Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Реляционные даталогические модели СУБД
|
|
СУБД реляционного типа являются наиболее распространенными на всех классах ЭВМ, а на ПК занимают доминирующее положение. Реляционной называется СУБД, в которой средства управления БД поддерживают реляционную модель данных. Концепция реляционной модели была предложена в 1970г. Е. Коддом и имеет большое значение в деле организации работы с БД. Данная модель позволяет определять: (1) операции по запоминанию и поиску данных; (2) ограничения, связанные с обеспечением целостности данных. Модель основана на математическом понятии отношения, расширенном за счет значительного добавления специальной терминологии и развития соответствующей теории. В такой модели общая структура данных (отношение) может быть представлена в виде таблицы, в которой каждая строка значений (кортеж) соответствует логической записи, а заголовки столбцов являются названиями полей (элементов) записи. Операции запоминания и поиска делятся на две группы: операции на множествах (объединение, пересечение, разность, произведение) и реляционные операции (выбрать, спроецировать, соединить, разделить). Любой язык манипулирования данными, обеспечивающий все эти операции, является реляционно полным. Для увеличения эффективности работы во многих СУБД реляционного типа приняты ограничения, соответствующие строгой реляционной модели. Многие реляционные СУБД представляют файлы БД для пользователя в табличном формате - с записями в качестве строк и их полями в качестве столбцов. В табличном виде информация воспринимается значительно легче. Однако в БД на физическом уровне данные храняться, как правило, в файлах, содержащих последовательности записей. Основным преимуществом реляционных СУБД является возможность связывания на основе определенных соотношений файлов БД. Со структурной точки зрения реляционные модели являются более простыми и однородными, чем иерархические и сетевые. В реляционной модели каждому объекту предметной области соответствует одно или более отношений. При необходимости определить связь между объектами явно, она выражается в виде отношения, в котором в качестве атрибутов присутствуют идентификаторы взаимосвязанных объектов. В реляционной модели объекты предметной области и связи между ними представляются одинаковыми информационными конструкциями, существенно упрощая саму модель.
| СУБД считается реляционной при выполнении следующих двух условий, предложенных еще Э.Коддом: (1) поддерживает реляционную структуру данных и (2) реализует по крайней мере операции селекции, проекции и соединения отношений. В последующем был создан целый ряд реляционных СУБД, в той или иной мере отвечающих данному определению. Многие СУБД представляют собой существенные расширения реляци-онной модели, другие являются смешанными, поддерживая нес-колько даталогических моделей (например, уже упомянутые NOMAD, ИНТЕРБАЗА). |

| |
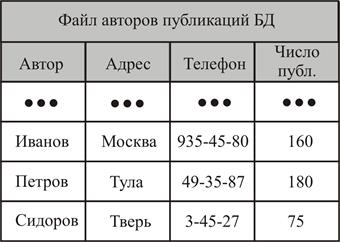
| Рисунок 5.5 – Простой пример, иллюстрирующий принцип реляционной модели |
Для работы с данными реляционные СУБД используют как языки, основанные на реляционной алгебре, так и другие типы языков, включая процедурные (Cobol, С и др.) и непроцедурные (Prolog, Lisp).
Суть реляционной СУБД можно пояснить на следующем простом примере (рисунок 5.5).В некоторой реляционной БД (РБД) имеются два файла авторов и публикаций, каждый из которых содержит определенное число записей, состоящих из фиксированного числа полей (соответственно 4 и 5), представляющих данные по соответствующим элементам предметной области (рисунок 5.5). Можно сказать, что определены два отношения (файла), имеющие общий элемент - значения поля Автор. Операции реляционной алгебры могут объединять два типа записей по этому общему элементу. Например, в результате соединения запись Петров может представится в следующем виде:
Петров < Тула> < 49-
35-87> < 180> < Проблема...> < книга> < 23.09> < 35>......
т.е. к сведениям об авторе добавляются сведения о всех его публикациях, имеющихся в РБД. Связь между записями допускается по нескольким полям, позволяя образовывать достаточно сложные операции. Поля данных, связывающие вместе две записи, могут быть уникальными для данной пары, но могут дублироваться и во многих других записях. Они могут повторяться неоднократно, связывая между собой записи. Аналогичным образом можно проиллюстрировать выполнение в реляционной модели операций проекции и селекции.
Реляционная СУБД должна четко отслеживать взаимосвязи записей в БД во избежание потери или искажения информации. С этой целью СУБД постоянно пересчитывает число связей для каждой записи БД в прямом и обратном направлениях, что требует существенных временных затрат для больших БД. Простота и стройность реляционной алгебры делают ее весьма привлекательной для организации реляционных БД, что мы и видим, прежде всего, для класса ПК, Однако в действительности реальные данные предметной области не укладываются в указанную модель (например, отношения могут содержать повторяющиеся записи и т.д.). Поэтому наряду с сугубо реляционными существуют и другие даталогические модели СУБД и их различные модификации и сочетания, обеспечивая широкий круг решаемых на их основе информационных, коммерческих, управленческих, финансовых, вычислительных и других типов задач. Из наиболее известных примеров реляционных СУБД можно отметить такие, как: RAPPORT, dBase, DB/ 2, ORACLE, QBE, INGRES, SQL/DS, Paradox, R: Base и ряд других.
Массовое развитие класса ПК оказало весьма существенное влияние на развитие инфотехнологии и БД-технологии в частности, привнося элементы последней в массовую инфотехнологию. Прежде всего, этому способствовало развитие мощной индустрии по созданию разнообразных СУБД для ПК. Если создание СУБД для ЭВМ общего назначения и (в значительной мере) мини-ЭВМ занимало длительный промежуток времени и число таких коммерческих СУБД было невелико - практически весь их перечень был на слуху у специалистов по компьютерной инфотехнологии, то с появлением класса ПК наряду с мощным развитием для них ПС различного назначения начали быстро появляться СУБД. При этом БД-технология начала активно проникать и в ПС другого назначения (электронные таблицы, интегрированные и статистические пакеты и т.д.). К БД-технологии были приобщены широкие круги пользователей ПК. Во многих разработках для ПК начали применяться собственные СУБД различных организации и назначения. Так при разработке пакета Metrolog для первого отечественного ПК ИСКРА 226 нами была создана хорошо зарекомендовавшая себя СУБД смешанного типа, поддерживающая файловую и иерархическую даталогические модели. На наш взгляд, ряд причин способствовал такому массовому использованию БД-технологии:
- массовое использование ПК в приложениях, предопределяющих работу с БД;
- резкое уменьшение цикла разработки ПС из-за персонального характера работы;
- наличие достаточно развитых системных и инструментальных средств;
- наличие внешней памяти большой емкости на " винчестерах".
Эти и другие причины обеспечили как широкий спрос на СУБД для ПК, так и хорошие предпосылки для его быстрого удовлетворения. Наряду с мощными фирмами, специализирующимися на разработке коммерческих СУБД для ПК (Ashton-Tate, Microrim, Fox Software, Nantucket и др.), к разработкам и/или адаптации уже готовых СУБД для ПК приступили и крупные фирмы, ранее ориентированные в этой области на приложения к ЭВМ других классов (Oracle, IBM, Relational Technology и др.). Все это способствовало интенсивному проникновению БД-технологии в массовую инфообработку. С другой стороны, широкое использование ПК в весьма обширном спектре прикладных областей способствовало выдвижению к СУБД целого ряда актуальных требований и, в первую очередь, по повышению уровня интерфейсов с пользователем и другими приложениями.
Разработанное в настоящее время большое число различного назначения СУБД позволяет создавать и эксплуатировать системы БД на всех классах и типах ЭВМ, поддерживая различные даталогические модели и обеспечивая нужды широкого круга приложений. В табл. 12 приведена сводка из 20 наиболее популярных СУБД.
Таблице 5.1 представляет наиболее популярные СУБД с краткой их характеристикой; в ней приняты следующие сокращения: О - общего назначения и М - мини-ЭВМ. При этом можно с полной уверенностью определить двух явных лидеров на рынке СУБД: dBase и ей подобные системы для класса ПК и ORACLE для мини - и общего назначения ЭВМ.
Средства современных СУБД настолько разнообразны, что способны удовлетворить потребности самого широкого круга пользователей - от профессионала в области разработки систем БД различных типа и назначения до пользователя, не обладающего достаточным уровнем компьютерной грамотности.
Таблица 5.1 – Популярные СУБД и их характеристики
| № | СУБД | Класс ЭВМ | Тип модели БД | Язык запросов |
| Adabas | 0, М, ПК | Сетевая | Natural, SQL | |
| Clipper | ПК | Реляционная | Собственный | |
| DataBase | ПК | Реляционная | DQL | |
| dBase | ПК | Реляционная | DQL | |
| DB_Vista | ПК | Сетевая | SQL | |
| FFS File | ПК | Файловая | Собственный | |
| FoxBase+ | ПК | Сетевая | Собственный | |
| FoxPro | ПК | Сетевая | Собственный | |
| IDMS | О | Сетевая | Собственный | |
| IMS/VS | О | Иерархическая | CICS | |
| INGRES | М, ПК | Реляционная | SQL, QUEL | |
| ORACLE | О, М, ПК | Реляционная | SQL | |
| Paradox | ПК | Реляционная | PAL, QBE | |
| Q& A | ПК | Файловая | Собственный | |
| R: Base | ПК | Реляционная | SQL, собственный | |
| Reflex | ПК | Файловая | Собственный | |
| SQL/DS | О | Реляционная | SQL, QBE | |
| TOTAL | О | Сетевая | DML | |
| ПАЛЬМА | О, М, ПК | Реляционная | КРЕЗ | |
| ИНТЕРБАЗА | ПК | Смешанная | SQL/IB, QBE/IB |
В первую очередь, это относится к СУБД, созданным для класса ПК. Эти СУБД характеризуются не только своим количеством, но и функциональным разнообразием: от простых файловых систем до функционально полных СУБД, в основном реляционного типа. Многие из коммерческих СУБД поддерживают многопользовательскую работу и работу в сетях ЭВМ, как локальных, так и глобальных. К средствам, непосредственно относящимся к СУБД, можно отнести и многочисленные средства их окружения: генераторы и конверторы данных и программ, компиляторы языков программирования БД-приложений, генераторы создания различного назначения и уровня интерфейсов с БД в рамках традиционных ЯВУ и т.д.
Такое многообразие инструментальных и прикладных средств по СУБД позволяет выбирать наиболее адекватные нуждам пользователя, обеспечивая эффективное использование вычислительных ресурсов и существенное сокращение сроков разработки конкретных БД-технологий. В подавляющем большинстве СУБД для ПК ориентированы на интерактивный режим работы с пользователем, широко используя удобные и дружелюбные системы интерфейсов на основе простых и понятных меню. В СУБД, поддерживающих языки программирования БД-приложений, средства такого интерфейса избавляют пользователя от необходимости знания синтаксиса языка для обеспечения требуемых функций. Ряд популярных СУБД предусматривают несколько уровней интерфейса, обеспечивающих работу с ними различной квалификации пользователей (dBase IV, Paradox, R: Base и др.). Большое внимание уделено эффективной системе Help-информации по СУБД, включающей электронные краткие обучающие курсы с демонстрацией наиболее часто используемых приемов работы с конкретным пакетом.
Интенсивное расширение компьютерной инфотехнологии ставит перед дальнейшим развитием СУБД целый ряд новых требований, во многом связанных с вопросами стандартизации. Это относится не только к СУБД, но и к ПС других типов. В отношении же СУБД это прежде всего относится к стандартизации эталонной модели управления данными, предусматривающей четкую классификацию основных вопросов стандартизации СУБД в зависимости от функциональных особенностей и уровня описания данных на разных стадиях проектирования. Можно предполагать, что последующее развитие СУБД будет ориентироваться на рекомендации международных стандартов относительно языков БД и средств доступа к удаленным БД, а также интерфейсов с системами программирования, ориентированными на ИИ-проблематику. Новые интересные аспекты БД-технологии появляются на основе объектно-ориентированной технологии программирования и обработки информации.
Лекция 6 (2 часа)
Объектно-ориентированные СУБД (ООСУБД)
Сложные объекты
Понятие идентичности объектов
Понятие инкапсуляции
Понятие класса и типа