Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Приклад №3 Ієрархічної кластеризації даних виконаний в пакеті прикладних програм Statsoft STATISTICA.
|
|
Розглянемо процедуру вирішення практичної задачі методом кластерного аналізу в системі STATISTICA.
Завданням кластерного аналізу є організація спостережуваних даних в наочні структури. Для вирішення даної задачі в кластерному аналізі використовуються наступний метод: Joining (tree clustering) (ієрархічні агломеративні методи або деревоподібна кластеризація).
Розберемо принцип проведення кластерного аналізу на основі даних представлених в таблиці. У ній містяться дані за показником рівня життя населення та показники-аргументи, які беруть участь у класифікації.
Розглянемо процес формування вибірок в системі STATISTICA.
1. З перемикача модулів STATISTICA відкрийте модуль Cluster Analysis (Кластерний Аналіз). Висвітиться назва модуля і далі натисніть кнопку Switch to (Переключитися в) або виберіть назву модуля Cluster Analysis.
2. На екрані з'явиться стартова панель модуля (рис.22) Clustering Method (методи кластерного аналізу): Joining (tree clustering) (ієрархічні агломеративні методи або деревоподібна кластеризація).
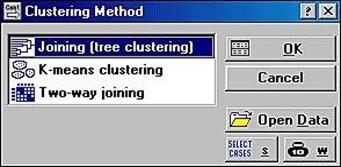
Рис.22. Стартова панель модуля Clustering Method (методи кластерного аналізу)
3. Створимо новий файл (New).Заповніть табличку згідно свого завдання. Після вибору Joining (tree clustering) і натискання на кнопку ОК з'являється вікно Cluster Analysis: Joing (Tree Clustering) (вікно введення режимів роботи для ієрархічних агломеративних методів) (рис. 23), в якому кнопка Variables дозволяє вибрати змінні беруть участь у класифікації. Натиснемо на кнопку Variables і виберемо всі змінні Select All. Далі натискаємо на кнопку OK.
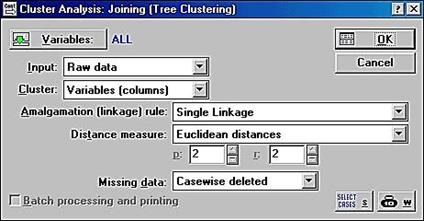
Рис.23. ClusterAnalysis: Joing (TreeClustering)
(Вікно введення режимів роботи для ієрархічних агломеративних методів)
Також можна задати Input (тип вхідної інформації) і Cluster (режим класифікації (за ознаками або об'єктам)). Можна вказати Amalgamation (linkage) rule (правило об'єднання) і Distance measure (метрика відстаней). Codes for grouping variable (коди для груп змінної) будуть вказувати кількість аналізованих груп об'єктів. Missing data (пропущені змінні) дозволяє вибрати або порядкове видалення змінних зі списку, або замінити їх на середні значення. Open Data -дозволяє відкрити файл з даними. Причому можна вказати умови вибору спостережень з бази даних-кн. Select Cases. Можна задавати ваги змінним, вибравши їх із списку – кнопкою W.
Проставте значення, як показано на рисунку 22.
4. Після задання всіх необхідних параметрів і натискання на кнопку ОК будуть зроблені обчислення, а на екрані з'явиться вікно, що містить результати кластерного аналізу " Joining Results " рис.24.

Рис.24. Вікно, що містить результати кластерного аналізу " JoiningResults"