Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Приклад.
|
|
На вході задана послідовність цілих чисел b1, b2,..., bn з інтервалу 1-999. Список Fi, 1< =i< =n утворений упорядкуванням послідовності b1, b2,..., bi за зростанням. Скласти функцію для введення заданої послідовності, формування Fn у зв'язаному зберіганні і повернення покажчика на його початок.
Для розв'язання задачі будемо будувати упорядковані списки Fi+1, вводячи елемент bi+1 у певне місце списку Fi. Якщо список реалізований звичайним зв'язаним зберіганням, можливі три варіанти: коли в списку елементів немає, коли новий елемент додається на початку або в кінці списку. Програма маї вигляд:
/*arrange - створення упорядкованого зв'язаного списку */
LISTP arrange ()
{ int in;
LISTP r, p, new ();
r=new (0, new (1000, NULL));
while (scanf (" % d", & in)==1)
{
for (p=r; (p-> next)-> val< in; p=p-> next);
p-> next=new (in, p-> next);
}
return r;
}
СТЕКИ і ЧЕРГИ
Стек - це лінійний список, де операції додавання і вилучення елемента та доступу до елемента виконуються тільки в його кінці.
Черга -це лінійний список, в якому елементи вилучаються з початку списку, а додаються в його кінці.
Двостороння черга - це лінійний список, в якому операції можна виконувати і на початку, і в кінці.
У роботі частіше зустрічаються стеки. Наведемо приклад застосування стеків при обчисленні виразів. Однією з форм подавання виразів є бездужковий польський інверсний запис, в якому порядок виконання операції визначається її контекстом та позицією у виразі. Вираз задається так, що операції в ньому записуються в порядку їх виконання, а операнди містяться безпосередньо перед операцією; елементи запису розділяються пропуском чи комою. Наприклад, вираз (5+7)*3-4*2 в польському інверсному записі маї вигляд 5, 7, +, 3, *, 4, 2, *, -. Особливість польського інверсного запису полягає в тому, що значення виразу можна обчислити за один його перегляд зліва направо, використовуючи стек (стек спочатку повинен бути порожнім). Якщо при перегляді виразу з'являються дані, то вони заносяться в стек, а якщо з'явиться операція, то вона виконується над верхніми елементами стека з заміною їх результатом обчислення. Ілюстрація динаміки зміни стека для виразу 5, 7, +, 3, *, 4, 2, *, - маї вигляд: st=< > --< 5> --< 5, 7> --< 12> --< 12, 3> --< 36> --< 36, 4> --< 36, 4, 2> --< 36, 8> --< 28>.
Функція seval () обчислює значення виразу, заданого в масиві a[n] у польському інверсному записі, причому a[i]> =0 означаї невід'їмне ціле число, a[i]< 0-операцію. Для кодування операцій додавання, віднімання, множення і ділення вибрані відповідно від'їмні числа -1, -2, -3, -4. Для організації послідовного зберегання стека використовується масив цілих st[100] і ціла змінна t, що фіксує останній елемент стека У функції seval не реалізована перевірка стека на порожність, переповнення (t=-1, t=100) та на правильність вхідної інформації. Текст цієї функції є таким:
/*seval-обчислення виразу в польському інверсному записі*/
seval (a, n)
int a[], n;
{ int st [100], p, t, c;
t=-1;
for (p=0; p< n; p++)
if (a[p]< 0)
{ c=st[t- -];
swich (a[p])
{
case -1: st[t]+ =c; break;
case -2: st[t]- =c; break;
case -3: st[t]* =c; break;
case -4: st[t]/ =c; break; }
}
else st[++t]=a[p];
return st[t];
}
Послідовне зберігання стеків і черг. Припустемо, що для розміщення потрібних в задачі стеків та черг цілих чисел є послідовна ділянка пам'яті - масив d з M елементами, задана описом:
# define M 100
int d[M];
Реалізація одного стека здіснюється так: перший елемент стека розміщюється на початку області d, а індекс його останнього елемента відмічається значенням змінної a, яке спочатку дорівнюї -1, що означає порожнўй стек, тобто має бути опис int a=-1;. Додавання елемента в стек виконується оператором d[++a]=v; вилучення зі стека - оператором v=d[a--]. Для реалізації двох стеків можна поділити область d на дві ділянки розмірів M1 та M2 (M1+M2=M) і в кожній з них розміщати окремий стек. Але це недоцільно, оскільки в одному зі стеків може настати переповнення, а в другому - пам'ять буде вільна. Тому доцільніше перший стек розміщувати з початку області d, фіксуючи його вершину значенням змінної a, а другий стек-з кінця області d, фіксуючи його вершину в змінній b, тобто мати оголошення int a=-1, b=M; і стеки рухати назустріч один одному. Операції вилучення та додавання елементів в стеки тепер здіснюються так: вилучення елемента з першого стека - v=d[a--]; з другого стека - v=d[b++]; додавання елемента в перший стек - d[++a]=new; в другий - d[--b]=new. Переповнення області d настає за виконанням умови a=b-1.
Якщо в області d повинно бути більше двох стеків, то організація їх керування неможлива без перерозподілу пам'яті, тобто не уникнути ситуації, коли в одному зі стеків настає переповнення за наявності в d вільних ділянок. При перерозподілі пам'яті між стеками доводиться більшість стеків переміщати (як правило, до 10% залишиної вільної пам'яті ділити рівномірно між всіма стеками, решту - пропорційно збільшенню стека за час від останнього перерозподілу).
При реалізації черги в масиві d її перший елемент розміщується на початку d. Для фіксації значень індексів початку та кінця черги використовуються цілі змінні a і b з початковими значеннями a=0; b=-1, тобто потрібний опис int a=0, b=-1;. Вилучення елемента з непустої черги здійснюється оператором v=d[a++]; додавання елемента в чергу -оператором d[++b]=v; черга стає порожньою, коли a> b, тобто a=b+1. Досягнення кінця області d, коли b=M-1, вимагає перерозподілу пам'яті, тобто зміщення черги до лівогокраю області d. Якщо черга стає порожньою, то для зменшення таких перерозподілів часто беруть a=0; b=1. Можна уникнути перерозподілів, організуючи в області d чергу як циклічну структуру, в якій слідом за останнім елементом області йде її перший елемент (...d[M-1], D[0], D[1],...). За використання циклічної структури рівність a=b+1 буде вірна для порожньої черги або для заповненої. Щоб розрізняти ці черги, необхідно додатково мати інформацію про кількість елементів у них.
Організація в d двох або більше черг неможлива без переміщень і перерозподілів пам'яті. Реалізація двосторонніх черг з послідовним зберіганням аналогічна реалізації звичайних черг.
Зв'язане зберігання стеків та черг. Проблеми переміщення і перерозподілу пам'яті, коли стеків n> =3 або черг n> =2, зникають при зв'язаному зберіганні. Стеки реалізуються аналогічно лінійним спискам з покажчиком на кінець списку і зв'язком від наступного елемента до попереднього. Описом стека та його ініціацією є: LISTP dl=NULL;.
Функцўя pop вилучення елемента зі стека і функція add додавання нового елемента в стек з формальним параметром типу LISTP* змінюють значення покажчика на останній елемент стека. Крім того, функція pop повертає значення вилученого елемента стека. Текст цих функцій записується у вигляді:
/*pop-вилучення елемента зі стека *dl*/
pop (dl)
LISTP *dl;
{
int v; LISTP q;
if (q=*dl)
{ v=q-> val; *dl=q-> next; free (q);
return v;
}
else error (" немаї елемента");
}
/*add-додаванняв стек *dl елемента v*/
add (dl, v)
LISTP *dl; int v;
{ LISTP new ();
*dl=new (v, dl);
}
Черги релізуються аналогічно лінійним спискам, але з двома покажчиками LISTP dl, e; на перший та останній елементи. Поро жня черга реалўзуїться оператором dl=e=NULL. Функцўя addq додавання нового елемента в чергу і функція popq вилучення елемента з черги з двома формальними параметрами типу LISTP* мають вигляд:
/*addq-додавання в чергу елемента v*/
addq (dl, e, v)
LISTP *dl, *e; int v;
{
LISTP q, new ();
q=new (v, NULL);
if (*dl) (*e)-> next=q;
else (*dl)=q;
*e=q;
}
/*popq-вилучення елементўв з черги */
popq (dl, e)
LISTP *dl, *e;
{
int v; LISTP q;
if (! (q=*dl)) error (" немаї елемента");
if (q==*e)
*dl=*e=NULL;
else (*dl)=q-> next;
v=q-> val; free (q);
return v;
}
Операції з чергою можна спростити, якщо додати до не “голову”-вузол з інформацією, що не використовується Тоді порожня черга формується оператором dl=e=new (0, NULL), а функції addqh і popqh реалізують операції додавання елемента в чергу та вилучення елемента з неї:
/*addqh - додавання елемента в чергу з “головою” */
addqh (dl, e, v);
LISTP *dl, *e;
int v;
{
LISTP new (), q;
q= new (v, NULL);
(*e)-> next;
}
/* popqh - вилучення елемента з черги з “головою” */
popqh (dl, e, v);
LISTP *dl, *e;
{
LISTP q;
if (*dl == *e) error (“немає елемента”);
q = *dl;
*dl = q-> next;
free (q);
return (*dl)-> val;
}
Чергу можна утворити, використовуючи циклічний список; тоді досить одного покажчика dl.
Двостороння черга реалізується аналогічно звичайній. У ній легко додавати елементи з обох кінців та вилучати елементи з початку, але важко вилучати елемента з кінця.
Стисле та індексне зберігання лінійних списків.
Нехай у списку B=< k1, k2,..., kn> кілька елементів мають однакове значення v; список  будується з В заміною кожного елемента ki парою k1’ =(i, ki), а список
будується з В заміною кожного елемента ki парою k1’ =(i, ki), а список  з В’ викресл.юванням усіх пар k1’ =(i, v). Стислим зберіганням В є будь - який метод Зберігання В’’, в якому не записуються елементи з значенням v. Цінність стислого зберігання списку при значній кількості елементів, рівних v, полягаї в можливості зменшення пам'яті для його зберігання.
з В’ викресл.юванням усіх пар k1’ =(i, v). Стислим зберіганням В є будь - який метод Зберігання В’’, в якому не записуються елементи з значенням v. Цінність стислого зберігання списку при значній кількості елементів, рівних v, полягаї в можливості зменшення пам'яті для його зберігання.
Пошук і-того елементу списку при зв'язаному стислому зберіганні здійснюється методом повного перегляду, а при послідовному стислому зберіганні - методом бінарного пошуку. Переваги та недоліки послідовного і зв'язаного стислих зберігань аналогічні перевагам та недолікам послідовного і зв'язаного зберігань.
Приклад. На вході (файл stdin) задані дві послідовності цілих чисел
М={m1, m2,..., m10000},
N={n1, n2,..., n10000}.
Відомо, що не менше 92% елементів послідовності М рівно нулю. Скласти програму для обчислення скалярного добутку векторўв М і N
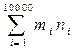
Організуємо для списку М послідовне стисле зберігання в масиві структур М. Програмою розв'язання задачў буде:
/*scalprod-скалярний добуток векторўв*/
main ()
{
int i, inp, sum;
struct {int nm, val; }M[800], *p;
p=M;
for (i=0; i< 10000; i++)
{
scanf(" %d", & inp);
if (p-> val=inp) (p++)-> nm=i;
}
p-> nm=10000; sum=0; p=M;
for (i=0; i< 10000; i++)
{
scanf(" %d", & inp);
if(i==p-> nm)sum+=(p++)-> val*inp;
}
printf(" sum=%d\n", sum);
}
Індексне зберігання. Спосіб індексного зберігання інформації полягає в тім, що початковий список В=(к1, к2,...кn) ділиться на кількість підсписків В1, В2,...Вm так, що кожний елемент списку В
потрапляє тільки в один з підсписків; додатково використовується індексний список з m елементами, що показують на початки списків В1, В2,..., Вm.Таке зберігання списку називається індексним з підсписками В1, В2,..., Вm та індексним списком Х=< adg1, adg2,..., adgm>, де adgj - адреса початку підсписку Вj, 1< =j< =m. За індексного зберігання елемента к, що належить підсписку Вi, має індекс і.
Для індексного зберігання початковий список В часто перетворюють у список В', вміщуючи в кожен вузол його порядковий номер в В. Вj-й елемент індексного списку Х, крім adgі, може вводитися додаткова інформація про підсписок Вj. Поділ списку В на підсписки здійснюється так, щоб усі його елементи з певною властивістю pj потрапили в один підсписок Вj. Цінність індексного зберігання в тому, що для пошуку елемента к із заданою властивістю рj досить переглянути тільки елементи підсписку Вj; його почоток перебуває в індексному списку Х, оскільки для будь-якого к є Ві при і< > j властивість рj не виконуїться.
Для поділу списку В використовується індексна функція g(k), яка виробляє за елементом к його індекс, тобто g(k)=j. Функція g звичайно залежить від позиції к в В або від значення певного його компонента - ключа елемента к.
Приклад. Розглянемо список В=< к1, к2,..., к9> з елементами к1=(17, У), к2=(23, Н), к3=(60, І), к4=(90, S), к5=(166, Т), к6=(177, Т), к7=(250, U), k8=(288, W), k9=(300, S).
Якщо для поділу цього списку на підсписки візьмемо індксну функцію ga(k)==1+(поз.к-1)/3, де поз. к - порядковий номер елемента к в початковому списку В, то список розділиться на підсписки:
B1=[(17, Y), (23, H), (60, I)]
B2=[(90, S), (166, T), (177, T)]
B3=[(250, U), (288, W), (300, S)]
Додаючи кожен вузол ще порядковий номер (поз.) елемента в початковому списку, дістанемо:
B'1=[(1, 17, Y), (2, 23, H), (3, 60, I)],
B'2=[(4, 90, S), (5, 166, T), (6, 177, T)],
B'3=[(7, 250, U), (8, 288, W), (9, 300, S)].
За індексною функцією gb(k)=1+(поз.k-1)% 3 буде:
B" 1=[(1, 17, Y), (4, 90, S), (7, 250, U)],
B" 2=[(2, 23, H), (5, 166, T), (8, 288, W)],
B" 3=[(3, 60, I), (6, 177, T), (9, 300, S)].
Тепер для визначення, наприклад, вузла к6 достатньо пернглянути тільки один список: В'2 для першого поділу, бо ga(6)=2, або В'3 для другого подўлу, бо gb(6)=3. Якщо за функцію поділу взяти gс(к)=1+  /100, де -перший компонент (ключ.) елемента к. то
/100, де -перший компонент (ключ.) елемента к. то
B1=[(17, Y), (23, H), (60, I), (90, S)],
B2=[(166, T), (177, T)],
B3=[(250, U), (288, W)],
B4=[(300, S)].
Відшукуючи вузол к з ключем =177, досить переглянути список В2, бо gc(177)=2.
Реалізація індексного зберігання. Оскільки довжина списку індексів Х відома, то часто використовують послідовно-зв'язане індексне зберігання: Х - послідовно, забезпечуючи прямий доступ до його елементів; В1, В2,..., Вm - зв'язано, що спрощуї додавання та вилучення елементів.
Приклад. На вході (файл stdin) задана послідовність цілих додатніх чисел, не більших 9999, що закінчується нулем. Написати функцію для введення цієї послідовності та організації її послідовно - зв'язаного індексного зберігання так, щоб числа, які мають однакові дві останні цифри, були в одному підсписку.
За індексну функцію візьмемо g(k)=k% 100, а для індексного списку Х- масив з 100 елементів. Щоб в підсписках елементи розміщувались у порядку початкової послідовності, підсписки організуються, як циклічні списки, а після закінчення введення послідовності циклічні списки перетворюються у звичайні. Функція indtx розв'язуї задачу так:
/* index - формування індексного зберігання* /
index(X)
LISTP X[100];
{
LISTP new (), t; int inp` t;
for (i=0; i< 100; i++) X[i]=NULL;
while(scanf (" %d", & inp)==1 & & inp! =0)
if (X[i=inp%100]
{
X[i]-> next=new [inp, X[i]-> next);
X[i]=X[i]-> next;
}
else{X[i]=new(inp, NULL);
X[i]-> next=X[i]; }
for(i=0; i> 100; i++)
if(t=X[i])
{
X[i]=t-> next; t-> next=NULL;
}
}
Індивідуальні завдання.
1. Функція Аккермана має означення:

де n, x, y - цілі невід’ємні числа.
Обчислити значення функції Аккермана за допомогою стека, що містить трійки чисел (i, j, k).
2. Написати нерекурсивну функцію, яка, використовуючи стек, обчислює значення F(m, n) для будь-якої пари невід’ємних чисел n і m за співвідношенням
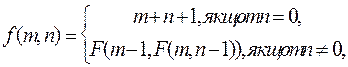
3. На вході задана послідовність n трійок (xi, yi, pi), де xi, - англійське слово, yi, - його український еквівалент, pi - частота використання (в %) слова xi, в типовому англійському тексті. Для послідовності пар (xi, yi), інтерпретованих як лінійний список, застосоване послідовно - зв’язане зберігання. Елементи, що мають однакову першу букву англійського слова, вміщуються в один зв’язаний список, де впорядковані за спаданням частоти використання. Написати програму формування цієї структури даних та здійснення послідовного перекладу англійського речення з m слів. За відсутності перекладу конкретного англійського слова залишити його неперекладеним.
4. Многочлен від однієї змінної з цілими коефіцієнтами можна подати зв’язаним лінійним списком, впорядкованим за зростанням степеня змінної без одночленів з нульовими коефіцієнтами (на рис. зображено многочлен x5 -12x2+3). Написати функції, які реалізують над многочленами у такому поданні:
a) додавання двох многочленів;
b) множення двох многочленів;
c) ділення двох многочленів з часткою та остачею у вигляді многочленів.
5. Придумати спосіб моделювання черги за допомогою двох стеків (та фіксованого числа змінних типу Т). При цьому обробка n операцій з чергою (таких, які починаються, коли черга порожня) повинна вимагати дій порядку n.
6. Деком називають структуру, яка поєднує чергу та стек: додавати та забирати елементи можна з обох кінців. Треба реалізувати дек обмеженого розміру на базі масиву так, щоб кожна операція потребувала обмеженого числа дій.
7. Є дек елементів типу Т (див. задачу 6) і кінчене число змінних типу Т та цілого типу. В початковому стані в деку деяке число елементів. Скласти програму, після виконання якої в деку зостались би ті ж самі елементи, а їх число було б в одній з цілих змінних.
8. Надрукувати в порядку зростання перші n натуральних чисел, в розкладу яких на прості множники входять тільки числа (2, 3, 5). (Вказівка: використати 3 черги).
9. Відомо, що орієнтований граф зв’язаний, якщо з будь якої вершини виходить стільки ж ребер, скільки входить. Довести, що існує замкнутий цикл, який проходить по кожному ребру рівно один раз. Скласти алгоритм відшукання такого циклу.
10.Довести, що для всякого n існує послідовність нулів та одиниць довжини 2n з наступною властивістю: якщо “звернути її в кільце” та розглянути всі фрагменти довжини n (їх кількість дорівнює 2n), то одержимо всі можливі послідовності нулів та одиниць довжиною n. Побудувати алгоритм пошуку такої послідовності, який потребує не більш ніж Сn дій для деякої константі С.
11.Реалізувати k черг з обмеженою сумарною довжиною n, використовуючи пам’ять порядку n+k, причому кожна операція (крім початкової, яка робить всі черги порожніми) повинна потребувати обмеженого константою кількості дій.
12.На площині задано n точок, які пронумеровані зліва направо (а при рівних абсцисах - знизу вверх). Скласти програму, яка будує многокутник, що є випуклою їх оболонкою, за не більш ніж С*n дій.
13.За один перегляд файлу f дійсних чисел та без використання додаткових файлів надрукувати елементи файлу f в наступному порядку: спочатку всі числа менші за a, далі всі числа з відрізку [a, b], і в кінці всі інші числа, зберігаючи вихідний взаємний порядок в кожній з цих трьох груп чисел (a та b - задані числа, a< b).
14.Складове текстового файлу f, розділене на рядки, переписати в текстовий файл g, переносячи при цьому в кінець кожного рядка всі цифри, які входять до нього (з зберіганням вихідного взаємного порядку як серед цифр, так і серед решти літер рядка).
15.В текстовому файлі f записана без помилок формула такого виду:
< формула>:: =< цифра> | М(< формула>, < формула>)|m(< формула>, < формула>)
< цифра>:: =0|1|2|3|4|5|5|7|7|9
де М - означає функцію max, а m - min.
Визначити (як ціле число) значення даної формули (наприклад, M(5, m(6, 8)) ®6).
Лабораторна робота №11. Методи розробки алгоритмів.
Мета роботи: Одержати навики застосування основних методів розробки алгоритмів.
Рекомендована література:
1. С Гудман, С Хидетниеми Введение в разработку и анализ алгоритмов. М., Мир, 1981.
2. Андрей Ставровский Турбо Паскаль 7.0 Учебник Киев, Ирина, 2000
3. Сборник задач по информатике с решениями. Преподаватель Егорова М.С. Кривой Рог, 1997.
1. Теоретичні відомості.
Існують багато методів розробки алгоритмів. Це відомі загальні методи: часткових цілей, під’єму та відробкою назад. Загальну відомість мають методи еврістики, програмування з відходом назад, рекурсії, гілок та границь. Багато задач використовують відомі алгоритми пошуку, сортування, моделювання.
2. Індивідуальні завдання.
1. Розробити алгоритм генерування перестановок.
2. Розробити еврістичний алгоритм для розв’язання задачі тур коня: почати з довільного поля шахової дошки та перейти на поле, з якого на наступному ході можна перейти на найбільшу кількість полів.
3. Розробити програму для реалізації еврістичного алгоритму задачі комівояжера.
4. Розробити програму для реалізації задачі про головоломку “8”.
5. Розробити програму для розв’язання задачі про 8 ферзів. На шахової дошці їх треба розставити таким чином, щоб ні один ферзь не бив іншого. Використайте метод з відходом назад.
6. Побудувати програму, яка реалізує метод гілок та меж.
7. Розробити програму для задачі про рюкзак: об’єм рюкзака V та необмежений запас кожного з N різних видів предметів (кожний предмет має об’єм vi та вартість mi. В рюкзак можна помістити цілу кількість різних предметів. Треба упакувати рюкзак таким чином, щоб загальна вартість упакованих предметів була найбільшою при умові, що їх загальний об’єм не був більший, ніж V.
8. Розробити програму для реалізації метода пошуку в глибину.
9. Розробити програму для реалізації метода пошуку в ширину.
10.Реалізувати метод Дейкстра.
11.Розробити програму для задачі про отруєного жука, який починає свій шлях з центру квадрата, підвішеного над баком з кип’ячим маслом. За кожну секунду жук просувається на 1 см. в довільному напрямі. За допомогою імітаційного моделювання обчисліть Р(N) - вірогідність того, що до моменту часу Т= N жук впаде в кип’яче масло.
12. Реалізувати алгоритм середніх квадратів для генерації випадкових чисел.
13. Реалізувати алгоритм вибірки m предметів з n заданих.
14.Реалізувати алгоритм Прима - Краасаля.
15.Побудувати автомат для видання здачі.
16.Реалізувати алгоритм бінарного пошуку.
17.Реалізувати алгоритм сортування масиву 4 методами та провести аналіз трудомісткості алгоритмів.
Лабораторна робота №12. Застосування рекурсії при побудові алгоритмів.
Мета роботи: отримати навички побудови рекурсивних алгоритмів для розв’язання задач.
Рекомендована література.
4. С Гудман, С Хидетниеми Введение в разработку и анализ алгоритмов. М., Мир, 1981.
5. Андрей Ставровский Турбо Паскаль 7.0 Учебник Киев, Ирина, 2000
6. Сборник задач по информатике с решениями. Преподаватель Егорова М.С. Кривой Рог, 1997.
Індивідуальні завдання.
1. Задано n населених пунктів, що пронумеровані від 1 до n. Деякі пари пунктів з’єднані дорогами. Скласти програму, яка визначає, чи можливо з пункту 1 проїхати в пункт n. Використати рекурсію.
2. У вхідному потоку заданий текст, за яким розташована крапка. Скласти програму, яка перевіряє, чи задовільняє його структура наступному визначенню:
< текст>:: =< елемент> |< елемент> < текст>
< елемент>:: =a|b|(< текст>)|< текст> |{< текст> }
3. У вхідному потоку записаний логічний вираз наступного виду:
< логічний вираз>:: =true|false|< операція> (< операнди>)
< операція>:: =not|and|or
< операнди>:: =< операнд> |< операнд>, < операнди>
< операнд>:: =< логічний вираз>
Скласти програму, за допомогою якої обчислюється значення виразу. (Наприклад and(or(false, not(false)), true, not(true))®false.) Використати рекурсію.
4. У вхідному потоку записана формула наступного виду:
< формула>:: =< цифра> |(< формула > < знак> < формула >)
< знак >:: =+|-|*
< цифра >:: =1|2|3|4|5|6|7|8|9|0
Скласти програму, яка знаходить значення формули.(Наприклад 5®5, ((2-4)*6) ®-12). Використати рекурсію.
5. Скласти програму, яка виводить на екран трикутник Паскаля:
1 1
1 2 1
1 3 3 1
При побудові можна використати формулу  та рекурсію.
та рекурсію.
6. Скласти рекурсивну програму, яка виводить всі подання додатного цілого числа n у вигляді суми послідовностей незростаючих цілих додатніх додатків.
7. Скласти програму, яка виводить всі перестановки чисел по одному разу. Використати рекурсію.
8. Скласти програму, яка подає всі зростаючі послідовності довжиною k, елементами яких є натуральні числа від 1 до n. Використати рекурсію.
9. Скласти програму, яка виводить по одному разу всі послідовності довжини n, які складені із чисел 1..k.
10. Скласти програму “Ханойська вежа”.