Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Дослідженння каскадної декомпозиції даних та простору
|
|
Проілюструємо результати роботи алгоритмів на зображеннях розмірами 154× 103 пікселів (рис. 2.13, а – в). Вхідна вибірка – це координати x, y та color – середнє арифметичне кольорів пікселів. Всього дані містять 15862 3-вимірних точок. В експерименті з підгрупи (гіперкуба) прийнято вихід кластерів, рівний 10% від їх кількості у цій підгрупі.
На рис. 2.13 зображено графічні результати кластеризації зображень, а числові характеристики зведено у табл. 2.3. Представлено кінцеві кластери (позначені одним кольором) на певних рівнях ієрархічного дерева згортання при випадковому перемішуванні значень пікселів та каскадного згортання (б), при вказуванні координати х як пріоритетної та каскадного згортання (в) та відповідного ділення даних та простору (г, д). З рисунка видно, що точність перших двох алгоритмів не висока, а точність третього залежить від вектора розбиття. Зауважимо, що декомпозиційні алгоритми в представленому виді не плануються використовувати для кластеризації зображень, а для опрацювання даних іншої фізичної природи: гени, тексти, хімічні елементи тощо.
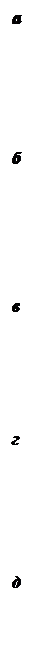

Рис. 2.13. Кластеризація експериментальних даних отриманих із зображень
а – вихідні зображення, б – без попередньої обробки каскадним згортанням,
в – сортування за пріоритетною ознакою каскадним згортанням,
г – розбиття на куби із однаковою кількістю точок за вектором розбиття (4, 4, 1),
д – розбиття на куби із однаковою кількістю точок за вектором розбиття (2, 2, 1)
З табл. 2.3 видно, що за питомими об’ємом, густиною та дисперсією найкращі результати отримано застосуванням декомпозиції гіперкубів, що підтверджують графічні результати з рис. 2.13.
Таким чином, для кластеризації даних великої розмірності найкращими алгоритмами та підходами є каскадна декомпозиція із попередньою обробкою
(2-ий алгоритм) та декомпозиція до гіперкубів (4-ий алгоритм).