Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Алгоритмы работы систем распознавание образов, речи.
|
|
Вопросом распознавания образов и речи занимается такая часть ИИ, как интеллектуальный анализ данных. Особое развитие получили алгоритмы распознавания при сканировании сетчатки глаза, отпечатков пальцев, сенсорный ввод и контроль данных.
Существенный вклад в разработку методов внесли российские ученные – М.Бонгард (программа «Кора»), В.Финн(JSM-метод), Н.Ихватенко(МГУА).
До настоящего момента классическим инструментом получения знаний на основе анализа данных являлась математическая статистика. Математическая статистика оперирует усредненными величинами, поэтому реальное представление о данных получить трудно (например: в статистике рассматривается средняя высота зданий). ИАД – основан на поиске в данных скрытых закономерностей, т.е. извлечения информации, которая может называться знаниями.
ИАД – методы позволяют извлекать из «скрытых» данных ранее неизвестные зависимости между параметрами объектов и закономерности поведения классов объектов.
Методы ИАД позволяют оценивать как количественные, так и качественные стороны данных.
В основу современной технологии ИАД положена концепция шаблонов, отражающих многоаспектные отношения между данными. Шаблоны могут быть выражены компактно и в понятной для человека форме. Поиск шаблонов производится методами неограниченными рамками предложений, а структуре выборке.
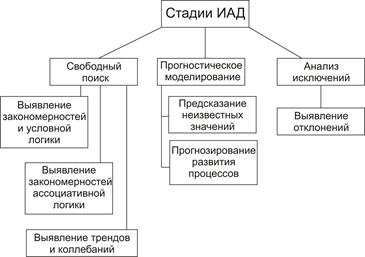
В общем случае процесс ИАД состоит из 3-х стадий:
1. поиск закономерностей, и выявление (свободный поиск).
2. использование выявленных закономерностей для предсказания неизвестных значений (прогнозирование или прогностическое моделирование)
3. анализ исключений (для выявления аналогий в полученных закономерностях)
· 1. Обработка речи начинается с оценки качества речевого сигнала. На этом этапе определяется уровень помех и искажений.
· 2. Результат оценки поступает в модуль акустической адаптации, который управляет модулем расчета параметров речи, необходимых для распознавания.
· 3. В сигнале выделяются участки, содержащие речь, и происходит оценка параметров речи. Происходит выделение фонетических и просодических вероятностных характеристик для синтаксического, семантического и прагматического анализа. (Оценка информации о части речи, форме слова и статистические связи между словами.)
· 4. Далее параметры речи поступают в основной блок системы распознавания — декодер. Это компонент, который сопоставляет входной речевой поток с информацией, хранящейся в акустических и языковых моделях, и определяет наиболее вероятную последовательность слов, которая и является конечным результатом распознавания.