Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Архітектура Cayman на базі AMD HD 6990
|
|
Конструкторська частина
При проектуванні Cayman(а саме таке кодове ім'я отримав новий CPU компанії) основними завданнями інженерів AMD було створення ефективної графічної та обчислювальної архітектури з новими можливостями GPGPU, значне збільшення продуктивності геометричних блоків, поліпшення в алгоритмах, що впливають на якість рендеринга(текстурна фільтрація і повноекранне згладжування), а також поліпшене керування живленням.
Судячи з усього, архітектуру Cayman (Рисунок 2.1) можна назвати проміжним рішенням між архітектурою Cypress і так і не народженою 32-нанометровой архітектурою, оскільки до складу нового GPU були включені лише деякі можливості з неї. Мета інженерів за розміром Cayman була +15% до площі Cypress, що дозволило витратити ці додаткові транзистори на деякі нові обчислювальні і графічні можливості.

Рисунок 2.1 – Архітектура графічного процесора Cayman
При погляді на схему чіпа, відразу ж звертають на себе увагу два блоки по обробці геометрії і тесселяции(graphics engine, включаючий растеризатор, тесселятор і деякі інші блоки), а також здвоєний диспетчер. Це одно з найважливіших нововведень в Cayman.
Найважливішою архітектурною зміною стала суперскалярна VLIW4 архітектура обчислювальних процесорів, на відміну від VLIW5 в попередній. З одного боку це може здатися погіршенням, адже кожен з наявних процесорів тепер може виконувати менше операцій паралельно. Але з іншої - це може збільшити ефективність використання(ККД) потокових процесорів, оскільки підібрати чотири незалежні команди явно простіше, ніж п'ять.
В цілому, новий графічний процесор включає 24 SIMD- ядра, кожне з яких складається з 16 процесорів, що уміють обчислювати до чотирьох команд одночасно. Іншими словами, всього обчислювальних блоків в Cayman стало 24× 16× 4=1536 штук, що навіть дещо менше, ніж у Cypress. Але оскільки ККД використання цих блоків явно повинен збільшитися, то і продуктивність також збыльшується.
Кожне SIMD- ядро нового графічного процесора має по чотири блоки текстурування, як і в попередніх GPU, тобто загальне число текстурних процесорів - 96 TMU. Це дещо більше, ніж у Cypress, і помітно більше, ніж має топовий чіп конкурента. Так, перевага по текстуруванню повинна залишитися за AMD. Інші чисельні характеристики мало відрізняються від тих же HD 5800 і HD 6800, чіп має чотири 64-бітові контроллери пам'яті і 256-бітову шину в цілому, а також 32 блоки ROP. Хоча вони все ж відрізняються від тих, що використовуються в попередніх GPU.
Нові потокові процесори відрізняються від попередніх тим, що уміють виконувати одночасно до чотирьох незалежних інструкцій(4 - way co - issue), і усі чотири виконавчі облаштування ALU в процесорі мають однакові можливості, на відміну від попередньої архітектури. Нагадаємо, що кожен потоковий процесор Cypress має чотири блоки ALU + блок спеціального призначення SFU(також званий " T-unit"), службовець для виконання трансцендентних функцій(синус, косинус, логарифм і т. д.), а Cayman виконує такі команди за допомогою трьох з чотирьох " звичайних" ALU(Рисунок 2.2).
Всі разом дають теоретично кращий показник ефективності використання потокових процесорів, в порівнянні з VLIW5. Хоча VLIW5 забезпечує досить високий ККД у багатьох випадках, але середнє завантаження ALU виходить явно нижче 100%, і часто лише три або чотири блоки з п'яти зайняті роботою. Зниження кількості ALU в кожному процесорі збільшує їх ефективність, і, за оцінкою компанії AMD, поліпшення співвідношення швидкості обчислень і площі чіпа складає близько 10%. Плюс до цього, додатковим бонусом йде спрощення блоків, що управляють: шеейдерои та керуванням регістрами.
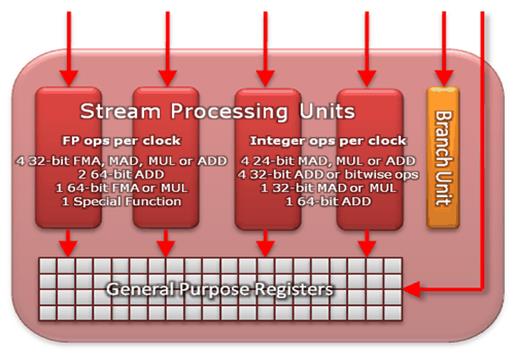
Рисунок 2.2 – Архітектура потокових процесорів
Ще однією важливою деталлю переходу від VLIW5 до VLIW4 являється те, що для асиметричної архітектури складніше оптимізувати і скомпілювати ефективний код. А для симетричного VLIW4 блоку робота компілятора спрощується. І в цьому ми бачимо поки що нерозкритий потенціал Cayman - швидше за все, компілятор доки оптимізований для нового GPU недостатньо і в майбутньому дуже вірогідні прирости у міру оптимізації компілятора для нової архітектури.
Нова архітектура VLIW4 привела до збільшення продуктивності обчислень з подвійною точністю. 64-бітові обчислення тепер виконуються вчетверо повільніше, ніж 32-бітові. А у рішень попередньої архітектури це співвідношення було нижче - 1/5. Така зміна дозволила підвищити пікову продуктивність 64-бітових обчислень нового Radeon HD 6990 до 695 GFLOPS(для порівняння - у HD 5870 цей показник дорівнює 544 GFLOPS).
Блоки ROP, зображений на рисунку 2.3 в новому чіпі компанії AMD також отримали деякі удосконалення. Cayman тепер уміє значно швидше обробляти дані в деяких форматах, серед яких 16-бітовий цілочисельний(удвічі швидше) і одно- або двокомпонентний 32-бітовий(прискорення в два-чотири рази, залежно від кількості компонентів).
Найбільше змін в Cayman сталося якраз в обчислювальних можливостей. Передусім треба відмітити асинхронну відправку команд на виконання і одночасне виконання декількох обчислювальних процесів(kernel), кожен з яких має свою чергу команд і свою область захищеної віртуальної пам'яті. По суті, в Cayman з'явилися можливості обчислень за принципом MPMD(Multiple Processor/Multiple Data) - коли декілька процесорів виконують безліч потоків даних.
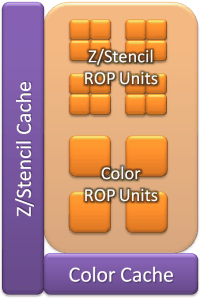
Рисунок 2.3 - Блок ROP
У попередній архітектурі компанії AMD була можливість одночасного запуску і розподілу декількох процесів(kernel), але вони мали лише один конвеєр команд, що утрудняло одночасну роботу обчислювальних і графічних застосувань. GPU нової архітектури здатний ефективно виконувати декілька потоків команд одночасно. Потоки мають свої окремі кільцеві буфери і черги, а черговість виконання команд незалежна і асинхронна, і виконуються вони залежно від пріоритету. Це дозволяє запускати обчислення і отримувати підсумкові результати першими.
Також для кожного kernel зображено на рисунку 2.4 новий чіп надає незалежну віртуальну пам'ять, і усі потоки команд тепер захищені один від одного. А на додаток до асинхронного подання команд, чіп має два двонаправлені контроллери прямого доступу до пам'яті(DMA), що допоможе збільшити пропускну спроможність в обох напрямах.
З'явилася можливість вибірки даних з пам'яті в обхід ALU безпосередньо в локальну пам'ять, а оптимізовані читання і комбінований запис даних збільшила продуктивність підсистеми введення-виведення. Також в новому GPU було поліпшено управління потоком передачі даних(flow control).
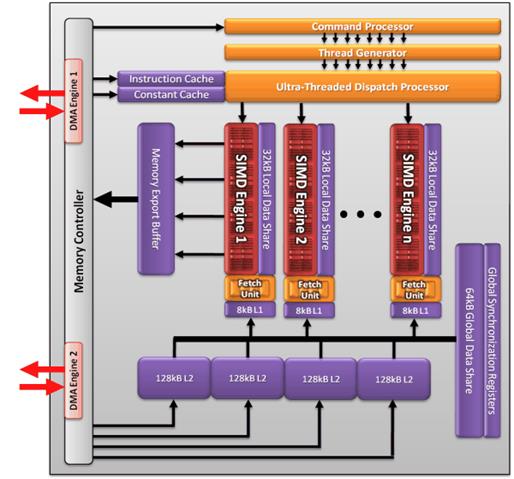
Рисунок 2.4 – Негравічні обчислення на GPU
Усі попередні покоління GPU використовують один блок для вибірки, установки та растеризації трикутників. Цей звичний вид графічного конвеєра забезпечує фіксовану продуктивність і часто може бути обмежувачем загальної продуктивності.
У цьому також винна і складність розпаралелювання обробки при відсутності відповідних змін в програмному інтерфейсі (API). І якщо раніше такий конвеєр з одним блоком растеризації працював прийнятно, при збільшенні складності та масовості геометричних розрахунків, растеризація стала головним обмежувачем на шляху збільшення складності геометрії в 3D-сценах.
Так, активне використання тесселяції повністю змінює баланс завантаження різних блоків GPU. З тесселяції щільність трикутників виростає на порядки, що сильно навантажує такі раніше послідовні ділянки графічного конвеєра, як установка трикутників (triangle setup) і растеризація. Для забезпечення високої продуктивності тесселяції необхідно було вирішити цю проблему змінами архітектури, перебалансувавши весь графічний конвеєр GPU.
Щоб домогтися високої швидкості обрахунку геометрії, компанія NVIDIA розробила масштабований блок обробки геометрії з назвою PolyMorph Engine. Кожен з 16-ти блоків PolyMorph, наявних в Radeon HD 6990, містить власний модуль за вибіркою вершин (vertex fetch unit) і тесселятор, що значно збільшує продуктивність геометричних обчислень.
Додатково до цього, в Radeon HD 6990 були включені чотири блоки растеризації Raster Engine, що працюють паралельно і дозволяють виконувати установку до чотирьох трикутників за такт. Разом ці блоки забезпечують пристойне зростання продуктивності обробки трикутників, тесселяції та растеризації.
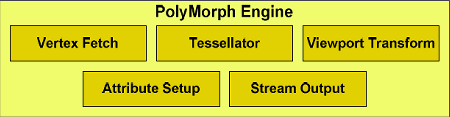
Рисунок 2.5 – Схема паралельної обробки геометрії
PolyMorph Engine містить п’ять стадій, як показано на рисунку 2.5: вибірка вершин (Vertex Fetch), тесселяція, перетворення в екранні координати (Viewport Transform), установка атрибутів (Attribute Setup) і потоковий висновок (Stream Output). Результати, обчислені в кожній стадії, передаються в мультипроцесор SM. Останній виконує шейдерну програму, повертаючи дані до наступної стадії PolyMorph Engine. Після проходження всіх стадій результати направляються в движки растеризації Raster Engine.
Перша стадія починається з вибірки вершин з глобального вершинного буфера. Вибрані вершини посилаються в мультипроцесор для вершинного затінювання (vertex shading і hull shading). У цих двох стадіях вершини перетворюються з координат об’єктного простору (object space) у світове (world space) і обчислюються параметри, необхідні для тесселяції, такі як коефіцієнт розбивки (tessellation factor). Ці параметри потім пересилаються в тесселятор.
У другій стадії модуль PolyMorph зчитує ці параметри тесселяції і розбиває патч (гладка поверхня, певна контрольними точками), виводячи результуючу сітку (mesh). Ці нові вершини посилаються в мультипроцесор, де виконується доменний і геометричний шейдери.
Доменний шейдер обчислює підсумкове становище кожної вершини на основі даних від поверхневого шейдера (Hull Shader) і тесселятора. На цій стадії зазвичай застосовується карта зміщення (displacement map), що додає патчу деталізації. Геометричний шейдер проводить додаткову обробку, додаючи або видаляючи вершини або примітиви, якщо необхідно.
В останній стадії PolyMorph Engine виробляє перетворення в екранні координати (viewport transformation) і корекцію перспективи. Далі йде встановлення атрибутів, а вершини можуть бути виведені за допомогою stream output в пам’ять для подальшої обробки.
У попередніх архітектурах подібні fixed function операції виконувалися лише одним конвеєром. Теоретично при виконанні на Radeon HD 6990 і fixed function, і програмовані операції повинні бути розпаралелені, що, у свою чергу, повинно викликати приріст продуктивності в разі обмеження продуктивності такими операціями.
Однією з основних архітектурних переваг конкуруючих рішень від NVIDIA є обробка геометрії, що розпаралелює, вживана в усіх їх сучасних рішеннях, які дуже ефективні при використанні тесселяции. геометричні примітиви в топових чіпах конкурента AMD обробляються одночасно 16-у блоками, на відміну від одного блоку у Cypress і Barts, так само як і інших попередніх чіпах.
Відповідно, AMD треба було терміново поліпшити продуктивність геометричних блоків. Частковий крок був зроблений ще в Barts, оптимізації якого привели до підвищення швидкості обробки геометрії і тесселяции в півтора рази у кращому разі. Але навіть тесселятор сьомого покоління все ще серйозно поступався тесселяторам Fermi першого ж покоління.
Блоки обробки геометрії і тесселяции в Cayman названі вже восьмим поколінням, і вони отримали установку геометричних примітивів(geometry setup) подвоєної швидкості, поліпшену буферизацію геометричних даних і подвійний блок обробки геометрії. Саме так, AMD теж довелося розпаралелювати роботу над геометричними даними, хоча і не настільки радикально, як це зроблено в GPU конкурента.
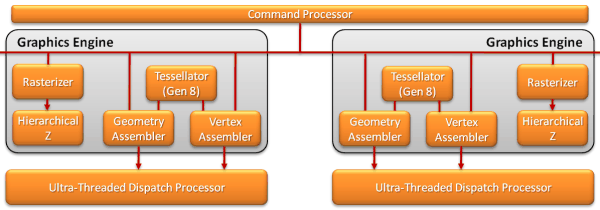
Рисунок 2.5 – Схема паралельної обробки геометрії
Подвійний блок геометрії в Cayman зображеного на рисунку 2.5 обробляє два примітиви за такт, тобто швидкість трансформації і відкидання задніх граней(backface culling) зросла удвічі, а навантаження між блоками розподіляється за допомогою розбиття на тайлы. Разом з поліпшенням буферизації, за даними AMD, це призводить до зростання продуктивності тесселяции у топового рішення Radeon HD 6990 до трьох разів, в порівнянні з HD 5870.