Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Иерархическая и сетевая даталогические модели СУБД
|
|
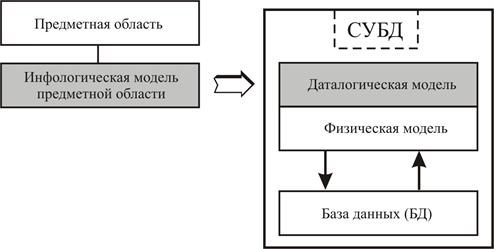
Каждая БнД содержит и обрабатывает информацию из конкретной прикладной области, представляющей интерес для определенных приложений. Описание предметной области без акцента на ее последующие БнД - реализации определяет инфологическую модель предметной области (рисунок 5.3). Инфологическая модель является исходной для построения даталогической модели БД и служит промежуточной моделью для специалистов предметной области (для которой создается БнД) и администратора БД в процессе проектирования и разработки конкретной БнД.
|
| Рисунок 5.3 – Принципиальная организация системы обработки информации (СОИ) на основе БД-технологии |
Под даталогической понимается модель, отражающая логические взаимосвязи между элементами данных безотносительно их содержания и физической организации. При этом даталогическая модель разрабатывается с учетом конкретной реализации СУБД, а также с учетом специфики конкретной предметной области на основе ее инфологической модели. Для конкретной реализации даталогической модели проектируется физическая модель, (отображающая первую на конкретные программные и аппаратные средства ОС, внешняя память, работа с данными на физическом уровне и т.д.). Наполненная конкретной информацией физическая модель и составляет собственно БД. Система, обеспечивающая соответствующее совместное функционирование указанных компонент, и составляет суть конкретной СУБД.
Современные СУБД допускают целый ряд классификаций в зависимости от уровня их рассмотрения (в целом либо по совокупностям их функциональных характеристик): по интерфейсу с пользователем в зависимости от поддерживаемых моделей, по назначению и режимам функционирования, по способу обработки информации и т.д. Мы кратко остановимся на моделях даталогического уровня, который берется за основу большинства современных классификаций СУБД.
Обычно различают три класса СУБД, обеспечивающих работу иерархических, сетевых и реляционных моделей. Однако различия между этими классами постепенно стираются, причем, видимо, будут появляться и другие классы, что вызывается, прежде всего, интенсивными работами в области баз знаний (БЗ) и объектно-ориентированной инфотехнологией, о которой будет идти речь ниже. Поэтому традиционной классификацией пользуются все реже, но мы пока будем придерживаться именно ее, как наиболее устоявшуюся. Каждая из указанных моделей обладает характеристиками, делающими ее наиболее удобной для конкретных приложений. Одно из основных различий этих моделей состоит к том, что для иерархических и сетевых СУБД их структура часто не может быть изменена после ввода данных, тогда как для реляционных СУБД структура может изменяться в любое время. С другой стороны, для больших БД, структура которых остается длительное время неизменной, и постоянно работающих с ними приложений с интенсивными потоками запросов на БД-обслуживание именно иерархических и сетевых СУБД могут оказаться наиболее эффективными решениями, ибо они могут обеспечивать более быстрый доступ к информации БД, чем реляционные СУБД.
Однако прежде чем переходить непосредственно к иерархическим СУБД, кратко рассмотрим файловую модель, неправомерно относимую довольно часто к СУБД. Файловая модель представляет собой набор файлов данных определенной структуры, но связь между данными этих файлов отсутствует. Естественно, программные средства работы с таким образом организованной инфобазой могут устанавливать связь между данными ее файлов, но на концептуальном уровне файлы модели являются независимыми. Системы, обеспечивающие работу с файловыми инфобазами, называют системами управления файлами (СУФ) и они оказываются весьма эффективными во многих приложениях. СУФ используются на всех классах ЭВМ, но особенно они распространены для обработки информации на ПК. Файловые системы легко осваиваются, достаточно просты и эффективны в использовании и, как правило, для работы с ними используются простые языки запросов либо и вовсе ограничиваются набором программ-утилит. Такие системы обычно поддерживают работу с небольшим числом файлов, содержащих ограниченное число записей с небольшим количеством полей.
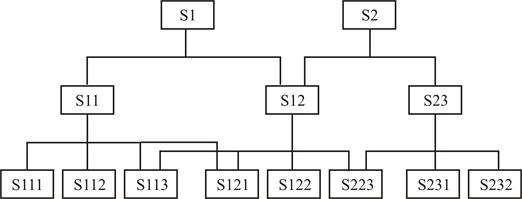
Иерархические модели СУБД имеют древовидную структуру, когда каждому узлу структуры соответствует один сегмент, представляющий собой поименованный линейный кортеж полей данных. Каждому сегменту (кроме Sl-корневого) соответствует один входной и несколько выходных сегментов (рисунок 5.4). Каждый сегмент структуры лежит на единственном иерархическом пути, начинающемся от корневого сегмента.
 а)
а)
|
 б)
б)
|
| Рисунок 5.4 – Структура иерархической (а) и сетевой (б) СУБД |
Для описания такой логической организации данных ЯОД достаточно предусматривать для каждого сегмента данных только идентификацию входного для него сегмента. Так как в иерархической модели каждому входному сегменту данных соответствует N выходных, то такие модели весьма удобны для представления отношений типа 1: N в предметной области. Следует отметить, что в настоящее время не разрабатываются СУБД, поддерживающие на концептуальном уровне только иерархические модели. Как правило, использующие иерархический подход системы допускают связывание древовидных структур между собой и/или установление связей внутри них. Это приводит к сетевым даталогическим моделям СУБД. К основным недостаткам иерархических моделей следует отнести: неэффективность реализации отношений типа N: N, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. В связи с этими недостатками ранее созданные иерархические СУБД подвергаются существенным модификациям, позволяющим поддерживать более сложные типы структур и, в первую очередь, сетевые и их модификации.
Сетевая даталогическая модель СУБД во многом подобна иерархической: если в иерархической модели (смотри рисунок 5.4а) для каждого сегмента записи допускается только один входной сегмент при N выходных, то в сетевой модели для сегментов допускается несколько входных сегментов наряду с возможностью наличия сегментов без входов с точки зрения иерархической структуры. На рисунке 5.4б представлен простой пример сетевой структуры, полученной на основе модификации иерархической структуры (смотри рисунок 5.4а). Графическое изображение структуры связей сегментов в такого типа моделях представляет собой сеть. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД средствами ЯОД.
Таким образом, под сетевой СУБД понимается система, поддерживающая сетевую организацию: любая запись, называемая записью старшего уровня, может содержать данные, которые относятся к набору других записей, называемых записями подчиненного уровня. Возможно обращение ко всем записям в наборе, начиная с записи старшего уровня. Обращение к набору записей реализуется по указателям. В рамках сетевых СУБД легко реализуются и иерархические даталогические модели. Сетевые СУБД поддерживают сложные соотношения между типами данных, что делает их пригодными во многих различных приложениях. Однако пользователи таких СУБД ограничены связями, определенными для них разработчиками БД-приложений. Более того, подобно иерархическим сетевые СУБД предполагают разработку БД-приложений опытными программистами и системными аналитиками.
Для работы с записями в БД CODASYL-модели используется DML-язык манипулирования данными. Сетевая CODASYL-модель накладывает меньше ограничений на логическую структуру БД, чем другие сетевые модели, что существенно облегчает отображение предметной области в даталогическую модель СУБД и расширяет круг ее приложений.
Среди недостатков сетевых СУБД следует особо выделить проблему обеспечения сохранности информации в БД, решению которой уделяется повышенное внимание при проектировании сетевых БД. Примерами известных сетевых СУБД являются: DBMS, IDS, TOTAL, IDMS,