Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Методы Data Mining. Визуальные инструменты Data Mining.
|
|
Методы Data Mining.
Технологические методы.
- непосредственное использование данных, или сохранение данных: кластерный анализ, метод ближайшего соседа, метод k-ближайшего соседа, рассуждение по аналогии.
Выявление и использование формализованных закономерностей, или дистилляция шаблонов: логические методы, методы визуализации, методы кросс-табуляции, методы, основанные на уравнениях.
Статистические методы:
-дескриптивный анализ и описание исходных данных.
-анализ связей (корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ).
-многомерный статистический анализ (компонентный анализ, дискриминантный анализ, многомерный регрессионный анализ, канонические корреляции и др.).
-анализ временных рядов (динамические модели и прогнозирование).
Кибернетические методы:
-искусственные нейронные сети (распознавание, кластеризация, прогноз);
-эволюционное программирование (в т.ч. алгоритмы метода группового учета аргументов);
-генетические алгоритмы (оптимизация);
-ассоциативная память (поиск аналогов, прототипов);
-нечеткая логика;
-деревья решений;
-системы обработки экспертных знаний.
Визуализация инструментов Data Mining.
- для деревьев решений – визуализатор дерева решений, список правил, таблица сопряженности;
-для нейронных сетей – в зависимости от инструмента это может быть топология сети, график изменения величины ошибки, демонстрирующий процесс обучения.
- для карт Кохонена: карты входов, выходов, другие специфические карты.
-для линейной регрессии – линия регрессии.
-для кластеризации: дендрограммы, диаграммы рассеивания.
Решение большинства задач, связанных со взаимоотношением с клиентами, сводится к применению методов Data Mining:
-стимулирование продаж;
-прогнозирование спроса;
-анализ предпочтений;
-оценка эффективности действий;
-Direct Mail;
-оценка эффективности менеджеров.
Описанные методы позволяют значительно повысить эффективность работы с клиентами и решать те задачи, ради которых внедряются CRM системы:
-предугадать потребности;
-предлагать те продукты, которые заинтересуют;
-закупать столько товаров, сколько необходимо;
-использовать наиболее удачные каналы продвижения;
-концентрировать внимание на наиболее перспективных категориях клиентов.
Проблемы и вопросы Data Mining. Области применения.
Проблемы и вопросы:
-Data Mining – не может заменить аналитика!
-сложность разработки и эксплуатации приложения Data Mining. Основные аспекты:
А) квалификация пользователя;
Б) сложность подготовки данных;
В) большой процент ложных, недостоверных или бессмысленных результатов;
Г) высокая стоимость;
Д) наличие достаточного количества репрезентативных данных.
Области применения Data Mining:
-Database marketers – рыночная сегментация, идентификация целевых групп, построение профиля клиента;
- банковское дело – анализ кредитных рисков, привлечение и удержание клиентов, управление ресурсами;
-кредитные компании – детекция подлогов, формирование «типичного поведения» обладателя кредитки, анализ достоверности клиентских счетов, cross-selling программы.
-страховые компании – привлечение и удержание клиентов, прогнозирование финансовых показателей.
-розничная торговля – анализ деятельности торговых точек, построение профиля покупателя, управление ресурсами.
-биржевые трейдеры – выработка оптимальной торговой стратегии, контроль рисков.
-телекоммуникация и энергетика – привлечение клиентов, ценовая политика, анализ отказов, предсказание пиковых нагрузок, прогнозирование поступления средств.
-налоговые службы и аудиторы – детекция подлогов, прогнозирование поступлений в бюджет.
-фармацевтические компании – предсказание результатов будущего тестирования препаратов, программы испытания.
-медицина – диагностика, выбор лечебных воздействий, прогнозирование исхода хирургического вмешательства.
-управление производством – контроль качества, материально-техническое обеспечение, оптимизация технологического процесса.
-ученые и инженеры – построение эмпирических моделей, основанных на анализе данных, решение научно-технических задач.
36. Метод «деревья решений».
Возникновение – 50-е годы. Метод также называют деревьями решающих правил, деревьями классификации и регрессии. Это способ представления правил в иерархической, последовательной структуре.
Пример.
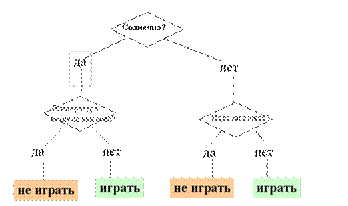
Преимущества метода:
-интуитивность деревьев решений;
-возможность извлекать правила из базы данных на естественном языке;
-не требует от пользователя выбора входных атрибутов;
-точность моделей;
-разработан ряд масштабируемых алгоритмов;
-быстрый процесс обучения;
-обработка пропущенных значений;
-работа и с числовыми, и с категориальными типам данных.
Процесс конструирования:
Основные этапы алгоритмов конструирования деревьев:
-построение или создание дерева (tree building);
-сокращение дерева (tree pruning).
Критерии расщепления:
-мера информационного выигрыша (information gain measure)
-индекс Gini, т.е. gini(T), определяется по формуле:
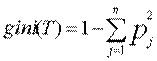
- Большое дерево не означает, что оно подходящее.
Остановка построения дерева.
Остановка – такой момент в процессе построения дерева, когда следует прекратить дальнейшие ветвления.
Варианты остановки:
-ранняя остановка;
-ограничение глубины дерева;
-задание минимального количества примеров.
Сокращение дерева или отсечение ветвей:
Критерии:
-точность распознавания
-ошибка.
Алгоритмы. CART.
-CART (Classification and Regression Tree)
-разработан в 1974-1984 годах четырьмя профессорами статистики
-CART предназначен для построения бинарного дерева решений.
Особенности:
-функция оценки качества разбиения;
-механизм отсечения дерева;
-алгоритм обработки пропущенных значений;
-построение деревьев регрессии.
Алгоритмы. С4.5
-строит дерево решений с неограниченным количество ветвей у узла.
-дискретные значения => только классификация
-каждая запись набора данных ассоциирована с одним из предопределенных классов => один из атрибутов набора данных должен являться меткой класса.
-количество классов должно быть значительно меньше количества записей в исследуемом наборе данных.
Перспективы и методы:
- разработка новых масштабируемых алгоритмов;
-метод деревьев – иерархическое, гибкое средство предсказания принадлежности объектов к определенному классу или прогнозирования значений числовых переменных.
-качество работы зависит как от выбора алгоритма, так и от набора исследуемых данных.
-чтобы построить качественную модель, необходимо понимать природу взаимосвязи между зависимыми и независимыми переменными и подготовить достаточный набор данных.
37. Метод «кластеризации».
Кластеризация – это автоматическое разбиение элементов некоторого множества на группы (кластеры) по принципу схожести.
Много практических применений в информатике и других областях:
-анализ данных (Data Mining);
-группировка и распознавание объектов;
-извлечение и поиск информации.
Общая схема кластеризации: