Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Організація пам’яті
|
|
План
1 Адресна пам’ять
2 Стекова пам’ять
3 Асоціативна пам’ять
1 Розглянемо методи розміщення й пошуку інформації в основній пам'яті мікро-ЕОМ. За цією ознакою розрізняють адресну, стекову й асоціативну пам'ять.
Адресна пам'ять. У базової ЕОМ й її мікропрограмному пристрої керування слова інформації (дані, команди й мікрокоманди) розміщаються в осередках пам'яті різної довжини й відшукуються за адресою (номеру) цих осередків. Подібний спосіб розміщення й пошуку інформації найчастіше використовуються при організації основної пам'яті ЕОМ. Але незважаючи на те, що різні мікро-ЕОМ можуть обробляти слова різної довжини, основна їхня пам'ять звичайно має байтову організацію.
Для мікро-ЕОМ, що працює з 8-розрядними словами, байтова організація основної пам'яті є природною. Якщо регістр адреси й лічильник команд такої мікро-ЕОМ мають, наприклад, 16 розрядів, то вона може мати пам'ять із 216 байт. Кожний з байтів такої пам'яті однозначно визначається за допомогою 16-розрядної адреси (рис. 52.1, а). Розряди в слові (байті) нумеруються справа наліво починаючи з нуля.
Якщо мікро-ЕОМ працює з 16-розрядними словами й має 16-розрядну шину даних, то при обміні даними з пам'яттю по цій шині пересилаються 2-байтові слова. При цьому байт із молодшою адресою може розташовуватися в слові або праворуч (рис. 52.1, б), або ліворуч (рис. 52.1, в).
В пам’яті, організованій по типу, зображеному на рис. 52.1, б, кожне 16-розрядне слово складається із двох послідовно розташованих байтів, перший з яких має парну адресу (границя слова). Наприклад, байти 2 й 3 утворять одне повне слово, а байти 3 й 4 - ні. У командах, призначених для виконання операцій над словами, повинні задаватися парні адреси. Якщо ж операції виконуються над байтами, то адреси можуть бути будь-якими. При роботі з такою пам'яттю лічильник команд мікропроцесора після вибірки кожної команди повинен нарощуватись на 2, а не на 1, як у базовій ЕОМ.
| 7 0 | 15 8 | 7 0 | 15 8 | 7 0 | |||||
| П | А | П | |||||||
| А | ‘ | М | П | А | |||||
| М | Т | Я | М | ‘ | |||||
| ‘ | Ь | Я | Т | ||||||
| Я | Ь | ||||||||
| Т | |||||||||
| Ь | … | … | |||||||
| … | |||||||||
 а б в
а б в
У пам'яті, організованій по типу, показаному на рис. 52.1, в, легше можна рішити ряд практичних проблем по зберіганню символів, закодованих у послідовних байтах (полегшити роботу з текстами: заголовки таблиць, назви вихідних даних і результатів і т.п.).
2 Стекова пам'ять. Вона складається з осередків, зв'язаних один з одним розрядними ланцюгами передачі слів. Обмін інформацією між мікро-ЕОМ і стековою пам'яттю (стеком) виконується або через верхній осередок - вершину стека (рис. 52.2), або через нижній осередок - дно стека (рис. 52.3). У першому випадку при записі нового слова (команди, числа, символу й т.п.) усі раніше записані слова зрушуються на один осередок униз, а нове слово записується у вершину стека. Зчитування можливо тільки з вершини стека й виконується з видаленням (після зчитування всі слова зрушуються на один осередок нагору) або без видалення зчитувального слова. Таку пам'ять часто називають пам'яттю типу LІFO (Last-In First-Out - останнім увійшов, першим вийшов). В другому випадку слова записуються також у вершину стеку і зрушуються на один осередок униз, але зчитування виконується із дна стека. Таку пам'ять часто називають пам'яттю типу FІFO (First -In First-Out - першим увійшов, першим вийшов).
Стекова пам'ять дуже зручна для спрощення рішення багатьох завдань, що виникають при роботі з підпрограмами, обслуговуванні переривань, побудові трансляторів і т.д. Однак апаратна реалізація стека не завжди доцільна, і тому в більшості мікро-ЕОМ стік моделюють. При цьому в якості стека звичайно використовують просто частину адресної пам'яті, що дозволяє міняти ємність стека й заощаджує апаратуру.

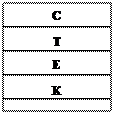 |


 |

 | |
 | |||||||
| |||||||
 | |||||||
 | |||||||
| |||||||


|
 |

 |
 | |
| |
| |
|
 | 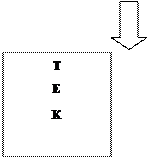 | | |||||
 | |||||||
| |||||
 | |||||
|
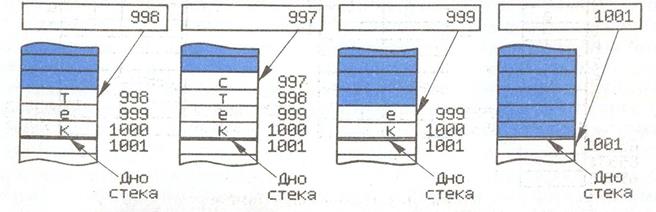
Робота стека забезпечується за допомогою спеціального регістра процесора - показника стека (SP) (рис. 52.4), що містить адресу плаваючої вершини стека. У процесі виконання команд, що використовують стек, вміст SP автоматично збільшується або зменшується на 1 (при 1-байтовых словах пам'яті), на 2 (при 2-байтовых словах пам'яті) і т.д. Так, у мікро-ЕОМ, що працює з 1-байтовими словами, обмін даними між процесором і стеком відбувається такий способом:
при завантаженні нового слова спочатку виконується зменшення вмісту SP на 1, а лише потім запис цього слова в осередок, на яку вказує модифікований SP;
при зчитуванні слова зі стека спочатку виконується читання вмісту осередку, на який вказує SP, а лише потім збільшення SP на 1.
 |
|
Отже, та обставина, що моделюємий стік росте не зверху вниз (до дна стека), а знизу нагору (від дна стека), не порушує алгоритму функціонування такої пам'яті. На рис. 52.4 показаний стек, організований у пам'яті з 1-байтовими словами. Дно стека розташоване в осередку 1000, тому що до початку роботи мікро-ЕОМ в SP була записана адреса 1001 (стік порожній). При завантаженні в стек першого слова вміст SP зменшиться на 1 і це слово потрапить в осередок 1001 - 1 = 1000, тобто на дно стека.
3 Асоціативна пам'ять. Вона забезпечує можливість вибору інформації з її вмісту (по асоціативній ознаці). Пояснимо це на прикладі.
Нехай пам'ять ЕОМ складається з досить довгих осередків, у яких зберігається інформація про автомобілі, що стоять на обліку в ДАІ:
| Марка | Колір | Номерний знак | Рік випуску | Власник | Адреса власника |
| Район | Вулиця | Буд. | Квартира |
Припустимо тепер, що необхідно терміново одержати відомості про всі чорні автомобілі марки ВАЗ, тобто вибрати з пам'яті, декодувати і надрукувати окремі складові частини (поля) всіх осередків пам'яті, перші десять розрядів яких містять код:
0101001001,
де 010100 - код автомобіля ВАЗ, а 1001 - код чорного кольору.
Якщо використовується адресна пам'ять або стік, то процедура пошуку й виводу потрібної інформації зводиться до послідовного зчитування вмісту окремих осередків пам'яті, виділенню за допомогою маски
111111111100...00
десяти його перших бітів, порівнянню виділених бітів з відшукуваним кодом, (0101001001) і виводу інформації при позитивному результаті порівняння. Це дуже нераціональна процедура, тому що при малому числі чорних " Жигулі" серед сотень тисяч автомобілів (або навіть при відсутності таких " Жигулі") ЕОМ повинна буде прочитати й проаналізувати сотні тисяч осередків пам'яті.
При використанні асоціативної пам'яті час пошуку різко скорочується. Крім звичайних регістрів в асоціативній пам'яті (АП) розташовані додаткові регістри асоціативної ознаки (РО) і маски (РМ), число розрядів яких збігається із числом розрядів осередків АП, а також регістр збігу (PЗ) із числом розрядів, рівним числу осередків АП. Кожний з розрядів РО і РМ пов'язаний з відповідними розрядами осередків АП, і якщо і -й розряд РМ містить одиницю (незамаскований), то на і -і розряди всіх осередків АП надходить вміст і -го розряду РО.
Запам'ятовувальні елементи АП містять логічні схеми, що дозволяють порівнювати зберігаєме значення зі значенням відповідного незамаскованого розряду РО. При повному збігу інформації, що зберігається в незамаскованих розрядах РО й j -ому осередку пам'яті, логічні схеми цього осередку видадуть сигнал, що встановить 1 в j -ому розряді PЗ. А тому що процес порівняння інформації проходить одночасно у всіх осередках АП, то за час одного звертання до такої пам'яті будуть виявлені (і відзначені одиницями в PЗ) всі осередки пам'яті, що містять потрібну інформацію. Вміст регістра збігу надходить на формувач результату, що видає два сигнали, що відповідають наявності або відсутності шуканої інформації й наявності однієї або декількох осередків, що містять цю інформацію. При наявності шуканої інформації можна приступитися до висновку вмісту лише тих осередків, які відзначені одиницями в PЗ.
Для одержання інформації про чорний ВАЗ в асоціативну пам'ять посилають слова
111111111100...00 й 010100100100...00,
розташовані в регістрах маски й асоціативної ознаки відповідно. Потім зчитується ознака наявності (відсутності) у пам'яті шуканої інформації, і якщо вона дорівнює одиниці (дані про чорні " Жигулі" є), то виконуються читання й вивід на печать вмісту всіх осередків, які відзначені одиницею в регістрі збігу.
Деяке ускладнення запам'ятовувальних елементів і логічних схем асоціативної пам'яті дозволяє виконувати пошук слів або чисел, розташованих у певних границях, пошук однокорінних слів (при перекладі або інших маніпуляціях з текстом) і т.п.
Домашнє завдання:
[5] С. 108-111