Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
История исследований в области нейронных сетей
|
|
Возвратимся немного назад и рассмотрим историю исследований нейронных сетей.
Как и в истории любой другой науки, здесь были свои успехи и неудачи. Кроме того, здесь постоянно сказывается психологический фактор, проявляющийся в неспособности человека описать словами то, как он думает.
Способность нейронной сети к обучению впервые исследована Дж. Маккалоком и У. Питтом. В 1943 году вышла их работа " Логическое исчисление идей, относящихся к нервной деятельности", в которой была построена модель нейрона и сформулированы принципы построения искусственных нейронных сетей.
Крупный толчок развитию нейрокибернетики дал американский нейрофизиолог Френк Розенблатт, предложивший в 1962 году свою модель нейронной сети — персептрон. Воспринятый первоначально с большим энтузиазмом, он вскоре подвергся интенсивным нападкам со стороны крупных научных авторитетов. И хотя подробный анализ их аргументов показывает, что они оспаривали не совсем тот персептрон, который предлагал Розенблатт, крупные исследования по нейронным сетям были свернуты почти на 10 лет.
Несмотря на это в 70-е годы было предложено много интересных разработок, таких, например, как когнитрон, способный хорошо распознавать достаточно сложные образы независимо от поворота изображения и изменения его масштаба.
В 1982 году американский биофизик Дж. Хопфилд предложил оригинальную модель нейронной сети, названную его именем. В последующие несколько лет было найдено множество эффективных алгоритмов: сеть встречного потока, двунаправленная ассоциативная память и др.
В киевском институте кибернетики с 70-х годов ведутся работы над стохастическими нейронными сетями.
Модель нейронной сети с обратным распространением ошибки (back propagation)
В 1986 году Дж. Хинтон и его коллеги опубликовали статью с описанием модели нейронной сети и алгоритмом ее обучения, что дало новый толчок исследованиям в области искусственных нейронных сетей.
Нейронная сеть состоит из множества одинаковых элементов — нейронов, поэтому начнем с них рассмотрение работы искусственной нейронной сети.
Биологический нейрон моделируется как устройство, имеющее несколько входов (дендриты) и один выход (аксон). Каждому входу ставится в соответствие некоторый весовой коэффициент (w), характеризующий пропускную способность канала и оценивающий степень влияния сигнала с этого входа на сигнал на выходе. В зависимости от конкретной реализации, обрабатываемые нейроном сигналы могут быть аналоговыми или цифровыми (1 или 0). В теле нейрона происходит взвешенное суммирование входных возбуждений, и далее это значение является аргументом активационной функции нейрона, один из возможных вариантов которой представлен на рис. 1.
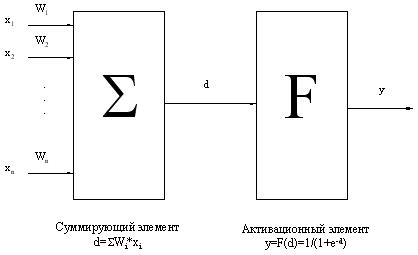
Рис. 2. Искусственный нейрон
Будучи соединенными определенным образом, нейроны образуют нейронную сеть. Работа сети разделяется на обучение и адаптацию. Под обучением понимается процесс адаптации сети к предъявляемым эталонным образцам путем модификации (в соответствии с тем или иным алгоритмом) весовых коэффициентов связей между нейронами. Заметим, что этот процесс является результатом алгоритма функционирования сети, а не предварительно заложенных в нее знаний человека, как это часто бывает в системах искусственного интеллекта.
Среди различных структур нейронных сетей (НС) одной из наиболее известных является многослойная структура, в которой каждый нейрон произвольного слоя связан со всеми аксонами нейронов предыдущего слоя или, в случае первого слоя, со всеми входами НС. Такие НС называются полносвязными. Когда в сети только один слой, алгоритм ее обучения с учителем довольно очевиден, так как правильные выходные состояния нейронов единственного слоя заведомо известны и подстройка синаптических связей идет в направлении, минимизирующем ошибку на выходе сети. По этому принципу строится, например, алгоритм обучения однослойного персептрона. В многослойных же сетях оптимальные выходные значения нейронов всех слоев, кроме последнего, как правило, не известны, и двух- или более слойный персептрон уже невозможно обучить, руководствуясь только величинами ошибок на выходах НС. Один из вариантов решения этой проблемы: разработка наборов выходных сигналов, соответствующих входным, для каждого слоя НС, что, конечно, является очень трудоемкой операцией и не всегда осуществимо. Второй вариант: динамическая подстройка весовых коэффициентов синапсов, в ходе которой выбираются, как правило, наиболее слабые связи и изменяются на малую величину в ту или иную сторону, а сохраняются только те изменения, которые повлекли уменьшение ошибки на выходе всей сети. Очевидно, что данный метод " тыка", несмотря на свою кажущуюся простоту, требует громоздких рутинных вычислений. И, наконец, третий, более приемлемый вариант: распространение сигналов ошибки от выходов НС к ее входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Этот алгоритм обучения НС получил название процедуры обратного распространения. Именно он будет рассмотрен в дальнейшем.
Согласно методу наименьших квадратов, минимизируемой целевой функцией ошибки НС является величина:
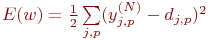
| (3) |
где 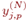 – реальное выходное состояние нейрона j выходного слоя N нейронной сети при подаче на ее входы p-го образа; djp – идеальное (желаемое) выходное состояние этого нейрона.
– реальное выходное состояние нейрона j выходного слоя N нейронной сети при подаче на ее входы p-го образа; djp – идеальное (желаемое) выходное состояние этого нейрона.
Суммирование ведется по всем нейронам выходного слоя и по всем обрабатываемым сетью образам. Минимизация ведется методом градиентного спуска, что означает подстройку весовых коэффициентов следующим образом:
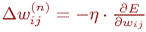
| (4) |
Здесь wij – весовой коэффициент синаптической связи, соединяющей i-ый нейрон слоя n-1 с j-ым нейроном слоя n, 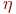 – коэффициент скорости обучения, 0< < 1.
– коэффициент скорости обучения, 0< < 1.
Как показано в [2],

| (5) |
Здесь под yj, как и раньше, подразумевается выход нейрона j, а под sj – взвешенная сумма его входных сигналов, то есть аргумент активационной функции. Так как множитель dyj/dsj является производной этой функции по ее аргументу, из этого следует, что производная активационной функция должна быть определена на всей оси абсцисс. В связи с этим функция единичного скачка и прочие активационные функции с неоднородностями не подходят для рассматриваемых НС. В них применяются такие гладкие функции, как гиперболический тангенс или классический сигмоид с экспонентой. В случае гиперболического тангенса
В случае гиперболического тангенса
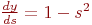
| (6) |
Третий множитель 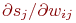 , очевидно, равен выходу нейрона предыдущего слоя
, очевидно, равен выходу нейрона предыдущего слоя 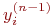 .
.
Что касается первого множителя в (4.5), он легко раскладывается следующим образом[2]:
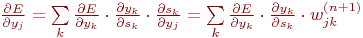
| (7) |
Здесь суммирование по k выполняется среди нейронов слоя n+1.
Введя новую переменную
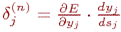
| (8) |
мы получим рекурсивную формулу для расчетов величин 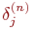 слоя n из величин
слоя n из величин 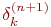 более старшего слоя n+1.
более старшего слоя n+1.
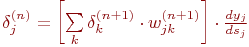
| (9) |
Для выходного же слоя
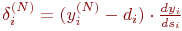
| (10) |
Теперь мы можем записать (4.4) в раскрытом виде:
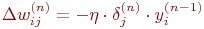
| (11) |
Иногда для придания процессу коррекции весов некоторой инерционности, сглаживающей резкие скачки при перемещении по поверхности целевой функции, (11) дополняется значением изменения веса на предыдущей итерации
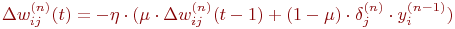
| (12) |
где 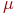 – коэффициент инерционности, t – номер текущей итерации.
– коэффициент инерционности, t – номер текущей итерации.
Таким образом, полный алгоритм обучения НС с помощью процедуры обратного распространения строится так:
1. Подать на входы сети один из возможных образов и в режиме обычного функционирования НС, когда сигналы распространяются от входов к выходам, рассчитать значения последних. Напомним, что
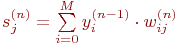
| (13) |
2. где M – число нейронов в слое n-1 с учетом нейрона с постоянным выходным состоянием +1, задающего смещение; 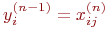 – i-ый вход нейрона j слоя n.
– i-ый вход нейрона j слоя n.
3. 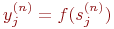 , где f() – сигмоид, (14)
, где f() – сигмоид, (14)
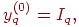
| (15) |
4. где Iq – q-ая компонента вектора входного образа.
5. Рассчитать 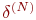 для выходного слоя по формуле (10). Рассчитать по формуле (11) или (12) изменения весов
для выходного слоя по формуле (10). Рассчитать по формуле (11) или (12) изменения весов 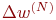 слоя N.
слоя N.
6. Рассчитать по формулам (9) и (11) (или (9) и (10)) соответственно 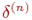 и
и 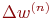 для всех остальных слоев, n=N-1,...1.
для всех остальных слоев, n=N-1,...1.
7. Скорректировать все веса в НС
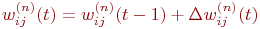
| (16) |
8. 
Рис. 3. Диаграмма сигналов в сети при обучении по алгоритму обратного распространения
Если ошибка сети существенна, перейти на шаг 1. В противном случае – конец.
Сети на шаге 1 попеременно в случайном порядке предъявляются все тренировочные образы, чтобы сеть, образно говоря, не забывала одни по мере запоминания других. Алгоритм иллюстрируется рис. 3.
Из выражения (10) следует, что, когда выходное значение стремится к нулю, эффективность обучения заметно снижается. При двоичных входных векторах в среднем половина весовых коэффициентов не будет корректироваться [3], поэтому область возможных значений выходов нейронов [0, 1] желательно сдвинуть в пределы [-0.5, +0.5], что достигается простыми модификациями логистических функций. Например, сигмоид с экспонентой преобразуется к виду
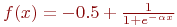
| (17) |
Теперь коснемся вопроса емкости НС, то есть числа образов, предъявляемых на ее входы, которые она способна научиться распознавать. Для сетей с числом слоев больше двух он остается открытым. Как показано в [4], для НС с двумя слоями, то есть одним выходным и одним скрытым слоем, детерминистская емкость сети Cd оценивается так:
Nw/Ny< Cd< Nw/Ny  log(Nw/Ny) (18)
log(Nw/Ny) (18)
где Nw – число подстраиваемых весов, Ny – число нейронов в выходном слое.
Следует отметить, что данное выражение получено с учетом некоторых ограничений. Во-первых, число входов Nx и нейронов в скрытом слое Nh должно удовлетворять неравенству Nx+Nh> Ny. Во-вторых, Nw/Ny> 1000. Однако вышеприведенная оценка выполнялась для сетей с активационными функциями нейронов в виде порога, а емкость сетей с гладкими активационными функциями, например – (17), обычно больше. Кроме того, фигурирующее в названии емкости прилагательное " детерминистский" означает, что полученная оценка емкости подходит абсолютно для всех возможных входных образов, которые могут быть представлены Nx входами. В действительности распределение входных образов, как правило, обладает некоторой регулярностью, что позволяет НС проводить обобщение и, таким образом, увеличивать реальную емкость. Так как распределение образов, в общем случае, заранее не известно, мы можем говорить о такой емкости только предположительно, но обычно она раза в два превышает емкость детерминистскую.
В продолжение разговора о емкости НС логично затронуть вопрос о требуемой мощности выходного слоя сети, выполняющего окончательную классификацию образов. Дело в том, что для разделения множества входных образов, например, по двум классам, достаточно всего одного выхода. При этом каждый логический уровень – " 1" и " 0" – будет обозначать отдельный класс. На двух выходах можно закодировать уже 4 класса, и так далее. Однако результаты работы сети, организованной таким образом, можно сказать – " под завязку", – не очень надежны. Для повышения достоверности классификации желательно ввести избыточность путем выделения каждому классу одного нейрона в выходном слое или, что еще лучше, нескольких, каждый из которых обучается определять принадлежность образа к классу со своей степенью достоверности, например: высокой, средней и низкой. Такие НС позволяют проводить классификацию входных образов, объединенных в нечеткие (размытые или пересекающиеся) множества. Это свойство приближает подобные НС к условиям реальной жизни.
Рассматриваемая НС имеет несколько " узких мест". Во-первых, в процессе обучения может возникнуть ситуация, когда большие положительные или отрицательные значения весовых коэффициентов сместят рабочую точку на сигмоидах многих нейронов в область насыщения. Малые величины производной от логистической функции приведут в соответствие с (9) и (10) к остановке обучения, что парализует НС. Во-вторых, применение метода градиентного спуска не гарантирует, что будет найден глобальный, а не локальный минимум целевой функции. Эта проблема связана еще с одной, а именно – с выбором величины скорости обучения. Доказательство сходимости обучения в процессе обратного распространения основано на производных — то есть приращения весов и, следовательно, скорость обучения должны быть бесконечно малыми, — однако в этом случае обучение будет происходить неприемлемо медленно. С другой стороны, слишком большие коррекции весов могут привести к постоянной неустойчивости процесса обучения. Поэтому в качестве обычно выбирается число меньше 1, но не очень маленькое, например, 0.1, и оно, вообще говоря, может постепенно уменьшаться в процессе обучения. Кроме того, для исключения случайных попаданий в локальные минимумы иногда, после того как значения весовых коэффициентов стабилизируются, кратковременно сильно увеличивают, чтобы начать градиентный спуск из новой точки. Если повторение этой процедуры несколько раз приведет алгоритм в одно и то же состояние НС, можно более или менее уверенно сказать, что найден глобальный максимум, а не какой-то другой.
Существует и иной метод исключения локальных минимумов, а заодно и паралича НС, заключающийся в применении стохастических НС, но о них лучше поговорить отдельно.