетероскедастичность. Для этого используем тест Уайта:
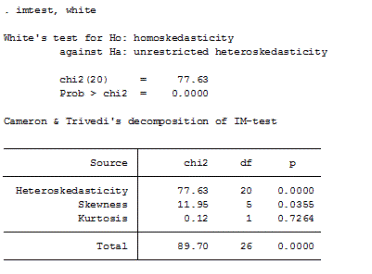
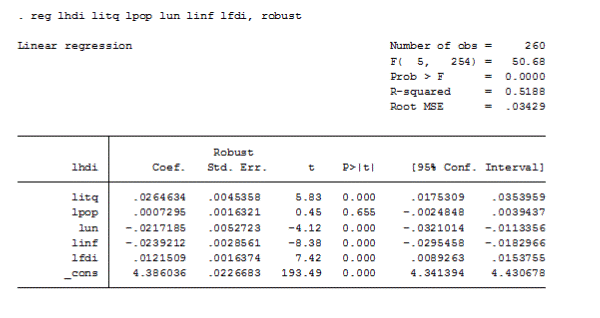
В нашей модели присутствует гетероскедастичность. В связи с этим, оценки по методу наименьших квадратов хоть и остаются линейными несмещенными и состоятельными, но перестают быть самыми точными. Как следствие, стандартные ошибки коэффициентов, выявленные в предположении о нулевой гипотезе (гомоскедастичности), будут занижены. Значит, нужно пересчитать стандартные ошибки:
Далее построим модели с фиксированными индивидуальными эффектами (FE) и с переменными (RE).
. tis year
. iis country

Регрессия FE в целом значима. Корреляция между X и u допустима, так как это проявление гибкости модели с детерминированными эффектами. Поэтому делаем вывод, что оценки значимы. Все переменные вариабельные по времени, значит, их коэффициенты можно оценить. Также, регрессия FE говорит о том, что полученные оценки эффективны и качество подгонки довольно хорошее (0, 524).
Построим модель со случайными индивидуальными эффектами:
Регрессия RE, в целом, значима. О качестве подгонки в модели со случайными эффектами говорит значение критерия Вальда (203, 3) – не очень высокое. Переменные некоррелированны с ненаблюдаемыми случайными эффектами (corr=0), следовательно, оценки состоятельные. Значения коэффициентов отличны от модели FE.
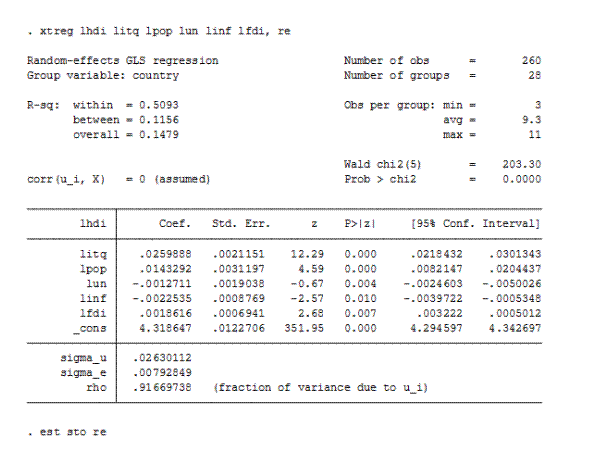
Построив 3 регрессии (сквозная, FE и RE), нужно выбрать наиболее адекватную модель.
Во-первых, между сквозной моделью и с фиксированными индивидуальными эффектами, выберем модель FE, используя тест Вальда (нижняя строка в модели FE; вероятность меньше 0, 05; отвергаем нулевую гипотезу).
Во-вторых, сравним модель RE с моделью простой регрессии, используя тест Бройша-Пагана:

Так как вероятность меньше 0, 05, отвергаем нулевую гипотезу. следовательно, модель RE будет лучше описывать данные, нежели модель сквозной регрессии.
И, в-третьих, для сравнения модели FE и RE, проведем тест Хаусмана:

Так как вероятность меньше 0, 05, нулевая гипотеза отвергается. Значит, модель с фиксированными индивидуальными эффектами лучше подходит для описания данной модели.
Так как индекс человеческого развития отражает благосостояние страны, то можно сделать некоторые выводы: при увеличении благосостояния страны на 1%, на 2, 5% увеличивается внешнеторговая квота; на 1, 6% увеличивается численность населения; на 0, 2% снижается безработица и на 0, 14% - инфляция; приток зарубежных инвестиций увеличивается на 0, 22%.
Наибольшее значение для данной модели имеет переменная внешнеторговой квоты, отвечающая за открытость экономики. Следовательно, в ходе эконометрического анализа, подтвердилось предположение о том, что чем выше уровень открытости экономики в стране, тем выше уровень благосостояния людей.
[1]Статья Ronald F.Inglehart, Svetlana Borinskaya, Anna Cotter, Jaanus Harro, Ronald C. Inglehart, Eduard Ponarin, Christian Welzel«GENES, SECURITY, TOLERANCE AND HAPPINESS”
[2]Интернет-ресурс https://www.prosperity.com/
[3] Интернет-ресурс https://www.socialprogressimperative.org/
[4]СтатьяRonald F.Inglehart, Svetlana Borinskaya, Anna Cotter, Jaanus Harro, Ronald C. Inglehart, Eduard Ponarin, Christian Welzel «GENES, SECURITY, TOLERANCE AND HAPPINESS”
[5] Интернет-ресурс статистических данных www.ereport.ru
[6] Данные https://ec.europa.eu/eurostat
[7] Интернет-портал https://www.gazeta.ru Статья «Европа накормит весь мир» от 25.06.2014
[8] Данные https://ec.europa.eu/eurostat
[9]Данныеhttps://ec.europa.eu/eurostat статья «Energy production and import»
[10]The EEAG Report 2015 (стр. 31-51)
[11] Были использованы базы данныхEurostat и Unctadstat