Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Методика выполнения работы
|
|
По территориям региона приводятся данные за 199X г. (табл. 2.1).
Таблица 2.1
Данные по регионам
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., x | Среднедневная заработная плата, руб., y |
1. Для определения степени тесноты связи обычно используют линейный коэффициент корреляции:
 , ,
| (2.12) |
где  – ковариация признаков;
– ковариация признаков;  ,
,  . Здесь
. Здесь  ,
,  – выборочные дисперсии переменных x и y.
– выборочные дисперсии переменных x и y.
Соответствующие средние значения определяются по формулам:
 , ,  , ,
| (2.13) | |
 , ,
| (2.14) | |
 , ,  . .
| (2.15) |
Дисперсию также можно рассчитать по формуле
 . .
| (2.16) |
Для расчета коэффициента корреляции (2.12) строим расчетную таблицу (рис. 2.2).
По данным таблицы находим:
 ,
,  ;
;
 ,
,  ;
;
 ,
,  ;
;
 ,
,  ;
;
 ,
,  .
.
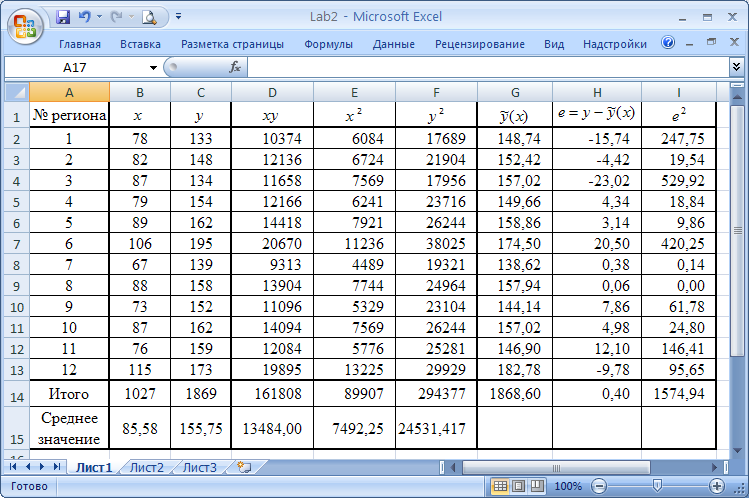
|
| Рис. 2.2. Результаты расчета текущих значений |
Последние три столбца таблицы заполняются после получения уравнения регрессии!!!
Таким образом, между заработной платой (y) и среднедушевым прожиточным минимумом (x) существует прямая достаточно сильная корреляционная зависимость.
Для оценки статистической значимости коэффициента корреляции рассчитывают двухсторонний t-критерий Стьюдента:
 , ,
| (2.17) |
который имеет распределение Стьюдента с k = n –2 и уровнем значимости a (приложение 1).
Значения Т крит можно получить в Excel с помощью функции
СТЬЮДРАСПОБР(вероятность; степени_свободы).
В нашем случае
 и
и  .
.
Поскольку Т набл > Т крит, то коэффициент корреляции существенно отличается от нуля.
Таким образом, между переменными x и y имеет существенная корреляционная зависимость. Будем считать, что эта зависимость является линейной. Модель парной линейной регрессии имеет вид
| y =b0 + b1 x + e, | (2.18) |
где y – зависимая переменная (результативный признак); x – независимая (объясняющая) переменная; e – случайные отклонения, b0 и b1 – параметры уравнение регрессии.
2. По выборке ограниченного объема можно построить эмпирическое уравнение регрессии:
 , ,
| (2.19) |
где b 0 и b 1 – эмпирические коэффициенты регрессии.
Для оценки параметров регрессии обычно используют метод наименьших квадратов (2.8).
Необходимым условием существования минимума функции двух переменных (2.8) является равенство нулю ее частных производных по неизвестным параметрам b 0 и b 1. В результате получаем систему нормальных уравнений:
 , ,
| (2.20) |
Решая систему (2.20), найдем
 , ,
| (2.21) | |
 . .
| (2.22) |
По данным таблицы находим
 ;
;
 .
.
Получено уравнение регрессии:
 . .
| (2.23) |
Величина параметра b 1 показывает среднее изменение результата с изменением фактора на одну единицу. В рассматриваемом случае, с увеличением среднедушевого минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0, 92 руб.
По исходным данным также построен точечный график зависимости y(x) с выводом линейного уравнения тренда и коэффициентом R 2 (рис. 2.3).
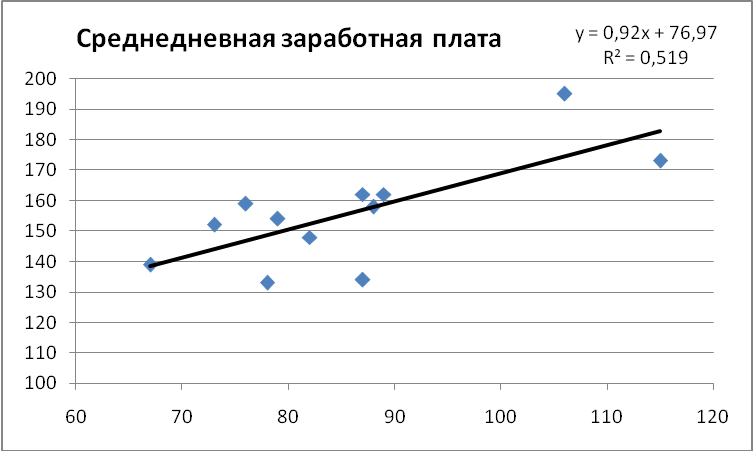
|
| Рис. 2.3. Точечная диаграмма с выводом уравнения тренда и коэффициента R 2 |
Проверка адекватности моделей, построенных на основе уравнений регрессии, начинается с проверки статистической значимости каждого коэффициента регрессии. Для этого вычислим сначала стандартную ошибку регрессии
 . .
| (2.24) |
В нашем случае

Значимость коэффициентов регрессии осуществляется с помощью
t-критерия Стьюдента:
 , ,
| (2.25) |
где  – дисперсия коэффициента регрессии.
– дисперсия коэффициента регрессии.
Для коэффициента b 1 оценку дисперсии можно получить по формуле
 . .
| (2.26) |
В нашем случае
 .
.
Следовательно,
 .
.
Отметим, что для парной линейной регрессии t -критерий для коэффициента корреляции rxy и коэффициента регрессии b 1 совпадают.
Для коэффициента b 0 оценку дисперсии можно получить по формуле:
 . .
| (2.27) |
Тогда
 и
и  .
.
Критическое значение критерия было уже найдено  .
.
Поскольку  и
и  , то коэффициенты регрессии значимы отличаются от нуля.
, то коэффициенты регрессии значимы отличаются от нуля.
Для проверки модели на адекватность также построим гистограмму распределения ее остатков. Сделаем это следующим образом. Составим диапазон изменения остатков, определим их минимальное и максимальное значения с помощью функций МАКС() и МИН(). Затем весь диапазон изменения остатков разобьем на 6-8 равных поддиапазонов и рассчитаем число попаданий ошибки (остатков) в каждый поддиапазон.
Все границы интервалов необходимо записать в отдельную строку или столбец (рис. 2.4).

|
| Рис. 2.4. Результат нахождения минимального и максимального значений ошибки и карманов |
Далее для построения гистограммы распределения остатков выбираем команду Данные ® Анализ данных (если этой опции не будет, необходимо выбрать в Другие команды… команду Надстройки... и в появившемся диалоговом окне выбрать Пакет анализа и нажать кнопку Перейти…, отметить флажком опцию Пакет анализа). В появившемся диалоговом окне Анализ данных выбираем опцию Гистограмма.
В диалоговом окне Гистограмма (рис. 2.5) в поле Входной интервал необходимо выбрать интервал, в котором находится диапазон ошибок (Н2: Н13), в поле Интервал карманов – диапазон значений отрезков поддиапазонов. Отметить флажком Вывод графика.

|
| Рис. 2.5. Построение гистограммы распределения остатков модели |
Результаты построения приведены на рис. 2.6. На автоматически построенном графике уберите Легенду и Боковые зазоры.

|
| Рис. 2.6. Гистограмма распределения остатков |
Для проверки модели на адекватность также построим график содержательного анализа остатков модели в зависимости от входной переменной Х. Для этого построим точечный график по диапазону ячеек в столбцах В2: В13 и Н2: Н13 (рис. 2.7).

|
| Рис. 2.7. График содержательного анализа остатков модели |
По полученным результатам сделайте выводы об адекватности построения модели экспериментальным данным.
Задачи регрессионного анализа можно решать с использованием ЭВМ. Например, в программе Excel достаточно ввести свои данные и использовать пакет Анализ данных. Опишем кратко последовательность действий:
а) проверьте доступ к пакету анализа. В главном меню последовательно выберите Сервис/Надстройки. Установите флажок Пакет анализа;
б) в главном меню выберите Сервис/Анализ данных/Регрессия. Щелкните по кнопке ОК;
в) заполните диалоговое окно ввода данных и параметров вывода:
- Входной интервал Y – диапазон, содержащий данные результативного признака;
- Входной интервал X – диапазон столбцов, содержащие значения факторов независимых признаков.
Результаты регрессионного анализа представлены на рисунке 2.4.
Сравните стандартную ошибку регрессии и Т -статистики коэффициентов с полученными значениями, показанными на рисунке 2.8!!!
3. Оценку качества построенной модели дает коэффициент детерминации.
Коэффициент детерминации для линейной модели равен квадрату коэффициента корреляции
 . .
|
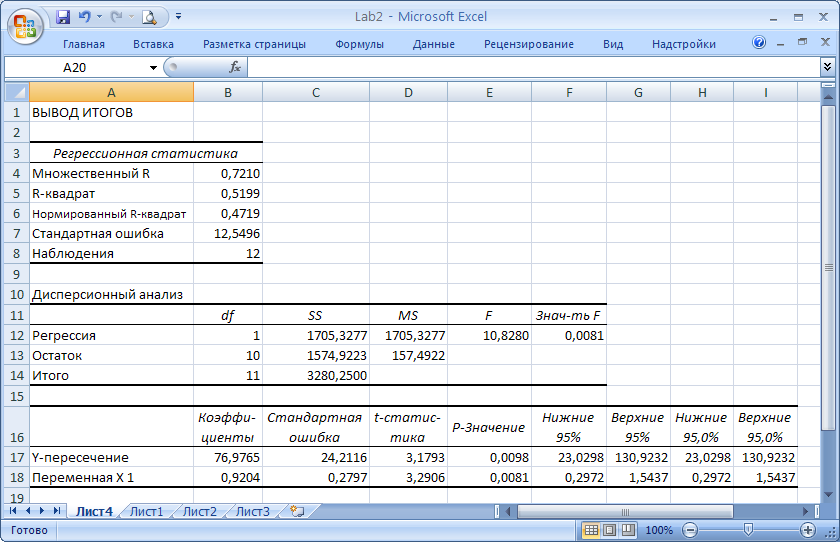
|
| Рис. 2.8. Результаты выполнения Анализа данных в Excel |
Это означает, что 52% вариация заработной платы (y) объясняется вариацией фактора x – среднедушевого прожиточного минимума.
Значимость уравнения регрессии проверяется при помощи F-критерия Фишера, для линейной парной регрессии он будет иметь вид
 , ,
| (2.28) |
где F подчиняется распределению Фишера с уровнем значимости a и степенями свободы k 1= n –2 и k 2=1 (приложение 1).
В нашем случае
 . .
|
Поскольку критическое значение критерия равно

|
и F набл > F крит, то признается статистическая значимость построенного уравнения регрессии. Отметим, что для линейной модели F - и t -критерии связаны равенством  .
.
4. Полученные оценки уравнения регрессии позволяют использовать его для прогноза.
Прогнозное значение yp определяется путем подстановки в уравнение регрессии (2.23) соответствующего (прогнозного) значения х p. В нашем случае прогнозное значение прожиточного минимума составит:  руб., тогда прогнозное значение среднедневной заработной платы составит:
руб., тогда прогнозное значение среднедневной заработной платы составит:
 руб.
руб.
Средняя стандартная ошибка прогноза вычисляется по формуле
 . .
| (2.29) |
В нашем случае
 руб. руб.
|
Предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит:
 . .
|
Доверительный интервал прогноза
 руб., руб.,
|
или
 руб. руб.
|
Выполненный прогноз среднемесячной заработной платы оказался надежным (p=0, 95), но неточным, т.к. относительная точность прогноза составила
 . .
|