Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Основы теории анализа и распознавания изображений
|
|
Пусть дано множество M объектов; на этом множестве существует разбиение на конечное число подмножеств (классов) Ω, i = {1, m}, M = 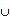 Ω i (i = 1..m). Объекты ω задаются значениями некоторых признаков xj, j= {1, N}. Описание объектаI(ω)=(x1(ω),..., xN(ω)) называют стандартным, если xj(ω) принимает значение из множества допустимых значений.
Ω i (i = 1..m). Объекты ω задаются значениями некоторых признаков xj, j= {1, N}. Описание объектаI(ω)=(x1(ω),..., xN(ω)) называют стандартным, если xj(ω) принимает значение из множества допустимых значений.
Пусть задана таблица обучения (таблица 4.1). Задача распознавания состоит в том, чтобы для заданного объекта ω и набора классов Ω 1,..., Ω m по обучающей информации в таблице обучения I0(Ω 1...Ω m) о классах и описанию I(ω) вычислить предикаты:
Pi(ω Ω i)={1(ω Ω i), 0(ω Ω i), (ω Ω i)},
Ω i)={1(ω Ω i), 0(ω Ω i), (ω Ω i)}, где i= {1, m}, Δ - неизвестно.
| Таблица 4.1. Таблица обучения | |||||
| Объект | Признаки и их значения | Класс | |||
| x1 | xj | xn | |||
| ω 1 |  11 11
| 1j
| 1n
| Ω 1 | |
| ... | |||||
| ω r1 | r11
| r1j
| r1n
| ||
| ... | |||||
| ω rk | rk1
| rkj
| rkn
| Ω m | |
| ... | |||||
| ω rm | rm1
| rmj
| rmn
|
Рассмотрим алгоритмы распознавания, основанные на вычислении оценок. В их основе лежит принцип прецедентности (в аналогичных ситуациях следует действовать аналогично).
Пусть задан полный набор признаков x1,..., xN. Выделим систему подмножеств множества признаков S1,..., Sk. Удалим произвольный набор признаков из строк ω 1, ω 2,..., ω rm и обозначим полученные строки через Sω 1, Sω 2,..., Sω rm, Sω '.
Правило близости, позволяющее оценить похожесть строк Sω ' и Sω r состоит в следующем. Пусть " усеченные" строки содержат q первых символов, то есть Sω r=(a1,..., aq) и Sω '=(b1,..., bq). Заданы пороги ε 1...ε q, 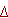 . Строки Sω r и Sω ' считаются похожими, если выполняется не менее чем неравенств вида
. Строки Sω r и Sω ' считаются похожими, если выполняется не менее чем неравенств вида
 ε j, j=1, 2,..., q.
ε j, j=1, 2,..., q. Величины ε 1...ε q, входят в качестве параметров в модель класса алгоритмов на основе оценок.
Пусть Гi(ω ') - оценка объекта ω ' по классу Ω i.
Описания объектов {ω '}, предъявленные для распознавания, переводятся в числовую матрицу оценок. Решение о том, к какому классу отнести объект, выносится на основе вычисления степени сходства распознавания объекта (строки) со строками, принадлежность которых к заданным классам известна.
Проиллюстрируем описанный алгоритм распознавания на примере.
Задано 10 классов объектов (рис. 4.2а). Требуется определить признаки таблицы обучения, пороги и построить оценки близости для классов объектов, показанных на рис. 4.2б. Предлагаются следующие признаки таблицы обучения:
x1- количество вертикальных линий минимального размера;
x2- количество горизонтальных линий;
x3- количество наклонных линий;
x4- количество горизонтальных линий снизу объекта.

Рис. 4.2. Пример задачи по распознаванию
На рис. 4.3 приведена таблица обучения и пороги
ε 1=1, ε 2=1, ε 3=1, ε 4=1, =1. Из этой таблицы видно, что неразличимость символов 6 и 9 привела к необходимости ввода еще одного признака x4.

Рис. 4.3. Таблица обучения для задачи по распознаванию
Теперь может быть построена таблица распознавания для объектов на рис. 4.2б.
| Объект | x1 | x2 | x3 | x4 | Результат распознавания |
| Объект 1 | Цифра 2 | ||||
| Объект 2 | Цифра 8 или 5 | ||||
| Объект 3 | |||||
| Объект 4 |
Читателю предлагается самостоятельно ответить на вопрос: что будет, если увеличить пороги ε 1, ε 2, ε 3, ε 4, ? Как изменится качество распознавания в данной задаче?
Заключая данный раздел лекции, отметим важную мысль, высказанную А. Шамисом в работе [55]: качество распознавания во многом зависит от того, насколько удачно создан алфавит признаков, придуманный разработчиками системы. Поэтому признаки должны быть инвариантны к ориентации, размеру и вариациям формы объектов.