Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Аналитическая часть
|
|
Для того, чтобы приступить к описанию разработанного программного средства, необходимо вначале изучить теоретические основы биометрической идентификации и конкретно идентификации личности по голосу.
Биометрия - это, простым языком, физиологические или анатомические " характеристики" человека. Если, к примеру, обычную паролевую систему можно взломать методом подбора пароля или просто украсть его, то взломать биометрическую систему крайне сложно, практически не возможно. В настоящее время существуют такие биометрические параметры человека, как отпечатки пальцев, голос, радужная оболочка глаз, почерк, определенная манера работы на клавиатуре и другие. Все эти данные о человеке записываются в базу данных при регистрации, а затем, при идентификации, вновь полученные данные сравниваются с этими регистрационными характеристиками.
Задачей биометрической идентификации является создание системы, которая работала бы с минимальным количеством отказов в доступу пользователям, а так же на 100 % исключала несанкционированный вход злоумышленника в компьютер или какое-либо помещение ограниченного доступа. У каждого человека есть свои уникальные биометрические данные, которые являются его отличительными характеристиками. Эти характеристики нужны для того, чтобы " извлечь " их из человека, записать в базу данных, и затем при идентификации сравнить особенности характеристик идентифицируемого человека, с данными из базы системы.
Но все ли так хорошо в таких системах? Большое количество людей видят тока плюсы в биометрической идентификации, но есть и противники данных систем. Эти люди считают, что при распространении и развитии биометрических устройств каждый гражданин будет под определенным контролем, что является нарушением гражданских свобод. Обычному человеку будет недоступна информация о том, куда может уйти информация о его уникальных параметрах. А ведь эти " характеристики" могут быть использованы и против самого человека, что может привести к нарушению прав на конфиденциальность.
2.1Факторы, влияющие на уникальность речи
Человеческую речь можно квалифицировать на несколько видов
[1, 4-6]:
· нормативная;
· патологическая;
· преднамеренно измененная;
· эмоционально насыщенная и др..
Первый фактор, который влияет на уникальность речи - тип дыхания. Его можно разделить на:
· ключичный;
· грудной (диафрагменный);
Так сюда можно отнести неодинаковый объем легких у различных людей. Диапазон объема может варьироваться от 6000 см3 у взрослых людей с натренированным дыханием до 1000 см3 у маленьких детей. При достаточно глубоком диафрагменном дыхании может получиться так, что время выдоха во время разговора будет значительно продолжительнее времени вдоха. При спокойном дыхании эта разница значительно менее выражена. В таком случае продолжительность выдоха может достигнуть 6-8 секунд, вместо 1, 5-2 секунд при спокойном дыхании. Сама же речь не прерывается частыми вдохами и является непринужденной.
Противоположная ситуация - это когда речь человека является тяжелой и принужденной. Это случаи, когда физические показатели человека ограниченны; когда он сильно устал или находится в нервном состоянии. Так же у говорящего могут быть хронические болезни: астма, эмфизема легких и другие. Эти факторы значительно влияют на ритм и темп речи и являются уникальными признаками.
На речь так же влияет наличие высокого подсвязочного давления. Именно от этого уровня зависит качество генерируемого голоса. Уже на выходе из гортани голос несет в себе определенную высоту, силу и тембр.
Ниже будет представлена таблица, в которой наглядно видны отличия между мужским и женскими голосами (таблица 2.1) [2].
Таблица 2.1 Различие мужского и женского голосов
| Голоса | Основные тембральные окраски голосов / градации частоты основного тона | Пределы изменения частоты основного тона в процессе пения, Гц | Общий предел изменения частоты основного тона в процессе разговорной речи, Гц | Длинна голосовых связок, мм |
| Мужские | Бас/Низкий Баритон/Средний Тенор/Высокий | 80-350 100-400 130 510 | 90-120 | 24-25 22-24 18-24 |
| Женские | Контральто/Низкий Меццо-сопрано/Средний Сопрано/Высокий | 170-680 220-880 260-1020 | 160-340 | 18-21 18-19 14-17 |
Так же существуют и другие факторы, которые влияют на уникальность речи отдельных людей:
· манера интонирования (например, иноязычное влияние);
· спектр голосовых импульсов (зависит от их формы, периода ТО, скважности);
· интенсивность звука (меняется в довольно широких пределах);
· фильтрация голосовых импульсов ротовой и носовой полостями.
2.2 Система распознавания личности
Работа систем распознавания состоит из двух этапов:
- регистрация нового пользователя;
- идентификация зарегистрированного пользователя (процесс распознавания).
Каждый пользователь проходит регистрацию в системе, записав образец своего голос. Далее из образца извлекаются признаки, благодаря которым и происходит распознавание. На основе этих признаков строятся " шаблоны" пользователей. Такой " шаблон" является структурой, которая при данных признаках устанавливает степень подобия. Признаки только что записанного голоса сравниваются с признаками голоса из базы данных, после чего происходит идентификация или отказ в доступе.
Подытожив, можно выделить три основных этапа в системе распознавания личности:
· Этап обработки сигналов. Здесь происходит обработка самого сигнала с целью выделить признаки, необходимые для распознавания. Речевой сигнал представлен в виде определенной последовательности векторов признаков;
· Этап моделей. На данном этапе идет построение модели, так называемого шаблона, с помощью которого и высчитывается степень подобия между имеющейся моделью и признаками;
· Этап принятия решений. С помощью вычисленной степени подобия и заданных порогов принимается решение.
2.3 Образец и его предобработка
2.3.1 Обрабатываемый образец
Обрабатываемым образцом, при идентификации личности по голосу, является записанный речевой сигнал. При кодировании аналоговый сигнал представляется последовательностью мгновенных измерений значений амплитуд. Для того, чтобы записать и обработать речевой сигнал, берут частоту дискретизации, которая равняется 8 или 16 кГц.
Чтобы избежать некачественное распознавание, следует избегать ряд определенных факторов, таких как:
· плохая акустика в помещении;
· разное расстояние от произносящего до микрофона;
· несовпадение канала и др.
Например, если распознавать голос, который передается по телефону, то нельзя быть уверенным в том, что при регистрации и идентификации использовался один и тот же микрофон, а так же канал передачи. Так же следует учитывать влияние каких-либо посторонних помех.
Для того, чтобы запись была более качественной, необходимо, чтобы канал представлял собой микрофон, кабель и аналого-цифровой преобразователь.
2.3.2 Предварительная обработка
Суть предварительной обработки - обработка фильтром определенных частот, а так же удаление участков, которые не содержат речевой сигнал [3-6].
Чтобы на практике определить крайние точки первого слова, необходимо проделать определенные этапы предобработки.
1. Допустим, что в интервале 300мс от начала записи микрофона имеются только посторонние шумы и помехи. Разделим весь входной сигнал на 256 сегментов. Речь можно представить как:
 ,
,
 ,
,
где S - последовательность отчетов входного сигнала, t = 0, 1...255.
Для первых 10 первых сегментов используем быстрое преобразование Фурье (БПФ):

где i = 0, 1,..., 255, а p = 0, 1,..., 9.
Далее идет подсчет арифметического среднего значения:

где i = 0, 1,..., 127 (так как наблюдается симметрия).
Среднее квадратичное отклонение считается по формуле:
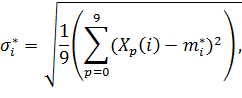
Расчет порога шумов:
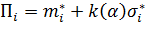 ,
,
где  ,
, 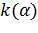 =2, 33.
=2, 33.
В итоге получим 128 значений порогов шума. Далее идет проверка каждого сегмента. Если в отдельном сегменте превышено 15 порогов, то можно с уверенностью говорить, что здесь находится начало слова. Но точность нахождения сегмента с началом слова равняется порядка 23 секунд. Чтобы определить более точное расположение начала слова, нужно разбить его на 8 отрезков, в каждом из которых будет находиться 32 отсчета. Получается, что каждый отрезок будет равен 3 мс. Все количество начальных расчетов шума следует разделить на 80 блоков, с целью вычисления модуля средней амплитуды шума:
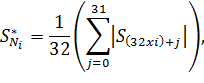



где , =2, 33.
Финальным этапом является сравнение среднего значения модуля каждого блока 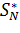 в сегменте, где находится слово с порогом
в сегменте, где находится слово с порогом  . Если двух подряд идущих блоков выше порога , то делаем вывод, что в этом блоке находится начало слова, которое произнес пользователь при регистрации.
. Если двух подряд идущих блоков выше порога , то делаем вывод, что в этом блоке находится начало слова, которое произнес пользователь при регистрации.
Ниже будут представлены блок-схемы алгоритма определения начала слова (рисунок 2.1) и алгоритма уточнения данного интервала (рисунок 2.2).

Рисунок 2.1 Блок-схема алгоритма определения начала слова

Рисунок 2.2 Блок-схема алгоритма уточнения определения начала слова
2.4 Извлечение признаков
Целью обработки сигнала в подобных приложениях является выделение в речевом сигнале информации, которая релевантная для распознавания по голосу. Такая информация представляет индивидуальные особенности голоса каждого человека, или признаки. Эти признаки выделяются с целью формирования шаблона или для того, чтобы сравнить их с уже зарегистрированными шаблонами. Изначально более подходящие признаки для распознавания определить невозможно. Для этого нужна экспериментальная оценка с предварительным перебором всех возможных признаков.
Можно разбить признаки на два вида:
· низкоуровневые (анатомическое строение речевого аппарата);
· высокоуровневые (манера произношения).
Чтобы обработать речевой сигнал, нужно использовать кратковременный анализ. Сам сигнал следует разбить на временные окна определенного размера. Предполагается, что в этих окнах не меняются параметры сигнала. Работая с речевым сигналом, размер такого окна должен составлять 10-30 мс. Для наибольшей точности между окнами следует делать перекрытия, которые равны половине длины окна. Чтобы извлечь признаки из каждого окна, к ним применяются специальные алгоритмы. Ниже будут рассмотрены два основных метода извлечения признаков из речевого сигнала.
2.4.1 Мел-частотные кепстральные коэффициенты
Мел
В переводе с др.греческого " мэлос" - это звук. На практике мел - это психофизическая единица высоты звука, в основании которой лежит восприятие этого звука человечискими слуховыми анализаторами.
Амплитудно-частотные характеристики (АЧХ) человеческого органа слуха даже близко не похожи на прямую, а амплитуда не является точной мерой измерения громкости (рисунок 2.3). В связи с этим и были введены эмпирические единицы громкости звука.

Рисунок 2.3 АЧХ человеческого органа слуха
Точно так же и высота звука, которая воспринимается органами слуха человека, не является линейно зависимой от его частоты (рисунок 2.4)

Рисунок 2.4 Зависимость высоты звука от его частоты
Единицы измерения мел часто используются в системах, задачей которых является распознавание. С их помощью можно близко изучить устройство человеческого восприятия.
Кепстр
Слово " cepstrum" появилось с помощью перестановки букв в слове " spectrum" [7]. То есть он был создан после перестановки букв в слове " спектр". Оно было введено в 1963 году Богертом. Кепстр является эмпирически измеряемой величиной - результатом взятия преобразования Фурье логарифма спектра сигнала. Кепстр разделяют на три вида:
· энергетический кепстр;
· комплексный кепстр;
· реальный кепстр;
· фазовый кепстр.
Дата определения энергетического кепстра - 1963 год. Это была работа целой группы людей: Bogert, Healy, Tukey. Их работа называлась " The Quefrency Alanysis of Time Series for Echoes: Cepstrum, Pseudo Autocovariance, Cross-Cepstrum and Saphe Cracking". Энергетический кепстр может быть определен двумя способами:
· устно: энергетический кепстр сигнала - это величина Фурье-спектра логарифма квадратичной величины Фурье-спектра сигнала;
· с помощью алгоритма:

Комплексный кепстр предложил Оппенгейм. Это была его работа по теории гомоморфных систем. Алгоритмическое представление комплексного кепстра:
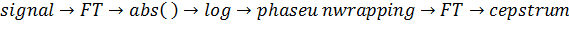
Реальный кепстр (РК) использует логарифм функции, которая определена для реальных значений. Данный кепстр имеет взаимосвязь с энергетическим кепстром (ЭК):

А так же с комплексным спектром (КК):
 ,
,
где 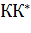 - обращенный по времени комплексный кепстр.
- обращенный по времени комплексный кепстр.
В основе комплексного кепстра лежит комплексный логарифм функции, которая определена для комплексных значений.
Взаимосвязь комплексного кепстра и фазового:

Различием между комплексным и реальным кепстрами является то, что кроме информации об амплитуде спектра, комплексный кепстр содержит еще и данные о фазе исходного спектра. Это добавляет возможность реконструкции сигнала.
В целом кепстр можно рассматривать как информацию о скорости изменения в различных диапазонах спектра. В первое время его использовали для измерения сейсмических отголосков после землетрясений и сильных взрывов. В настоящее время его применение нашли в системах распознавания речи.
Алгоритм метода
В системах распознавания по голосу данный метод считается одним из самых популярных. Суть метода заключается в следующем [8]:
1. Подача последовательности отсчетов определенной части сигнала, которая исследуется на итерации x0,...., xN-1.
2. Применение весовой функции для уменьшения искажений. Чаще всего в качестве весовой функции используют окно Хэмминга:
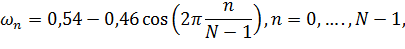
где 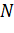 - размер окна в отсчетах.
- размер окна в отсчетах.
3. Дискретное преобразование Фурье:
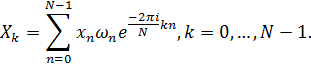
где  соответствует частотам:
соответствует частотам:
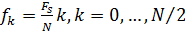 ,
,
где  является частотой дискретизация.
является частотой дискретизация.
Так же можно использовать быстрое преобразование Фурье:
Основная идея быстрого преобразования Фурье заключается в том, что каждую вторую выборку можно использовать для получения половинного спектра. Формально это означает, что формула дискретного преобразования Фурье может быть представлена в виде двух сумм.
4. Далее с помощью треугольных фильтров идет разбиение на диапазоны. Границы этих фильтров рассчитываются в шкале мел. Мел - единица высоты звука, основанная на восприятии этого звука нашими ушами. Формула для перевода в мел-частотную область:
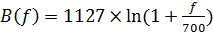 .
.
Формула обратного преобразования:
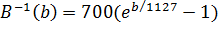 .
.
Чаще всего используют 24 фильтра. Количество фильтров обозначим как  . Фильтры применяются к квадратам модулей коэффициентов преобразования Фурье, а затем высчитывается логарифм:
. Фильтры применяются к квадратам модулей коэффициентов преобразования Фурье, а затем высчитывается логарифм:
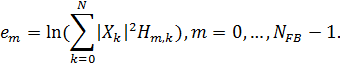
где 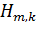 - весовые коэффициенты фильтров, которые были получены.
- весовые коэффициенты фильтров, которые были получены.
5. Дискретное косинусное преобразование является последним этапом данного метода. На этой стадии происходит вычисление мел-частотных кепстральных коэффициентов (MFCC):

Коэффициент  - энергия сигнала, поэтому он не используется. Количество мел-частотных кепстральных коэффициентов на практике равняется порядка 12.
- энергия сигнала, поэтому он не используется. Количество мел-частотных кепстральных коэффициентов на практике равняется порядка 12.
2.4.2 Кепстральные коэффициенты, основанные на линейного предсказания
В данном методе так же участвуют кепстральные коэффициенты. Смысл линейного предсказания основывается на возможности аппроксимировать текущий отчет с помощью линейной комбинации некоторого количества отчетов, сделанных до настоящего времени.
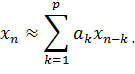
У линейной комбинации а1,..., аp есть весовые коэффициенты. Их называют коэффициентами линейного предсказания. Чтобы найти эти коэффициенты, нужно использовать рекурсивный алгоритм Дарбина.
Далее, с помощью уже известных коэффициентов линейного предсказания находятся кепстральные коэффициенты. Следует отметить, что их количество может превышать количество коэффициентов линейного предсказания.

Например, если взять сигнал, частота дискретизации которого равняется 8000Гц и при этом использовать 12 коэффициентов линейного предсказания, то в итоге получим около 18 кепстральных коэффициентов.
2.5 Обработка извлеченных признаков
Оба выше перечисленных метода используют для выделения характеристик на маленьком участке. На этапе обработке признаков существует прием, суть которого объединить векторы признаков с их первыми производными (дельта-коэффициентами), целью которого является сохранение информации о динамике речи. Существуют и так называемые методы нормализации. Они используют все векторы признаком исследуемой записи. Чаще всего в повседневной жизни встречается метод вычитания кепстрального целого(CMS - Cepstral Mean Subtraction). Его используют для того, чтобы снизить влияние канала.
2.6 Способы классификации моделей
Все модели, связанные с распознаванием личности по голосу, можно разделить на генеративные (моделирование данных для обучения) и дискриминативные (построение разграничений между классами). К генеративным можно отнести Gauss Mixture Models (GMM - модель гауссовых смесей), а к дикримитативным - Support Vector Machines (SVM -метод опорных векторов).
Самыми распространенными решающими правилами являются: GMM, SVM, вычисление расстояний, метод ближайшего соседа
2.6.1 Вычисление расстояний
Суть метода заключается в том, что среди всех записанных шаблонов есть один такой, который максимально схож с распознаваемым голосом, т.е. разница расстояний между векторами минимальная.
Методы вычисления:
1. Евклидово расстояние:
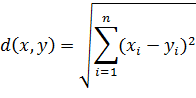
Расстояние Махалонобиса:

Расстояние городских кварталов:

где  и
и 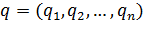
2.6.2 Метод опорных векторов
Данный метод классификации моделей является не самым сложным, но достаточно надежным. Суть метода:
Пусть нам дано обучение D, который состоит из определенного количества объектов n:
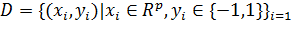 ,
,
где возможные значения y - это -1 или 1.В зависимости от значения y мы можем определить класс каждой точки  (является вектором размерности p).
(является вектором размерности p).
Чтобы получить определенную гиперплоскость, нужно записать ее как простое множество точек x, которые удовлетворяют данному выражению:
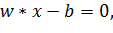
| x2 |
 является скалярным произведением, а
является скалярным произведением, а  - нормаль к гиперплоскости (рис. 2.5).
- нормаль к гиперплоскости (рис. 2.5).
| w |
| x1 |

|
Рисунок 2.5 Гиперплоскость и нормаль
Пусть даны две гиперплоскости:


Область, которая находится между этими двумя гиперплоскостями, называют " разностью".
С помощью геометрии высчитываем расстояние между этими гиперплоскостями -  .
.
Целевой же функцией будет являться:

2.6.3 Модель гауссовых смесей
Модель гауссовых смесей представляет собой взвешенную сумму М компонент и может быть записана выражением:
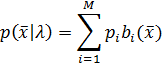
Каждый компонент является D - мерной гауссовой функцией распределения вида:
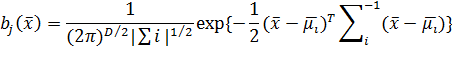
Полностью модель гауссовой смеси определяется векторами математического ожидания, ковариационными матрицами и весами смесей для каждого компонента модели:
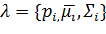
где i = 1,..., M.
Стоит отметить, что модель гауссовых смесей достаточно часто используется в системах распознавания человека по голосу. Чтобы данный метод работал, нам нужно найти векторы средних, веса компонентов и матрицы ковариации. Для этого используем EM - алгоритм (Expectation-maximization). На начальном этапе используются начальные значения параметров модели, но на каждом последующем шаге алгоритма осуществляется переоценка этих параметров. Чтобы найти начальные параметры используют алгоритм K-средних. Переоценка параметров осуществляется по формулам, представленным ниже:
· Estimation-step (вычисление апостериорных вероятностей)
 ;
;
· Maximization-step (вычисление новых параметров модели)
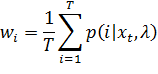

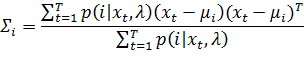
Все это продолжается до того момента, пока наши параметры не сойдутся.
2.6.4 Метод ближайшего соседа
Суть данного метода заключается в том, что сравниваются все векторы записанной последовательности. Это происходит с целью расчета расстояния, которое является минимальным между каждым вектором текущей последовательности и каждым вектором уже зарегистрированного " шаблона". Чтобы получить финальную оценку, эти расстояния усредняются:
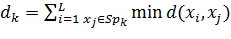 .
.
2.7 Аналогичные программы
В настоящие время выбор систем идентификации личности по голосу не так и огромен. Данные биометрические системы появились в России в 90-х годах. Стоит отметить, что особого распространения они не получили, так как это было больше похоже на роскошь, и стоили они порядка 12000$. Сегодня же идентификация по голосу становится более актуальной, и стоимость систем с того времени упала практически в 10 раз.
Разберем две аналогичные системы идентификации личности по голосу:
VoiceKey
VoiceKey – это мультифункциональная биометрическая платформа, которая работает дистанционно [6]. VoiceKey используют для идентификации пользователей по характеристикам его голоса, а так же лица, выявления злоумышленников, защиты корпоративной информации, обеспечения безопасности передачи данных через интернет в мобильном приложении или личном кабинете на сайте.
Преимущества:
· кроме поддержки голосовой биометрии, так же используется лицевая биометрия;
· масштабность;
· независимость от языка произношения;
· настройка прав доступа.
VoiceNet
Идентификация или верификация в технологиях VoiceNet осуществляется по заданным парольным фразам [15]. Как правило, их продолжительность составляется 5 секунд и дольше. В качестве уникальных параметров используется голос человека. Изначально VoiceNet создан для работы с телефонными каналами.
Преимущества:
· возможность удаленной идентификации;
· близкая к невозможному имитация голоса пользователя с помощью записывающего устройства;
· исключена идентификация пользователя, который находится под давлением злоумышленников, так как это влияет на его эмоциональное состояние (программа неустойчива к данным ситуациям);
· возможность одновременной идентификации по голосу и распознаванию речи (произнесенный пароль).
2.8 Недостатки большинства системы идентификации по голосу
У систем идентификации личности по голосу имеются не только достоинства, которые их возвышают над паролевыми защитами, но и ряд недостатков, которые могут сказаться в определенный момент идентификации.
Первым недостатком является то, что у каждого пользователя с возрастом меняется голос. В повседневной жизни это заметить почти невозможно, но данные системы достаточно к этому чувствительны. Данная ситуация сводится к тому, что администраторам системы нужно регулярно обновлять базу данных пользователей, записывая туда новые эталоны записанных речей.
Вторым недостатком следует назвать влияние физического и эмоционального состояния человека в момент записи речи при идентификации или регистрации. Если человека при идентификации имеет отдышку после определенной физической нагрузки, то велика вероятность, что он не пройдет идентификацию. Влияние может оказать стрессовая ситуация или алкогольное опьянение пользователя. Так же если у пользователя болит горло или сорван голос - идентификация невозможна.
Влияние на идентификацию может оказать канал передачи речевого сигнала к системе идентификации. Вероятность ошибки при идентификации, в случаи если эталон и записанная речь поступают по одному и тому же каналу минимальна, если по разным - значительно возрастает.
2.9 Действующие национальные стандарты
В таблице 2.2 представлен перечень действующих национальных стандартов, связанные с разрабатываемым программным средством идентификации личности по голосу [19].
Таблица 2.2 Национальные стандарты
| Обозначение ГОСТа | Наименование ГОСТа |
| ГОСТ Р ИСО/МЭК 19794-1-2008 | Автоматическая идентификация. Идентификация биометрическая. Форматы обмена биометрическими данными. Часть 1. Структура |
| ГОСТ Р ИСО/МЭК 19795-1-2007 | Автоматическая идентификация. Идентификация биометрическая. Эксплуатационные испытания и протоколы испытаний в биометрии. Часть 1. Принципы и структура |
| ГОСТ Р ИСО/МЭК 19795-2-2008 | Автоматическая идентификация. Идентификация биометрическая. Эксплуатационные испытания и протоколы испытаний в биометрии. Часть 2. Методы проведения технологического и сценарного испытаний |
| ГОСТ Р ИСО/МЭК ТО 19795-3-2009 | Автоматическая идентификация. Идентификация биометрическая. Эксплуатационные испытания и протоколы испытаний в биометрии. Часть 3. Особенности проведения испытаний при различных биометрических модальностях |
| ГОСТ Р ИСО/МЭК 19795-4-2011 | Информационные технологии. Биометрия. Эксплуатационные испытания и протоколы испытаний в биометрии. Часть 4. Испытания на совместимость |
| ГОСТ Р ИСО/МЭК 19784-1-2007 | Автоматическая идентификация. Идентификация биометрическая. Биометрический программный интерфейс. Часть 1. Спецификация биометрического программного интерфейса |
| ГОСТ Р ИСО/МЭК 19785-1-2008 | Автоматическая идентификация. Идентификация биометрическая. Единая структура форматов обмена биометрическими данными. Часть 1. Спецификация элементов данных |
| ГОСТ Р ИСО/МЭК 24709-1-2009 | Автоматическая идентификация. Идентификация биометрическая. Испытания на соответствие биометрическому программному интерфейсу (БиоАПИ). Часть 1. Методы и процедуры |
| ГОСТ Р ИСО/МЭК 29794-1-2012 | Информационные технологии. Биометрия. Качество биометрических образцов. Часть 1. Структура |