Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Назначение и основы использования систем искусственного интеллекта
|
|
Искусственный интеллект — это одно из направлений информатики, целью которого является разработка аппаратно-программных средств, позволяющих пользователю-непрограммисту ставить и решать свои, традиционно считающиеся интеллектуальными задачи, общаясь с ЭВМ на ограниченном подмножестве естественного языка.
Среди множества направлений искусственного интеллекта есть несколько ведущих, которые в настоящее время вызывают наибольший интерес у исследователей и практиков. Опишем их чуть подробнее.
Представление знаний и разработка систем, основанных на знаниях (knowledge-based systems). Это основное направление в области изучения искусственного интеллекта. Оно связано с разработкой моделей представления знаний, созданием баз знаний, образующих ядро экспертных систем. В последнее время включает в себя модели и методы извлечения и структурирования знаний и сливается с инженерией знаний.
Разработка естественно-языковых интерфейсов и машинный перевод (natural language processing). Начиная с 50-х годов, одной из популярных тем исследования в области ИИ является компьютерная лингвистика, и, в частности, машинный перевод (МП). Идея машинного перевода оказалась совсем не так проста, как казалось первым исследователям и разработчикам.
Уже первая программа в области естественно-языковых (ЕЯ) интерфейсов — переводчик с английского на русский язык — продемонстрировала неэффективность первоначального подхода, основанного на пословном переводе. Однако еще долго разработчики пытались создать программы на основе морфологического анализа. Неплодотворность такого подхода связана с очевидным фактом: человек может перевести текст только на основе понимания его смысла и в контексте предшествующей информации, или контекста. В дальнейшем системы МП усложнялись, и в настоящее время используется несколько более сложных моделей:
применение так называемых «языков-посредников» или языков смысла, в результате происходит дополнительная трансляция «исходный язык оригинала — язык смысла — язык перевода»;
ассоциативный поиск аналогичных фрагментов текста и их переводов в специальных текстовых репозиториях или базах данных;
Структурный подход, включающий последовательный анализ и синтез естественно-языковых сообщений. Традиционно такой подход предполагает наличие нескольких фаз анализа:
Морфологический анализ — анализ слов в тексте.
Синтаксический анализ — разбор состава предложений и грамматических связей между словами.
Семантический анализ — анализ смысла составных частей каждого предложения на основе некоторой предметно-ориентированной базы данных.
Прагматический анализ — анализ смысла предложений в реальном контексте на основе собственной базы данных.
Синтез ЕЯ-сообщений включает аналогичные этапы, но несколько в другом порядке.
Обучение и самообучение (machine learning). Активно развивающаяся область искусственного интеллекта. Включает модели, методы и алгоритмы, ориентированные на автоматическое накопление и формирование знаний на основе анализа и обобщения данных. Включает обучение по примерам (или индуктивное), а также традиционные подходы из теории распознавания образов.
В последние годы к этому направлению тесно примыкают стремительно развивающиеся системы data mining — анализа данных и knowledge discovery — поиска закономерностей в базах данных.
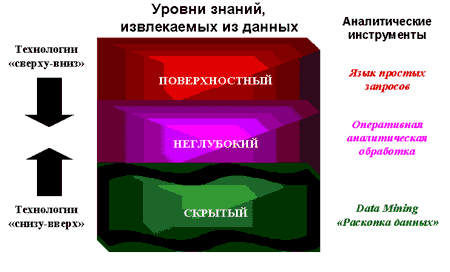
Рисунок 25 – Схема Data Mining
Data Mining - это процесс обнаружения в сырых данных ранее неизвестных нетривиальных практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности (Рисунок 25).
Распознавание образов (pattern recognition). Традиционно — одно из направлений искусственного интеллекта, берущее начало у самых его истоков, но в настоящее время практически выделившееся в самостоятельную науку. Ее основной подход — описание классов объектов через определенные значения значимых признаков. Каждому объекту ставится в соответствие матрица признаков, по которой происходит его распознавание. Процедура распознавания использует чаще всего специальные математические процедуры и функции, разделяющие объекты на классы. Это направление близко к машинному обучению и тесно связано с нейрокибернетикой.
Новые архитектуры компьютеров (new hardware platforms and architectures). Самые современные процессоры сегодня основаны на традиционной последовательной архитектуре фон Неймана, используемой еще в компьютерных первых поколений. Эта архитектура крайне неэффективна для символьной обработки. Поэтому усилия многих научных коллективов и фирм уже десятки лет нацелены на разработку аппаратных архитектур, предназначенных для обработки символьных и логических данных. Создаются Пролог- и Лисп-машины, компьютеры V и VI поколений. Последние разработки посвящены компьютерам баз данных, параллельным и векторным компьютерам.