Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Индекс корреляции. Подбор линеаризующего преобразования (подход Бокса-Кокса).
|
|
Любое уравнение нелинейной регрессии, как и линейной зависимости, дополняется показателем корреляции, который в данном случае называется индексом корреляции: R=√ 1-σ 2ост./σ 2y
Здесь σ 2y – общая дисперсия результативного признака y, σ 2ост. – остаточная дисперсия, определяемая по уравнению нелинейной регрессии =f(x). По-другому можно записать так:
Следует обратить внимание на то, что разности в соответствующих суммах ∑ (y –)2 и ∑ (y –)2 берутся не в преобразованных, а в исходных значениях результативного признака. Иначе говоря, при вычислении этих сумм следует использовать не преобразованные (линеаризованные) зависимости, а именно исходные нелинейные уравнения регрессии. Величина R находится в границах 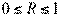 , и чем ближе она к единице, тем теснее связь рассматриваемых признаков, тем более надежно найденное уравнение регрессии.
, и чем ближе она к единице, тем теснее связь рассматриваемых признаков, тем более надежно найденное уравнение регрессии.
Если разные модели используют разные функциональные формы для зависимой переменной, то проблема выбора модели становится более сложной, так как нельзя непосредственно сравнивать коэффициенты R2 или суммы квадратов отклонений. Например, нельзя сравнивать эти статистики для линейного и логарифмического вариантов. Здесь следует использовать тест Бокса – Кокса. При сравнении моделей с использованием в качестве зависимой переменной y и lny проводится такое преобразование масштаба наблюдений y, при котором можно непосредственно сравнивать суммы квадратов отклонений в линейной и логарифмической моделях. Здесь выполняются следующие шаги. Вычисляется среднее геометрическое значений y в выборке. Оно совпадает с экспонентой среднего арифметического логарифмов y. Все значения y пересчитываются делением на среднее геометрическое, получаем значения y*. Оцениваются две регрессии: для линейной модели с использованием y* в качестве зависимой переменной и для логарифмической модели с использованием ln y* вместо ln y. Во всех других отношениях модели должны оставаться неизменными. Теперь значения СКО для двух регрессий сравнимы, и модель с меньшей остаточной СКО обеспечивает лучшее соответствие исходным данным. Для проверки, обеспечивает ли одна из моделей значимо лучшее соответствие, можно вычислить величину (n/2)lnz, где z – отношение значений остаточной СКО в перечисленных регрессиях. Эта статистика имеет распределение хи – квадрат с одной степенью свободы. Если она превышает критическое значение при выбранном уровне значимости α, то делается вывод о наличии значимой разницы в качестве оценивания.