Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Алгоритм LMS
|
|
Один из наиболее распространенных адаптивных алгоритмов основан на поиске минимума целевой функции (5.3) методом наискорейшего спуска (вариант метода градиентного спуска при выборе наилучшего шага на каждой итерации спуска). При использовании данного способа оптимизации вектор коэффициентов фильтра w(k) должен рекурсивно обновляться следующим образом:
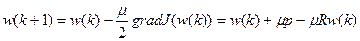 (5.7)
(5.7)
где 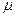 – положительный коэффициент, называемый размером шага. Подробный анализ сходимости данного процесса приведен, например, в [6]. Скорость сходимости зависит от разброса собственных чисел корреляционной матрицы R – чем меньше отношение наибольшего и наименьшего ее собственных значений, тем быстрее сходится итерационный процесс.
– положительный коэффициент, называемый размером шага. Подробный анализ сходимости данного процесса приведен, например, в [6]. Скорость сходимости зависит от разброса собственных чисел корреляционной матрицы R – чем меньше отношение наибольшего и наименьшего ее собственных значений, тем быстрее сходится итерационный процесс.
Для расчета градиента необходимо знать значения матрицы R и вектора р. Но на практике могут быть доступны лишь оценки этих значений, получаемые по входным данным. Простейшими такими оценками являются мгновенные значения корреляционной матрицы и вектора взаимных корреляций, получаемые без какого-либо усреднения:
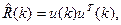
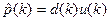
При использовании данных оценок формула (5.7) принимает следующий вид:
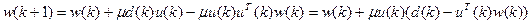 (5.8)
(5.8)
Выражение, стоящее в скобках, согласно (5.2) представляет собой разность между образцовым сигналом и выходным сигналом фильтра на к- м шаге, т.е. ошибку фильтрации e(k). С учетом этого выражение для рекурсивного обновления коэффициентов фильтра оказывается очень простым:
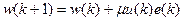 (5.9)
(5.9)
Алгоритм адаптивной фильтрации, основанный на формуле (9), получил название LMS (Least Mean Square, метод наименьших квадратов). Можно получить ту же формулу и несколько иным образом: использовав вместо градиента статистически усредненного квадрата ошибки 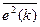 градиент его мгновенного значения
градиент его мгновенного значения 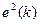 .
.
Основным достоинством алгоритма LMS является предельная вычислительная простота – для подстройки коэффициентов фильтра на каждом шаге нужно выполнить N + 1 пар операций «умножение–сложение». Платой за простоту является медленная сходимость и повышенная, по сравнению с минимально достижимым значением (6), дисперсия ошибки в установившемся режиме – коэффициенты фильтра всегда флуктуируют вокруг оптимальных значений (5), что и увеличивает уровень выходного шума.
Существует большое число модификаций алгоритма LMS, направленных на ускорение сходимости либо на уменьшение числа арифметических операций. Ускорение сходимости может быть достигнуто за счет улучшения используемой оценки градиента, а также за счет преобразования входного сигнала с целью сделать его отсчеты некоррелированными. Уменьшение вычислительной сложности может быть достигнуто, в частности, за счет использования в (5.3) не самих сигнала ошибки и содержимого линии задержки фильтра, а лишь их знаков. Это позволяет полностью избавиться от операций умножения при обновлении коэффициентов фильтра. В целом следует отметить, что требования ускорения сходимости и сокращения вычислительных затрат являются противоречивыми.