Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Лекция №12. Статистические методы апроксимации зависимостей
|
|
Различают четыре типа зависимостей между двумя переменными:
1) между неслучайными переменными, не требующую для своего изучения применения статистических методов,
2) между случайной переменной у от неслучайной переменной х, исследуемую методами регрессионного анализа,
3) между случайными переменными у и х, изучаемую методами корреляционного анализа,
4) между неслучайными переменными, когда они обе содержат ошибки измерения, требующую для своего изучения применения конфлюэнтного анализа. Конфлюэнтный анализ следует применять также, когда вместо результатов индивидуальных наблюдений значений у и х используются их средние значения по группам наблюдений.
В связи со сложностью разработки общей теории конфлюэнтного анализа он не получил достаточного развития. Необходимо отметить, что в ряде случаев представляется возможным решать задачу конфлюэнтного анализа методами корреляционного и регрессионного анализов [74].
Применение регрессионного анализа для обработки результатов наблюдений связано с меньшим числом ограничений, чем корреляционного анализа, и позволяет получить оценку влияния переменной (аргумента), на переменную, которая считается зависимой от первой.
В регрессионном анализе предполагается, что случайная величина у распределена нормально при каждом значении переменной х. Дисперсия у во всем интервале изменения х постоянна или пропорциональна известной функции от х. Вид функции предполагается известным:
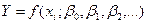 (12.1)
(12.1)
Задача заключается в нахождении оценок неизвестных параметров 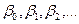 фигурирующих в уравнении. При этом относительно закона изменения величины х не делается никаких ограничений - она может изменяться либо по заданной программе, либо произвольным образом, быть непрерывной или дискретной величиной - во всех случаях регрессионный анализ осуществляется одинаково. Перед началом обработки результатов наблюдений на основе теоретических (профессиональных) соображений и рассмотрения графика положения средних
фигурирующих в уравнении. При этом относительно закона изменения величины х не делается никаких ограничений - она может изменяться либо по заданной программе, либо произвольным образом, быть непрерывной или дискретной величиной - во всех случаях регрессионный анализ осуществляется одинаково. Перед началом обработки результатов наблюдений на основе теоретических (профессиональных) соображений и рассмотрения графика положения средних 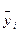 при различных - x, выдвигается гипотеза о виде функции, связывающей величины Y и х. При этом функция должна быть линейная относительно параметров
при различных - x, выдвигается гипотеза о виде функции, связывающей величины Y и х. При этом функция должна быть линейная относительно параметров
Оценку параметров в уравнении регрессии осуществляют методом наименьших квадратов, исходя из требования
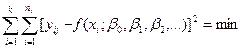 ; (12.2)
; (12.2)
где j - номер испытания при i -том значении х,
n- число испытаний при xi,
k - число различных значений х.
Получаемые оценки параметров являются несмещенными, состоятельными, подчиняются нормальному распределению со средними, равными искомым параметрам, и минимальной дисперсией.
Предполагается, что между переменными у и x существует линейная зависимость. Во многих случаях нелинейная связь может быть преобразована в линейную и к анализу результатов наблюдений могут быть применены излагаемые приемы вычислений. Кроме того, принимается, что дисперсия у постоянна во всем интервале изменения х.
12.1 Линейный регрессионный анализ когда Y является функцией одной переменной х:
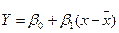 ; (12.3)
; (12.3)
В результате обработки экспериментальных данных мы должны получить оценку для теоретической линии регрессии:
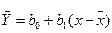 ; (12.4)
; (12.4)
Для этого минимизируем сумму квадратов отклонений наблюденных значений у от эмпирической линии регрессии:
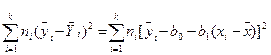 ; (12.5)
; (12.5)
Дифференцируя с этой целью правую часть выражения по b0 и b1 и приравнивая обе производные нулю, получим после преобразований два уравнения:
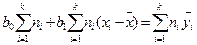 , (12.6); и
, (12.6); и 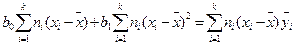 , (12.7).
, (12.7).
Так как сумма отклонений от среднего 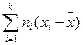 =0,
=0,
то получим: 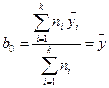 , (12.8); и
, (12.8); и 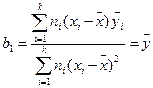 , (12.9)
, (12.9)
Дисперсия значений у, относительно эмпирической линии регрессии оценивается выражением
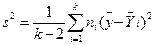 ; (12.10)
; (12.10)
Проверку гипотезы о линейности связи осуществляют, сопоставляя дисперсию средних 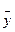 , относительно линии регрессии с дисперсией индивидуальных значений у относительно средних , которую рассматривают, как дисперсию, обусловленную ошибками эксперимента (дисперсия воспроизводимости)
, относительно линии регрессии с дисперсией индивидуальных значений у относительно средних , которую рассматривают, как дисперсию, обусловленную ошибками эксперимента (дисперсия воспроизводимости)
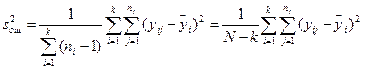 ; (12.11)
; (12.11)
Используя значения s2 и 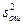 , рассматривают отношение
, рассматривают отношение
F = s2 / ; (12.12)
и, если оно меньше значения F, найденного по таблицам для данного уровня значимости а при числе степеней свободы числителя f = k - 2 и знаменателя f = N - k, то гипотеза о линейности не противоречит экспериментальным данным.
Когда F незначимо, s2 и можно объединить и получить оценку остаточной дисперсии
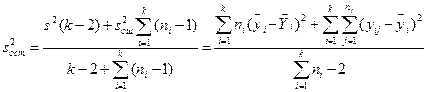 ; (12.13)
; (12.13)
Если каждому значению х соответствует одно значение у, то не представляется возможным оценить ошибку эксперимента. Проверку гипотезы о линейности связи между у и x осуществляют, сопоставляя дисперсию, обусловленную регрессией у на х, расчитываемую по формуле: 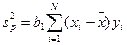 (12.14)
(12.14)
и имеющую число степеней свободы, равное числу независимых переменных (в данном случае - единице), с остаточной дисперсией опытных данных вокруг эмпирической линии регрессии:
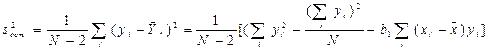 (12.15)
(12.15)
При преобразованиях учитывали, что
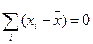 ;
; 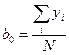 ;
; 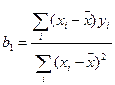 (12.16)
(12.16)
Число степеней свободы остаточной дисперсии равно f = N - 2. При этом рассчитывают отношение: F = s2p / ; (12.17)
которое в случае справедливости гипотезы о линейности функции f(х) должно быть равно или больше значения F, найденного из таблиц для данного уровня значимости а при числе степеней свободы: f1 = 1 и f2 = N-2 (12.18)
Оценка b0 распределена нормально со средним 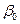 и дисперсией, оценка которой равна:
и дисперсией, оценка которой равна: 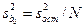 ; (12.19)
; (12.19)
Оценка b1 распределена нормально со средним 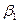 и дисперсией, оценка которой может быть рассчитана из выражения:
и дисперсией, оценка которой может быть рассчитана из выражения:
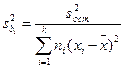 ; (12.20)
; (12.20)
Для повышения точности определения параметров линейной регрессии необходимо иметь по возможности большее число наблюдений и максимально возможную ширину варьирования независимой переменной x.
Так как оценка Y является линейной функцией b0 и b1 то она распределена нормально со средним: (12.21)
и дисперсией, оценка которой равна
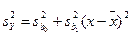 ; (12.22)
; (12.22)
Дисперсия Y минимальна при х = 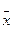 и возрастает с увеличением отклонения х от . Найденные оценки дисперсий b0, b1 и Y используются для проверки значимости параметров b0 и b1 построения доверительных границ для Y.
и возрастает с увеличением отклонения х от . Найденные оценки дисперсий b0, b1 и Y используются для проверки значимости параметров b0 и b1 построения доверительных границ для Y.
Проверяют, значимо ли отличаются от нуля свободный член b0 и коэффициент регрессии b1 . Проверку значимости осуществляют, по отношению:
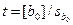 ; (12.23)
; (12.23)
которое сравнивают с табличным значением t для заданного уровня значимости a при числе степеней свободы f = N - 2.
Оценку значимости b1 производят по отношению: 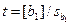 ; (12.24)
; (12.24)
сопоставляемому с табличным значением t при том же числе степеней свободы
f = N - 2.
доверительные границы для Y определяют по выражению
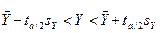 ; (12.25)
; (12.25)
где 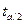 берут по таблицам для числа степеней свободы f = N - 2 и уровнем значимости, определяемого из равенства p = 1- a. Величина р есть заданная вероятность того, что теоретические значения Y лежат в найденных пределах.
берут по таблицам для числа степеней свободы f = N - 2 и уровнем значимости, определяемого из равенства p = 1- a. Величина р есть заданная вероятность того, что теоретические значения Y лежат в найденных пределах.
Часто исследователя интересуют доверительные границы для индивидуальных значений зависимой величины y. В этом случае определяют так называемые толерантные пределы представляющие собой две функции Y1(х) и Y2(х), в пространстве между которыми должна находиться величина y(х) с доверительной вероятностью p = 1- a.
p{ Y1(х) < y(x) < Y2(х)}> = p = 1- a; (12.26)
При этом вероятность получения выборок, у которых доля y(x), попадающих в эти пределы, по величине не меньше р, должна быть равна y.
Функции Y1(х) и Y2(х) представляют собой прямые, параллельные 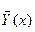 и отстоящие от нее на расстоянии Ksост. Множитель К зависит от числа наблюдений N, заданных значений доверительной вероятности р и коэффициента доверия
и отстоящие от нее на расстоянии Ksост. Множитель К зависит от числа наблюдений N, заданных значений доверительной вероятности р и коэффициента доверия 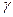 .
.
Для оценки доли общей дисперсии переменной у, обусловленной влиянием изменения аргумента х, применяют коэффициент детерминации
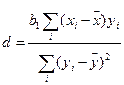 ; (12.27)
; (12.27)
Остаточное рассеивание переменной у относительно эмпирической линии регрессии можно выразить в долях от общего рассеивания этой величины
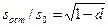 ; (12.28)
; (12.28)