Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Основы регрессионного анализа
|
|
Тема 2. Двумерная регрессионная модель
План:
1. Основы регрессионного анализа
2. Линейная регрессия. Двумерная модель
Основы регрессионного анализа
Регрессионный анализ есть статистический метод исследования зависимости случайной величины Y от переменных 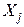 (j =1, 2,...k), рассматриваемых в регрессионном анализе как k неслучайных величин, независимо от истинного закона распределения .
(j =1, 2,...k), рассматриваемых в регрессионном анализе как k неслучайных величин, независимо от истинного закона распределения .
Обычно предполагается, что случайная величина Y имеет нормальный закон распределения с условным математическим ожиданием 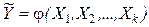 , являющимся функцией от аргументов , и постоянной, не зависящей от аргументов дисперсией
, являющимся функцией от аргументов , и постоянной, не зависящей от аргументов дисперсией 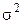 . Пусть из генеральной совокупности
. Пусть из генеральной совокупности 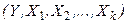 берется выборка объемом n
берется выборка объемом n 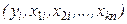
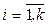 . Требуется по выборке найти оценку уравнений регрессии и исследовать его свойства.
. Требуется по выборке найти оценку уравнений регрессии и исследовать его свойства.
Переменная Y называется зависимой, а x1, x2, …, xk – объясняющими переменными. Возникают следующие вопросы:
1) зависит ли Y от x1, x2, …, xk, и, если зависит, то от каких из них,
2) какова наиболее адекватная форма зависимости,
3) можно ли, используя полученную зависимость, прогнозировать и предсказывать значения y при заданных значениях x1, x2, …, xk.
Регрессионный анализ предлагает строить искомую зависимость в форме
y = f(x1, x2, …, xk) + e, (1)
где f(x1, x2, …, xk) – некоторая заданная функция, коэффициенты которой, вообще говоря, неизвестны. Величина e включает в себя факторы, неизвестные исследователю, или случайные составляющие, которые задают погрешность приближенной формулы y» f(x1, x2, …, xk). Зависимость вида (1) называется регрессионной моделью.
Среди регрессионных моделей выделяют следующие:
А) модели, линейные по переменным и по параметрам, то есть модели вида
y = b0 + b1 x1 + b2 x2 + … + bk xk + e,
Б) модели, не линейные по переменным, но линейные по параметрам, то есть модели вида
y = b0 + b1 x1 + b2 x12 + b3 x1 x2 + b4 x22 + b5 / x2 +… + e,
В) модели, не линейные по переменным и по параметрам, то есть модели вида
y = b0 + b1 x1 + b2 x22 + b3 x1A + b4 x2C + exp(b5 x3) +sin(b6 x1 x2 )… + e.
Модель вида А) называется множественной линейной регрессией.
Модель вида Б) относится к нелинейным регрессионным моделям.
Модели вида А) и Б) в основном и применяются для решения задач эконометрики. Модель вида В) в некоторых случаях может быть сведена к А) или Б) за счет преобразования переменных. Однако в общем случае работа с моделью вида В) возможна только при использовании специальных компьютерных программ.
Все перечисленные модели содержат набор коэффициентов, которые являются параметрами моделей. Для нахождения этих параметров используется метод наименьших квадратов (МНК). Сущность этого метода состоит в следующем. Пусть вид функции f(x1, x2, …, xk) известен с точностью до входящих в нее коэффициентов b = { bk }. Запишем f = f(b, u), где u = (x1, x2, …, xk). Рассмотрим набор данных по переменным y и u:
y1, y2, …, yn; u1, u2, …, un. (2)
Составим функцию L = L(b) как сумму квадратов отклонений фактических значений yi от теоретических значений f(b, ui), то есть
L(b) = S(yi - f(b, ui))2.
Оценки коэффициентов b находятся как решение задачи на экстремум
L(b) ® min. (3)
При выполнении определенных предположений относительно величины e решение задачи (3) дает нужные нам оценки коэффициентов b*, входящих в изучаемую зависимость.
Полагаем, что случайная составляющая e удовлетворяет условиям (основные предположения МНК):
1) M e = 0, D e = s2 = const > 0,
2) пары величин ei = yi - b0 - b ui, ej = yj - b0 - b uj являются не коррелированными при всех i, j = 1, …, n, i ¹ j,
3) величин ei имеют нормальное распределение, i = 1, …, n.
Важным этапом по выбору регрессионной модели является графический анализ данных. Наиболее удобно изучать зависимости между двумя переменными, а именно y и xj. Построив на плоскости «облако точек» в форме пар (yi, xji), можно подобрать одну из формул, связывающих y и xj, либо заметить, что зависимости может и не быть.