Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Матричная форма записи
|
|
В матричной форме модель парной регрессии имеет вид:
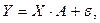 (3.9)
(3.9)
где Y - вектор-столбец размерности  наблюдаемых значений зависимой переменной;
наблюдаемых значений зависимой переменной;
Х – матрица размерности 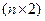 наблюдаемых значений факторных признаков. Дополнительный фактор х0 вводится для вычисления свободного члена;
наблюдаемых значений факторных признаков. Дополнительный фактор х0 вводится для вычисления свободного члена;
 - вектор-столбец размерности
- вектор-столбец размерности 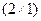 неизвестных, подлежащих оценке коэффициентов регрессии;
неизвестных, подлежащих оценке коэффициентов регрессии;
 - вектор-столбец размерности ошибок наблюдений
- вектор-столбец размерности ошибок наблюдений
 .
.
.Решение системы нормальных уравнений в матричной форме имеет вид:

Пример 1.
Бюджетное обследование семи случайно выбранных семей дало следующие результаты (в тыс. $):
Табл. 3.2..
| Наблюдение | Накопления | доход |
| Y | Х | |
| 3.5 | ||
| 1.5 | ||
| 4.5 | ||
Требуется:
1) построить однофакторную модель регрессии
2) отобразить на графике исходные данные, результаты моделирования.
Решение
1) Для вычисления параметров модели следует воспользоваться формулами (3.7) и (3.8). Промежуточные расчеты приведены в таблице 3.3.
Табл. 3.3.
| Наблюдение | Накопления - Y | Доход-X | 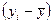
| 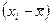
| 2
| *
| yx | X2 |
| -0.643 | -0.714 | 0.510 | 0.459 | |||||
| 2.357 | 14.286 | 204.082 | 33.673 | |||||
| 1.357 | 4.286 | 18.367 | 5.816 | |||||
| 3.5 | -0.143 | -10.714 | 114.796 | 1.531 | ||||
| 1.5 | -2.143 | -10.714 | 114.796 | 22.959 | ||||
| 4.5 | 0.857 | 9.286 | 86.224 | 7.959 | ||||
| -1.643 | -5.714 | 32.653 | 9.388 | |||||
| сумма | 25.5 | 285.00 | 0.000 | 0.000 | 571.429 | 81.786 | ||
| среднее | 3.643 | 40.714 | 1739.286 |
 ,
,

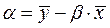 = 3.643 - 0.143125* 40.714= -2.184.
= 3.643 - 0.143125* 40.714= -2.184.
Построена модель зависимости накопления от дохода:
 , график, которой изображен на рис. 3.2.
, график, которой изображен на рис. 3.2.
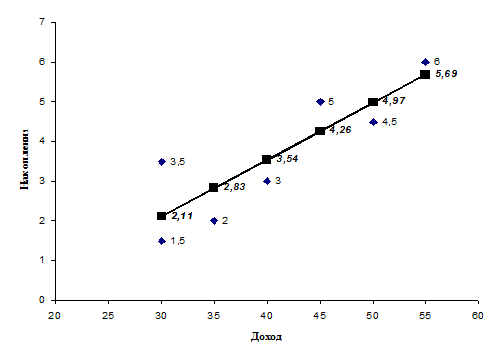
Рисунок 3.2 График модели парной регрессии.
Качество модели регрессии связывают с адекватностью модели наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным проводится на основе анализа остатков -  .
.
После построения уравнения регрессии мы можем разбить значение у, в каждом наблюдении на две составляющих -  и ;
и ;
 (3.10)
(3.10)
Остаток представляет собой отклонение фактического значения зависимой переменной от значения данной переменной, полученное расчетным путем:  (
(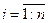 ). Если
). Если 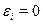 (), то для всех наблюдений фактические значения зависимой переменной совпадают с расчетными (теоретическими) значениями. Графически это означает, что теоретическая линия регрессии (линия, построенная по функции
(), то для всех наблюдений фактические значения зависимой переменной совпадают с расчетными (теоретическими) значениями. Графически это означает, что теоретическая линия регрессии (линия, построенная по функции  ) проходит через все точки корреляционного поля, что возможно только при строго функциональной связи. Следовательно, результативный признак
) проходит через все точки корреляционного поля, что возможно только при строго функциональной связи. Следовательно, результативный признак 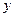 полностью обусловлен влиянием фактора
полностью обусловлен влиянием фактора  .
.
На практике, как правило, имеет место некоторое рассеивание точек корреляционного поля относительно теоретической линии регрессии, т. е. отклонения эмпирических данных от теоретических ( ). Величина этих отклонений и лежит в основе расчета показателей качества (адекватности) уравнения.
). Величина этих отклонений и лежит в основе расчета показателей качества (адекватности) уравнения.
При анализе качества модели регрессии используется основное положение дисперсионного анализа [6], согласно которому общая сумма квадратов отклонений зависимой переменной от среднего значения  может быть разложена на две составляющие — объясненную и необъясненную уравнением регрессии дисперсии:
может быть разложена на две составляющие — объясненную и необъясненную уравнением регрессии дисперсии:
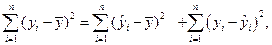 (3.11)
(3.11)
где  - значения y, вычисленные по модели .
- значения y, вычисленные по модели .
Разделив правую и левую часть (3.11) на 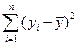
 ,
,
получим
 .
.
Коэффициент детерминации определяется следующим образом:
 (3.12.)
(3.12.)
Коэффициент детерминации показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, т. е. определяет, какая доля вариации признака Y учтена в модели и обусловлена влиянием на него факторов.
Чем ближе  к 1, тем выше качество модели.
к 1, тем выше качество модели.
Для оценки качества регрессионных моделей целесообразно также использовать коэффициент множественной корреляции (индекс корреляции) R
R = 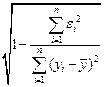 =
=  (3.13)
(3.13)
Данный коэффициент является универсальным, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных.
При построении однофакторной модели он равен коэффициенту линейной корреляции 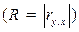 .
.
Очевидно, что чем меньше влияние неучтенных факторов, тем лучше модель соответствует фактическим данным.
Также для оценки точности регрессионных моделей целесообразно использовать среднюю относительную ошибку аппроксимации:

 (3.14)
(3.14)
Чем меньше рассеяние эмпирических точек вокруг теоретической линии регрессии, тем меньше средняя ошибка аппроксимации. Ошибка аппроксимации меньше 7 % свидетельствует о хорошем качестве модели.
После того как уравнение регрессии построено, выполняется проверка значимости построенного уравнения в целом и отдельных параметров.
Оценить значимость уравнения регрессии – это означает установить, соответствует ли математическая модель, выражающая зависимость между Y и Х, фактическим данным и достаточно ли включенных в уравнение объясняющих переменных Х для описания зависимой переменной Y
Оценка значимости уравнения регрессии производится для того, чтобы узнать, пригодно уравнение регрессии для практического использования (например, для прогноза) или нет. При этом выдвигают основную гипотезу о незначимости уравнения в целом, которая формально сводится к гипотезе о равенстве нулю параметров регрессии, или, что то же самое, о равенстве нулю коэффициента детерминации:  . Альтернативная ей гипотеза о значимости уравнения — гипотеза о неравенстве нулю параметров регрессии.
. Альтернативная ей гипотеза о значимости уравнения — гипотеза о неравенстве нулю параметров регрессии.
Для проверки значимости модели регрессии используется F-критерий Фишера, вычисляемый как отношение дисперсии исходного ряда и несмещенной дисперсии остаточной компоненты. Если расчетное значение с n1= k и n2 = (n - k - 1) степенями свободы, где k – количество факторов, включенных в модель, больше табличного при заданном уровне значимости, то модель считается значимой.
Для модели парной регрессии:
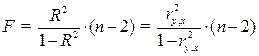 (3.15)
(3.15)
В качестве меры точности применяют несмещенную оценку дисперсии остаточной компоненты, которая представляет собой отношение суммы квадратов уровней остаточной компоненты к величине (n- k -1), где k – количество факторов, включенных в модель. Квадратный корень из этой величины ( ) называется стандартной ошибкой оценки.
) называется стандартной ошибкой оценки.
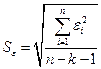 (3.16)
(3.16)
Для модели парной регрессии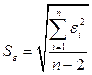
Анализ статистической значимости параметров модели парной регрессии 
Значения 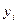 , соответствующие данным
, соответствующие данным 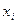 при теоретических значениях
при теоретических значениях 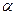 и
и  являются случайными. Случайными являются и рассчитанные по ним значения коэффициентов и .
являются случайными. Случайными являются и рассчитанные по ним значения коэффициентов и .
Надежность получаемых оценок и зависит от дисперсии случайных отклонений (ошибок). По данным выборки эти отклонения и, соответственно, их дисперсия не оцениваются – в расчетах используются отклонения зависимой переменной 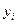 от ее расчетных значений :
от ее расчетных значений :  . Так как ошибки (остатки)
. Так как ошибки (остатки) 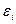 нормально распределены, то среднеквадратическое отклонение ошибок используется для измерения этой вариации. Среднеквадратические отклонения коэффициентов известны как стандартные ошибки (отклонения):
нормально распределены, то среднеквадратическое отклонение ошибок используется для измерения этой вариации. Среднеквадратические отклонения коэффициентов известны как стандартные ошибки (отклонения):

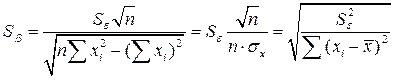 (3.17)
(3.17)
где  - среднее значение независимой переменной х;
- среднее значение независимой переменной х;
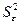 стандартная ошибка, вычисляемая по формуле (3.16);
стандартная ошибка, вычисляемая по формуле (3.16);
 .
.
Проверка значимости отдельных коэффициентов регрессии связана с определением расчетных значений t-критерия (t–статистики) для соответствующих коэффициентов регрессии:
 (3.18)
(3.18)
Затем расчетные значения  сравниваются с табличными tтабл. Табличное значение критерия определяется при (n- 2) степенях свободы (n - число наблюдений) и соответствующем уровне значимости a (0, 1; 0, 05)
сравниваются с табличными tтабл. Табличное значение критерия определяется при (n- 2) степенях свободы (n - число наблюдений) и соответствующем уровне значимости a (0, 1; 0, 05)
Если расчетное значение t-критерия с (n - 2) степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
Интервальная оценка параметров модели
Для значимого уравнения регрессии представляет интерес построение интервальных оценок для параметра  :
:
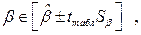 (3.19)
(3.19)
свободного члена  :
:

где t табл определяется по таблице распределения Стьюдента для уровня значимости a и числа степеней свободы k = n - 2;
 ,
,  – стандартные отклонения, соответственно, свободного члена и коэффициента модели (3.6);
– стандартные отклонения, соответственно, свободного члена и коэффициента модели (3.6);
n – число наблюдений.
Прогнозирование с применением уравнения регрессии
Регрессионные модели могут быть использованы для прогнозирования возможных ожидаемых значений зависимой переменной.
Прогнозируемое значение переменной получается при подстановке в уравнение регрессии
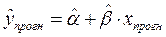 (3.20)
(3.20)
ожидаемой величины фактора . Данный прогноз называется точечным. Значение независимой переменной  не должно значительно отличаться от входящих в исследуемую выборку, по которой вычислено уравнение регрессии.
не должно значительно отличаться от входящих в исследуемую выборку, по которой вычислено уравнение регрессии.
Вероятность реализации точечного прогноза теоретически равна нулю. Поэтому рассчитывается средняя ошибка прогноза или доверительный интервал прогноза с достаточно большой надежностью.
доверительные интервалы, зависят от стандартной ошибки (3.16), удаления от своего среднего значения , количества наблюдений n и уровня значимости прогноза α. В частности, для прогноза (3.20) будущие значения  с вероятностью (1 - α) попадут в интервал
с вероятностью (1 - α) попадут в интервал
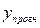

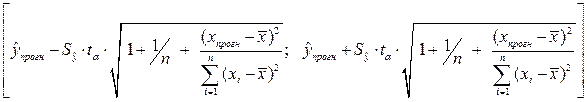 .
.
Пример 2.
Используя данные примера 3.1, оценить накопления семьи, имеющей доход 42 тыс. $ и отобразить на графике исходные данные, результаты моделирования и прогнозирования.
Решение
В примере1. была построена модель зависимости накопления от дохода:
 .
.
Для того, чтобы определить накопления семьи при доходе 42 тыс.$ необходимо подставить значение хпрогн в полученную модель.
yпрогноз = - 2.184+0.143*42= 3.827
Величину отклонения от линии регрессии вычисляют по формуле  , используя данные таблицы 3.4. Величину находят по формуле (3.16):
, используя данные таблицы 3.4. Величину находят по формуле (3.16):
 =
=  = 0.9112
= 0.9112
Табл. 3.4.
| Наблюдение | Накопления | Предсказанное Y | Остатки | e2 |
| Y | 
| e | ||
| 3.541 | -0.5406 | 0.2923 | ||
| 5.688 | 0.3125 | 0.0977 | ||
| 4.256 | 0.7438 | 0.5532 | ||
| 3.5 | 2.109 | 1.3906 | 1.9338 | |
| 1.5 | 2.109 | -0.6094 | 0.3713 | |
| 4.5 | 4.972 | -0.4719 | 0.2227 | |
| 2.825 | -0.8250 | 0.6806 | ||
| Сумма | 25.5 | 25.500 | 0.0000 | 4.1516 |
Коэффициент Стьюдента 
 для m=5 степеней свободы (m=n-2) и уровня значимости 0.1 равен 2.015. Тогда
для m=5 степеней свободы (m=n-2) и уровня значимости 0.1 равен 2.015. Тогда
U(x=42, n=7, a=0.1) =  =
=
= 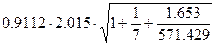 =
=  =1.965
=1.965
Таким образом, прогнозное значение  =3.827 будет находиться между верхней границей, равной 3.827+1.965=5.792 и нижней границей, равной 3.827-1.965=1.862.
=3.827 будет находиться между верхней границей, равной 3.827+1.965=5.792 и нижней границей, равной 3.827-1.965=1.862.
График исходных данных и результаты моделирования приведены на рисунке 3.5
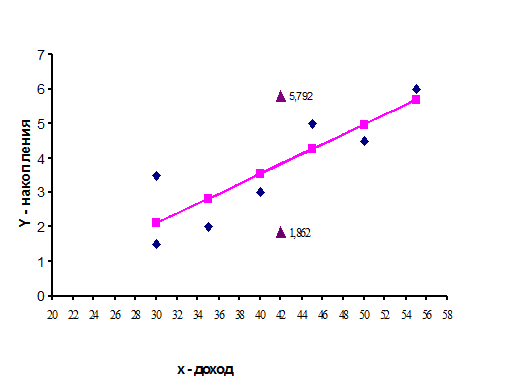
Рисунок 3.5. График модели парной регрессии зависимости накопления от дохода.