Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Методи отримання псевдовипадкових чисел
|
|
МОДЕЛЮВАННЯ СИСТЕМ
МЕТОДИЧНІ ВКАЗІВКИ
до виконання лабораторної роботи
“Алгоритмічні методи генерації псевдовипадкових чисел за рівномірним законом розподілу”
для студентів базового напрямку " Комп’ютерні науки"
спеціальності “Інформаційні управляючі системи та технології”
Затверджено
на засіданні кафедри
автоматизовані системи управління
Протокол № 1-2013/2014
від 29.08.2013 року
Львів - 2013
МОДЕЛЮВАННЯ СИСТЕМ: Методичні вказівки до виконання лабораторної роботи “Алгоритмічні методи генерації псевдовипадкових чисел за рівномірним законом розподілу” для студентів базового напрямку “Комп'ютерні науки” спеціальності “Інформаційні управляючі системи та технології”.
Укл.: О.В. Кузьмін – Львів: Видавництво Національного університету “Львівська політехніка”, 2013 - 13 с.
Укладач: Кузьмін О.В., канд.техн.наук, доц.
Відповідальний за випуск: Шпак З.Я., канд.техн.наук, доц.
Рецензент: Різник В.В., док.техн.наук., проф.
Мета
Вивчення конгруентних методів генерації псевдовипадкових чисел за рівномірним законом розподілу на ЕОМ. Об’єм роботи: 4 години.
2. Теоретичні положення
2.1.1. Основні способи генерації псевдовипадкових чисел
Проблема моделювання випадкових величин, функцій і процесів належить до найважливіших проблем, які виникають у процесі синтезу та експлуатації імітаційних моделей складних систем. Основою для моделювання випадкових величин служить датчик псевдовипадкових чисел, рівномірно розподілених в інтервалі (0, 1), з допомогою якого шляхом деяких перетворень можна моделювати різноманітні випадкові числа, функції та процеси. Псевдовипадкові числа, рівномірно розподілені в інтервалі (0, 1), можна отримати з допомогою трьох основних способів - апаратного, табличного та алгоритмічного.
Апаратний спосіб для генерації випадкових чисел використовує електронні пристрої - генератори випадкових чисел, які служать зовнішніми пристроями ЕОМ. В основу таких генераторів покладено використання фізичного ефекту шумів в електронних і напівпровідникових приладах (так звані " генератори білого шуму") [1, c.96].
Табличний спосіб реалізується шляхом формування відповідного файлу, в якому записані конкретні значення послідовності випадкових чисел в оперативній або зовнішній пам'яті ЕОМ.
Алгоритмічний спосіб ґрунтується на формуванні випадкових величин в ЕОМ з допомогою спеціальних програм.
Переваги та недоліки зазначених способів наведені в табл.2.1.
На практиці в основному віддають перевагу алгоритмічному способу генерації псевдовипадкових чисел.
Таблиця 2.1
Переваги та недоліки основних способів
генерації псевдовипадкових чисел
| Спосіб | Переваги | Недоліки |
| Апаратний | Кількість чисел, які генеруються, необмежена. Використовується невелика кількість операцій ЕОМ. Не потребує місця в пам’яті ЕОМ | Потрібна періодична перевірка якості послідовності випадкових чисел. Повторення ідентичної послі-довності неможливе. Необхідно ви-користовувати спеціальний пристрій |
| Табличний | Перевірка якості послідовності виконується один раз - у процесі формування файлу. Можливе повторення ідентичних послідов-ностей випадкових чисел | Кількість чисел необмежена. При розміщенні в оперативній пам’яті файл займає багато місця. При розміщенні в зовнішній пам’яті зростає час звертання до файлу |
| Алгоритмічний | Перевірка якості послідовності виконується один раз - при випробуванні програми. Можливе багаторазове повторення послі-довності. Займає мало місця в пам’яті ЕОМ. Не використо-вуються зовнішні пристрої | Кількість чисел послідовності обмежена внаслідок періодичності датчика. Необхідні витрати машинного часу на отримання псевдовипадкових чисел |
2.1.2. Вимоги до генераторів псевдовипадкових чисел,
рівномірно розподілених в інтервалі (0, 1)
У процесі моделювання на ЕОМ програмна імітація випадкових дій довільної складності складається з двох основних етапів: генерації стандартного базового процесу та його подальшого функціонального перетворення. За базисний можна обрати довільний (зручний для моделювання) процес. При моделюванні на ЕОМ базовим процесом є послідовність чисел { х j} = х 0, х 1, …. xn – реалізації незалежних рівномірно розподілених в інтервалі (0, 1) випадкових величин, тобто моделюється розподіл з функцією густини
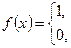
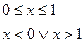
та інтервальною функцією розподілу
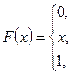
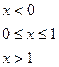
з математичним сподіванням
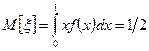
та дисперсією
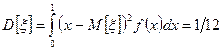
Отримати такий розподіл на цифрових ЕОМ неможливо, тому що вона оперує з п – розрядними числами з певним інтервалом дискретності. Тому на цифрових п – розрядних ЕОМ замість неперервної сукупності рівномірно розподілених в інтервалі (0, 1) випадкових чисел використовують дискретну послідовність 2 п випадкових чисел з того самого інтервалу, моделюючи, таким чином, квазірівномірний розподіл. Випадкова величина ξ, що має квазірівномірний розподіл в інтервалі (0, 1), набуває значення хі = і /(2 п – 1) з ймовірностями
Р і = (1/2) п, і = 0, 2 п – 1.
Математичне сподівання та дисперсія величин ξ
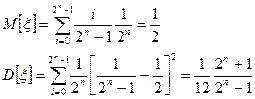
Ідеальну послідовність випадкових чисел на ЕОМ отримати неможливо внаслідок дискретності подання неперервних чисел і періодичності генерованої з допомогою алгоритмів послідовності. Тому програмні генератори генерують псевдовипадкові числа.
Ідеальний генератор псевдовипадкових чисел повинен задовольняти таким вимогам:
необхідно, щоб числа, які генеруються, були розподілені квазірівномірно;
числа послідовності мають бути статистично незалежними (тобто вони не повинні бути корельовані);
повинна існувати можливість відтворення послідовності псевдовипадкових чисел.
Доцільно, щоб генератор працював з мінімальними витратами часу та використовував мінімальний об’єм пам’яті ЕОМ.
У практиці моделювання для генерації псевдовипадкових чисел найчастіше використовуються рекурентні співвідношення першого та другого порядку:
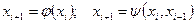
Добру послідовність псевдовипадкових чисел породжує тільки така функція φ, графік якої “достатньо повно” заповнює одиничний квадрат, наприклад функція (рис. 2.1, а) 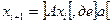 - дробова частина а при достатньо великих цілих додатних значеннях А. Водночас функція
- дробова частина а при достатньо великих цілих додатних значеннях А. Водночас функція 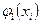 (рис. 2.1, б) не може бути використана для генерації якісної послідовності псевдовипадкових чисел (якщо побудувати точки з координатами
(рис. 2.1, б) не може бути використана для генерації якісної послідовності псевдовипадкових чисел (якщо побудувати точки з координатами 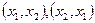 запсевдовипадковими числами з таблиці випадкових чисел, то вони будуть рівномірно розподілені в одиничному квадраті, а відповідні точки, побудовані за числами
запсевдовипадковими числами з таблиці випадкових чисел, то вони будуть рівномірно розподілені в одиничному квадраті, а відповідні точки, побудовані за числами 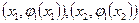 , будуть розташовані в площі, що обмежена кривою
, будуть розташовані в площі, що обмежена кривою 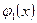 , і, крім того, з різною густиною).
, і, крім того, з різною густиною).
Розглянуті умови є лише необхідними, але недостатніми, тобто при розгляді варіантів співвідношень, які можна використати як основу для побудови генератора, є можливість відразу відкинути неперспективні за ознакою заповнення одиничного квадрату. Для тих, які залишаться, необхідно провести додаткові перевірки з використанням різноманітних статистичних тестів.
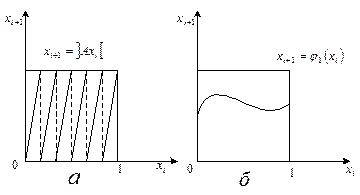
Рис.2.1. Вплив функції j на якість генерованої
послідовності псевдовипадкових чисел
Методи отримання псевдовипадкових чисел
Метод серединних квадратів - це одна з перших процедур, яку запропонували в 1946р. Фон Нейман та Метрополіс. В наш час цей метод має лише історичний інтерес, тому що його роботу важко проаналізувати, працює він порівняно повільно й не дає статистично задовільних результатів. Наведемо основні кроки алгоритму, який реалізує даний метод:
1. Взяти довільне п - значне число.
2. Піднести це число в квадрат, і, якщо потрібно, доповнити його ліворуч нулями до 2 п - значного числа.
3. Взяти n цифр з середини цього числа як наступне випадкове число.
4. Перейти до кроку 2.
Щоб отримати числа, рівномірно розподілені в інтервалі (0, 1), достатньо промасштабувати (тобто поділити на 10n) результати, знайдені за допомогою описаного вище алгоритму. Обравши за початкове число 2152, в результаті роботи алгоритму отримаємо послідовність
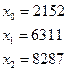
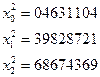
...........................................................................................................
Масштабуючи, дістанемо 0, 2152; 0, 6311; 0, 8287 і т.д.
Часто послідовність виявляється надто короткою:
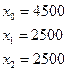
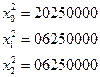
У цій послідовності випадковість взагалі відсутня, тому що починаючи з другого числа весь час буде генеруватись 2500.
Конгруентні методи будуються на основі кількох рекурентних формул з використанням поняття конгруентності - порівнянності чисел по модулю. Два числа А та В конгруентні по модулю m (m - ціле число) тоді і лише тоді, коли існує таке ціле число К, що А - В = К m, або, іншими словами, при діленні на m числа А та В мають ідентичну остачу. Так, наприклад, 5~ 7 /mod 2/, 10 ~ 14 /mod 4/. Будь-який програмний генератор, що використовує функціональне співвідношення, є періодичним, тобто починаючи з деякого числа генерована послідовність повторюється.
Мультиплікативний конгруентний метод ґрунтується на використанні формули
де а, m – невід’ємні цілі числа.
Значення а, m іпочаткове значення х 0 необхідно вибирати такими, щоб забезпечити максимальний період і мінімальну кореляцію між генерованими числами. Для двійкової машини значення модуля m= 2 b, для десяткової m= 10 d, де b, d - число відповідно двійкових (біт) та десяткових цифр у машинному слові використовуваної ЕОМ. При правильному виборі а та х 0 максимальний період для двійкових машин 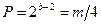 , для десяткових
, для десяткових  . Для двійкових машин значення а вибирається з співвідношення
. Для двійкових машин значення а вибирається з співвідношення 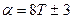 , де Т - довільне ціле додатне; х 0 - додатне непарне число. Для десяткової машини
, де Т - довільне ціле додатне; х 0 - додатне непарне число. Для десяткової машини 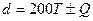 , де Q набуває одне із значень ± (3, 11, 13, 19, 21, 27, 29, 37, 53, 59, 61, 67, 77, 83, 91); х 0 - довільне непарне ціле, яке не ділиться на 5. Вибір модуля, який дорівнював би довжині машинного слова ЕОМ, приводить до прискорення роботи алгоритму, оскільки тоді обчислення остачі від ділення на m зводиться до виділення b молодших розрядів діленого, а перетворення цілого хі в раціональний дріб на інтервалі (0, 1) здійснюється підстановкою ліворуч від хі двійкової або десяткової коми. Розглянемо приклад побудови датчика для 4 - розрядної двійкової машини. Використовуючи наведені раніше рекомендації, вибираємо b =4, х 0=7 (0111), а =5 (0101):
, де Q набуває одне із значень ± (3, 11, 13, 19, 21, 27, 29, 37, 53, 59, 61, 67, 77, 83, 91); х 0 - довільне непарне ціле, яке не ділиться на 5. Вибір модуля, який дорівнював би довжині машинного слова ЕОМ, приводить до прискорення роботи алгоритму, оскільки тоді обчислення остачі від ділення на m зводиться до виділення b молодших розрядів діленого, а перетворення цілого хі в раціональний дріб на інтервалі (0, 1) здійснюється підстановкою ліворуч від хі двійкової або десяткової коми. Розглянемо приклад побудови датчика для 4 - розрядної двійкової машини. Використовуючи наведені раніше рекомендації, вибираємо b =4, х 0=7 (0111), а =5 (0101):
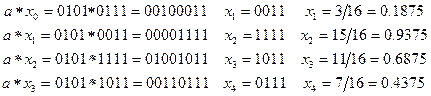
Період генератора 2 4-2= 4
Змішаний конгруентний метод, який запропонував Томсон, використовує формулу
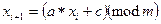
З обчислювальної точки зору змішаний метод складніший за мультиплікативний на одну операцію додавання, але можливість вибору додаткового параметра с дозволяє зменшити можливу кореляцію між генерованими числами.
Адитивний конгруентний метод працює за формулою
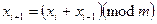
При х 0 = 0 та х 1 = 1 цей алгоритм призводить до послідовності Фібоначчі. Використання адитивного генератора, який працює за формулою
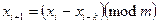
дає кращі результати, але потребує більшого обсягу пам’яті ЕОМ внаслідок необхідності збереження значень, проміжних між хі - к та хі. Якісно цей генератор працює при значенні к = 16.
Комбіновані методи генерують " ще більш випадкові" послідовності за рахунок зростання часу генерації. Так, наприклад, можна використати два генератори псевдовипадкових чисел, які генерують відповідно послідовності х 0, х 1, ... , хn та у 0, у 1,..., y n псевдовипадкових чисел, що мають значення від нуля до m- 1, незалежними способами і отримати вихідне псевдовипадкове число із співвідношення
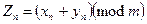
При цьому бажано, щоб довжини періодів { xn } { yn } були взаємно простими числами.
Розглянуті методи отримання псевдовипадкових чисел мають певні переваги та недоліки, що дозволяє в кожному конкретному випадку обрати найбільш доцільний метод. Крім того, генератори псевдовипадкових чисел чутливі до вибору початкових значень і констант. Найчастіше в моделюванні застосовується звичайний мультиплікативний генератор, який має високі статистичні характеристики та швидкодію.
2.1.4. Побудова гістограми
Гiстограма 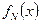 являє собою емпіричний аналог функції густини закону розподілу f (x). Побудова гістограми відбувається наступним чином:
являє собою емпіричний аналог функції густини закону розподілу f (x). Побудова гістограми відбувається наступним чином:
1. Визначаємо попередню кількість інтервалів розбиття осі абсцис К за формулою
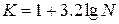
заокруглюючи отримане число до найближчого більшого цілого.
2. Визначаємо довжину інтервалів за формулою
D x = (x max - x min)/K
Для зручності обчислень значення можна дещо скоректувати.
3. Середину області зміни вибірки приймаємо як центр деякого інтервалу (x max - x min)/2, після чого знаходимо межі та остаточну кількість інтервалівтаким чином, щоб вони в сукупності перекривали цілу область від x min до x max.
4. Підраховуємо кількість спостережень Nm, які потрапляють в кожен інтервал: Nm дорівнює числу членів варіаційного ряду, для яких справедлива нерівність xm £ xi £ xm + D x, де xm, xm + D x - межі т -го інтервалу.Значення xi, які потрапляють на межу між т- м та (т- 1 ) м інтервалами, відносимо до т - го інтервалу.
5. Підраховуємо відносну кількість спостережень Nm/N, які потрапляютьв даний інтервал.
6. Будуємо гістограму, яка являє собою криву зі сходинок, значення якої на т - му інтервалі (xm, xm + D x)постійне та дорівнює Nm/N.