Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Интерпретация коэффициентов уравнения множественной регрессии.
|
|
Можно заметить, что коэффициент при х1 в полученном уравнении отличается от аналогичного коэффициента в уравнении парной регрессии.
Это связано с тем, что коэффициент при независимой переменной в уравнении простой регрессии всегда отличается от коэффициента при соответствующей переменной в уравнении множественной регрессии, так как в последнем исключено влияние всех других учтенных в данном уравнении признаков.
Коэффициенты уравнения множественной регрессии поэтому называются частными или чистыми коэффициентами регрессии.
Частный коэффициент множественной регрессии при х1 показывает, что с увеличением посева на душу на 1 дес. и при фиксированной урожайности сбор хлеба на душу населения возрастает в среднем на 28, 2 пуда. Частный коэффициент при x2 показывает, что при фиксированном посеве на душу увеличение урожая на единицу, т. е. на 1 пуд с десятины, вызывает в среднем увеличение сбора хлеба на душу на 0, 36 пуда. Отсюда можно сделать вывод, что увеличение сбора хлеба в черноземных губерниях России идет, в основном, за счет расширения посева и в значительно меньшей степени—за счет повышения урожайности, т. е. экстенсивная форма развития зернового хозяйства является господствующей.
Введение переменной х2 в уравнение позволяет уточнить коэффициент при х1. Конкретно, коэффициент оказался выше (28, 2 против 24, 6), когда в изучаемой связи вычленилось влияние урожайности на сбор хлеба.
Однако выводы, полученные в результате анализа коэффициентов регрессии, не являются пока корректными, поскольку, во-первых, не учтена разная масштабность факторов, во-вторых, не выяснен вопрос о значимости коэффициента a2.
Величина коэффициентов регрессии изменяется в зависимости от единиц измерения, в которых представлены переменные. Если переменные выражены в разном масштабе измерения, то соответствующие им коэффициенты становятся несравнимыми. Для достижения сопоставимости коэффициенты регрессии исходного уравнения стандартизуют, взяв вместо исходных переменных их отношения к собственным средним квадратическим отклонениям. Тогда уравнение (3.4) приобретает вид
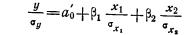
Сравнивая полученное уравнение с уравнением (3.4), можно определить стандартизованные частные коэффициенты уравнения, или так называемые бета-коэффициенты.
Вычислив бета-коэффициенты для уравнения, полученного в примере, получаем:
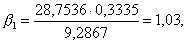
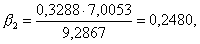
Отсюда мы видим, что вывод о преобладании в черноземной полосе России экстенсивной формы развития хозяйства над интенсивной остается в силе, так как β 1 значительно больше, чем β 2.
3й учебный вопрос. Проблема отбора факторов для включения в модель
Мы должны убедиться, что включение дополнительного фактора действительно позволило более точно описать реальную статистическую зависимость.
Рассчитаем с этой целью индекс детерминации и ошибку аппроксимации для построенного уравнения множественной регрессии.
Построим вспомогательную таблицу для расчета (табл. 3.3)
Таблица 3.3
| №/№ | Исходные данные | Вспомогательные расчеты | ||||||||
| y | x1 | x2 | y (x) | Расчет ошибки(s) | Расчет дисперсии y | Расчет дисперсии yx | ||||
| y - yx | (y - yx)2 | y-yср | (y-yср)2 | yx-yср | (yx-yср x)2 | |||||
| 48, 01 | 0, 91 | 46, 08 | 41, 22 | 6, 79 | 46, 13 | 6, 30 | 39, 64 | -0, 50 | 0, 25 | |
| 38, 18 | 0, 76 | 45, 18 | 36, 67 | 1, 51 | 2, 28 | -3, 53 | 12, 49 | -5, 04 | 25, 44 | |
| 38, 7 | 0, 82 | 41, 76 | 37, 14 | 1, 56 | 2, 42 | -3, 01 | 9, 09 | -4, 57 | 20, 90 | |
| 46, 72 | 0, 88 | 50, 94 | 42, 10 | 4, 62 | 21, 30 | 5, 01 | 25, 06 | 0, 39 | 0, 15 | |
| 41, 58 | 0, 88 | 43, 54 | 39, 47 | 2, 11 | 4, 46 | -0, 13 | 0, 02 | -2, 25 | 5, 05 | |
| 36, 89 | 0, 89 | 38, 8 | 38, 06 | -1, 17 | 1, 37 | -4, 82 | 23, 27 | -3, 65 | 13, 35 | |
| 34, 54 | 0, 87 | 39, 22 | 37, 65 | -3, 11 | 9, 65 | -7, 17 | 51, 47 | -4, 07 | 16, 55 | |
| 42, 86 | 0, 94 | 42, 74 | 40, 87 | 1, 99 | 3, 95 | 1, 15 | 1, 31 | -0, 84 | 0, 71 | |
| 38, 97 | 0, 91 | 41, 2 | 39, 48 | -0, 51 | 0, 26 | -2, 74 | 7, 53 | -2, 24 | 5, 00 | |
| 43, 22 | 1, 07 | 39, 35 | 43, 33 | -0, 11 | 0, 01 | 1, 51 | 2, 27 | 1, 61 | 2, 60 | |
| 28, 19 | 0, 69 | 34, 38 | 30, 85 | -2, 66 | 7, 07 | -13, 52 | 182, 91 | -10, 86 | 118, 04 | |
| 38, 65 | 0, 74 | 48, 98 | 37, 46 | 1, 19 | 1, 41 | -3, 06 | 9, 39 | -4, 25 | 18, 09 | |
| 36, 26 | 0, 9 | 40, 06 | 38, 79 | -2, 53 | 6, 41 | -5, 45 | 29, 75 | -2, 92 | 8, 55 | |
| 32, 07 | 0, 52 | 57, 91 | 34, 44 | -2, 37 | 5, 64 | -9, 64 | 93, 01 | -7, 27 | 52, 84 | |
| 32, 83 | 0, 66 | 43, 86 | 33, 38 | -0, 55 | 0, 31 | -8, 88 | 78, 93 | -8, 33 | 69, 42 | |
| 35, 16 | 0, 58 | 58, 62 | 36, 39 | -1, 23 | 1, 51 | -6, 55 | 42, 96 | -5, 33 | 28, 36 | |
| 44, 56 | 0, 99 | 44, 39 | 42, 87 | 1, 69 | 2, 86 | 2, 85 | 8, 10 | 1, 16 | 1, 34 | |
| 59, 16 | 1, 63 | 35, 77 | 57, 83 | 1, 33 | 1, 76 | 17, 45 | 304, 35 | 16, 12 | 259, 77 | |
| 67, 99 | 1, 95 | 35, 96 | 66, 92 | 1, 07 | 1, 15 | 26, 28 | 690, 41 | 25, 20 | 635, 14 | |
| 53, 73 | 1, 27 | 40, 99 | 49, 55 | 4, 18 | 17, 49 | 12, 02 | 144, 38 | 7, 83 | 61, 37 | |
| 52, 39 | 1, 55 | 33, 05 | 54, 61 | -2, 22 | 4, 92 | 10, 68 | 113, 97 | 12, 89 | 166, 25 | |
| 36, 1 | 1, 15 | 30, 68 | 42, 49 | -6, 39 | 40, 87 | -5, 61 | 31, 52 | 0, 78 | 0, 61 | |
| 32, 67 | 0, 94 | 34, 26 | 37, 85 | -5, 18 | 26, 85 | -9, 04 | 81, 80 | -3, 86 | 14, 92 | |
| Σ | 959, 43 | 22, 5 | 967, 7 | 959, 43 | 0, 000 | 210, 07 | 0, 000 | 1983, 62 | 0, 000 | 1524, 69 |
Расчетные значения y(x) определяются на основе построенного уравнения регрессии, то есть параметры a1 = 28, 18 и a2 = 0, 36 последовательно умножаются на значения переменных x1 и x2, эти произведения складываются и к ним прибавляется свободный член уравнения a0 = - 0, 85:
- 0, 85 + 28, 18*0, 91 + 0, 36*46, 08 = 41, 22 и т.д.
В таблице 3.3. средние значения (yср и yxср ) фактических и расчетных данных результативной переменной совпадают (так как равны суммы фактических и расчетных значений: 959, 43). То есть yср= yxср= 959, 43/23 = 41, 71. Для расчета ошибки аппроксимации находятся квадраты разностей расчетных и фактических значений, а для расчета дисперсий находятся квадраты разностей фактических значений и их средней величины 41, 71, а также квадраты разностей расчетных значений и той же самой средней величины 41, 71. Затем находятся суммы в итоговой строке таблицы.
В результате ошибка аппроксимации находится как квадратный корень из величины 210, 07, деленной на 23 (общее число значений), дисперсия фактических значений рассчитывается путем деления величины 1983, 62 на 23, а дисперсия расчетных значений – путем деления величины 1524, 69 на 23.
Можно убедиться, что значения индекса детерминации и ошибки аппроксимации соответственно равны:
R 2 = 0, 769
σ 2 = 3, 02
Но для ранее построенного уравнения парной линейной регрессии эти же показатели составляли соответственно:
R 2 = 0, 774
σ 2 = 4, 42
Следовательно, с одной стороны индекс аппроксимации уменьшился (с некоторой степенью приближения можно считать, что он практически не изменился), зато с другой стороны, значительно уменьшилась ошибка аппроксимации. В процентах к среднему значению результативной переменной y для уравнения парной линейной регрессии эта ошибка составляла 11%, а для уравнения двухфакторной линейной регрессии – 7%.
Таким образом, с одной стороны индекс детерминации показывает, что включение дополнительного фактора в модель не обязательно, Но, с другой стороны, расчет ошибки аппроксимации позволяет утверждать, что уравнение двухфакторной линейной регрессии лучше описывает реальную статистическую зависимость.
Это подчеркивает неоднозначность решения проблемы отбора факторов для включения в модель регрессии. Поэтому специалисты по эконометрике разработали несколько различных подходов к решению этой проблемы.
Проблема отбора факторов связана с двойственным отношением к вопросу о включении в регрессионное уравнение независимых переменных. С одной стороны, естественно стремление учесть все возможные влияния на результативный признак и, следовательно, включить в модель полный набор выявленных переменных. С другой стороны, возрастает сложность расчетов и затраты, связанные с получением максимума информации, могут оказаться неоправданными. Нельзя забывать и о том, что для построения уравнения регрессии число объектов должно в несколько раз превышать число независимых переменных. Эти противоречивые требования приводят к необходимости компромисса, результатом которого и является «наилучшее» уравнение регрессии. Существует несколько методов, приводящих к цели: метод всех возможных регрессий, метод исключения, метод включения, шаговый регрессионный и ступенчатый регрессионный методы.
Метод всех возможных регрессий заключается в переборе и сравнении всех потенциально возможных уравнений. В качестве критерия сравнения используется коэффициент детерминации R2. «Наилучшим» признается уравнение с наибольшей величиной R2. Метод весьма трудоемок и предполагает использование специальных компьютерных программ.
Методы исключения и включения являются усовершенствованными вариантами предыдущего метода. В методе исключения в качестве исходного рассматривается регрессионное уравнение, включающее все возможные переменные. Рассчитывается значение специального статистического критерия (частного критерия Фишера) для каждой из переменных, как будто бы она была последней переменной, введенной в регрессионное уравнение. Минимальная величина частного F-критерия (Fmin) сравнивается с критической величиной (Fкр), основанной на заданном исследователем уровне значимости. Если Fmin> Fкр, то уравнение остается без изменения. Если Fminкр, то переменная, для которой рассчитывался этот частный F-критерий, исключается. Производится перерасчет уравнения регрессии для оставшихся переменных, и процедура повторяется для нового уравнения регрессии. Исключение из рассмотрения уравнений с незначимыми переменными уменьшает объем вычислений, что является достоинством этого метода по сравнению с предыдущим.
Метод включения состоит в том, что в уравнение включаются переменные по степени их важности до тех пор, пока уравнение не станет достаточно «хорошим». Степень важности определяется линейным коэффициентом корреляции, показывающим тесноту связи между анализируемой независимой переменной и результативным признаком: чем теснее связь, тем больше информации о результирующем признаке содержит данный факторный признак и тем важнее, следовательно, введение этого признака в уравнение.
Процедура начинается с отбора факторного признака, наиболее тесно связанного с результативным признаком, т. е. такого факторного признака, которому соответствует максимальный по величине парный линейный коэффициент корреляции. Далее строится линейное уравнение регрессии, содержащее отобранную независимую переменную. Выбор следующих переменных осуществляется с помощью частных коэффициентов корреляции, в которых исключается влияние вошедших в модель факторов. Для каждой введенной переменной рассчитывается частный F-критерий, по величине которого судят о том, значим ли вклад этой переменной. Как только величина частного F-критерия, относящаяся к очередной переменной, оказывается незначимой, т. е. эффект от введения этой переменной становится малозаметным, процесс включения переменных заканчивается. Метод включения связан с меньшим объемом вычислений, чем предыдущие методы. Но при введении новой переменной нередко значимость включенных ранее переменных изменяется. Метод включения этого не учитывает, что является его недостатком. Модификацией метода включения, исправляющей этот недостаток, является шаговый регрессионный метод.
Шаговый регрессионный метод кроме процедуры метода включения содержит анализ переменных, включенных в уравнение на предыдущей стадии. Потребность в таком анализе возникает в связи с тем, что переменная, обоснованно введенная в уравнение на ранней стадии, может оказаться лишней из-за взаимосвязи ее с переменными, позднее включенными в уравнение. Анализ заключается в расчете на каждом этапе частных F-критериев для каждой переменной уравнения и сравнении их с величиной Fкр, точкой F-распределения, соответствующей заданному исследователем уровню значимости. Частный F-критерий показывает вклад переменной в вариацию результативного признака в предположении, что она вошла в модель последней, а сравнение его с Fкр позволяет судить о значимости рассматриваемой переменной с учетом влияния позднее включенных факторов. Незначимые переменные из уравнения исключаются.
Рассмотренные методы предполагают довольно большой объем вычислений и практически неосуществимы без ЭВМ. Для реализации ступенчатого регрессионного метода вполне достаточно малой вычислительной техники.
Ступенчатый регрессионный метод включает в себя такую последовательность действий. Сначала выбирается наиболее тесно связанная с результативным признаком переменная и составляется уравнение регрессии. Затем находят разности фактических и выравненных значений и эти разности (остатки) рассматриваются как значения результативной переменной. Для остатков подбирается одна из оставшихся независимых переменных и т. д. На каждой стадии проверяется значимость регрессии по критерию Фишера. Как только обнаружится незначимость, процесс прекращается и окончательное уравнение получается суммированием уравнений, полученных на каждой стадии за исключением последней.
Ступенчатый регрессионный метод менее точен, чем предыдущие, но не столь громоздок. Он оказывается полезным в случаях, когда необходимо внести содержательные правки в уравнение. Так, для изучения факторов, влияющих на цены угля в Санкт-Петербурге в конце XIX— начале XX в., было получено уравнение множественной регрессии. В него вошли следующие переменные: цены угля в Лондоне, добыча угля в России и экспорт из России. Здесь не обосновано появление в модели такого фактора, как добыча угля, поскольку Санкт-Петербург работал исключительно на импортном угле. Модели легко придать экономический смысл, если независимую переменную «добыча» заменить независимой переменной «импорт». Формально такая замена возможна, поскольку между импортом и добычей существует тесная связь.
Пользуясь ступенчатым методом, исследователь может совершить эту замену, если предпочтет содержательно интерпретируемый фактор.
Заключение. Таким образом, основное внимание на данной лекции было посвящено проблемам построения уравнений множественной регрессии и, прежде всего, проблемам отбора факторов, которые целесообразно включить в модель. На следующей лекции мы рассмотрим некоторые специальные методы отбора факторов, включаемых в модель множественной регрессии, на основе так называемого «конфлюэнтного анализа» и анализа мультиколлинеарности.