Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Статистические ряды распределения. Несистематизированные данные, собранные в процессе статистического наблюдения, образуют первичный ряд данных.При достаточно большом объеме совокупности
|
|
Несистематизированные данные, собранные в процессе статистического наблюдения, образуют первичный ряд данных. При достаточно большом объеме совокупности первичный ряд данных становится трудно обозримым и непосредственное рассмотрение его не может дать представления о распределении единиц совокупности по величине признака.
Первым шагом в упорядочении первичного ряда является его ранжирование, то есть расположение всех вариант ряда (значений признака) в возрастающем или убывающем порядке.
Ранжирование данных позволяет:
1) сразу увидеть максимальное и минимальное значение признака в совокупности и оценить разницу между ними 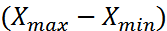 .
.
2) определить число повторений отдельных вариант ряда (частоту).
В результате первичный неупорядоченный ряд данных преобразовывается в упорядоченный ряд, в котором будет отражено число повторений каждой варианты:


Этот ряд называется статистическим рядом распределения. Он характеризует структуру изучаемого явления, позволяет судить о степени однородности изучаемой совокупности, закономерности и границах варьирования анализируемого признака.
Элементами статистического ряда распределения являются варианты — 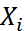 и частоты
и частоты 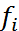 (абсолютная величина числа повторений i-й варианты).
(абсолютная величина числа повторений i-й варианты).
Для характеристики структуры совокупности используется показатель, который называется частостью и определяется по формуле
ng w: val=" EN-US" /> < /w: rPr> < m: t> f< /m: t> < /m: r> < /m: e> < m: sub> < m: r> < w: rPr> < w: rFonts w: ascii=" Cambria Math" w: h-ansi=" Cambria Math" w: cs=" Arial" /> < wx: font wx: val=" Cambria Math" /> < w: i/> < w: color w: val=" 000000" /> < w: sz w: val=" 32" /> < w: sz-cs w: val=" 32" /> < w: lang w: val=" EN-US" /> < /w: rPr> < m: t> i< /m: t> < /m: r> < /m: sub> < /m: sSub> < /m: e> < /m: nary> < /m: den> < /m: f> < /m: oMath> < /m: oMathPara> < /w: p> < w: sectPr wsp: rsidR=" 00000000" > < w: pgSz w: w=" 12240" w: h=" 15840" /> < w: pgMar w: top=" 1134" w: right=" 850" w: bottom=" 1134" w: left=" 1701" w: header=" 720" w: footer=" 720" w: gutter=" 0" /> < w: cols w: space=" 720" /> < /w: sectPr> < /w: body> < /w: wordDocument> "> 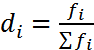 . (2.3)
. (2.3)
Из определения частоты и частости следуют равенства:
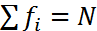 ;
;  , где N – объем совокупности.
, где N – объем совокупности.