Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
ЄЮЭваЮЫмЭц ЯШвРЭЭп.
|
|
1. ПЪР ЬХвР ЯбШеЮЫцЭУТцбвШзЭЮУЮ ЬХвЮФг?
2. ЕвЮ пТЫпфвмбп ЮбЭЮТЮЯЮЫЮЦЭШЪЮЬ жмЮУЮ ЬХвЮФг?
3. Г зЮЬг ЯЮЫпУРф бгвм ЯаЮжХФгаШ?
4. ПЪц бдХаШ ТШЪЮаШбвРЭЭп жмЮУЮ ЬХвЮФг?
6. ·°БВѕБГІ°ЅЅП ј°Вµј°ВёЗЅёЕ јµВѕґ¦І Г јѕІѕ·Ѕ°ІБВІ¦
°ЪвШТЭХ ТШЪЮаШбвРЭЭп ЬРвХЬРвШзЭШе ЬХвЮФцТ г ТШТзХЭЭц ЬЮТШ ЯЮзРЫЮбп Т бХаХФШЭц XX бв. БвШЬгЫЮЬ ФЫп жмЮУЮ ЯЮбЫгЦШЫШ ЯХабЯХЪвШТШ ЬРиШЭЭЮУЮ ЯХаХЪЫРФг. Г ЯаЮжХбц ЮСаЮСЪШ вХЪбвцТ ФЫп че гТХФХЭЭп Т ЬРиШЭг СгЫЮ ЮФХаЦРЭЮ ацЧЭЮЬРЭцвЭц ЪцЫмЪцбЭц ЮжцЭЪШ ЮЪаХЬШе дРЪвцТ ЬЮТШ, пЪц ЧУЮФЮЬ ТШпТШЫШбп ЪЮаШбЭШЬШ ЭХ вцЫмЪШ ФЫп бвТЮаХЭЭп ЬРвХЬРвШзЭШе ЬЮФХЫХЩ ЬЮТШ, Р Щ ФЫп ЫцЭУТцбвШзЭЮч вХЮацч. ѕбЪцЫмЪШ ЬЮТР — жХ цЬЮТцаЭцбЭР, Р ЭХ ЦЮабвЪЮ ФХвХаЬцЭЮТРЭР бШбвХЬР, вЮ ФЫп чч ЯцЧЭРЭЭп ЪТРЭвШвРвШТЭц ЬХвЮФШ, ЯЮТ'пЧРЭц Ч ФЮбЫцФЦХЭЭпЬ зРбвЮвЭШе, ЩЬЮТцаЭцбЭШе, УаРФгРЫмЭШе вР цЭиШе ЭХЫЮУцзЭШе еРаРЪвХаШбвШЪ, ЭХ вцЫмЪШ СРЦРЭц, РЫХ Щ ЭХЮСецФЭц.
АЮЧацЧЭповм ЪцЫмЪцбЭц Щ бвРвШбвШзЭц ЬХвЮФШ. єцЫмЪцбЭц ЬХвЮФШ ЧТЮФпвмбп ФЮ ЯаЮбвЮУЮ ЯцФаРегЭЪг зРбвЮвШ ТЦШТРЭЭп ЬЮТЭШе ЮФШЭШжм. БвРвШбвШзЭц ЬХвЮФШ ЯХаХФСРзРовм ТШЪЮаШбвРЭЭп ацЧЭШе дЮаЬгЫ ФЫп ТШпТЫХЭЭп ЯаРТШЫ аЮЧЯЮФцЫг ЬЮТЭШе ЮФШЭШжм г ЬЮТЫХЭЭц, ФЫп ТШЬцаг ЧТ'пЧЪцТ ЬцЦ ЬЮТЭШЬШ ХЫХЬХЭвРЬШ, ФЫп ТбвРЭЮТЫХЭЭп вХЭФХЭжцЩ г аЮЧТШвЪг вР дгЭЪжцЮЭгТРЭЭц ЬЮТШ вР ФЫп ТбвРЭЮТЫХЭЭп ЧРЫХЦЭЮбвц ЬцЦ пЪцбЭШЬШ Щ ЪцЫмЪцбЭШЬШ еРаРЪвХаШбвШЪРЬШ ЬЮТШ.
јРвХЬРвШзЭц ЬХвЮФШ ЬРовм бРЬЮбвцЩЭг жцЭЭцбвм г ФЮбЫцФЦХЭЭц ЬЮТШ ц, ЪацЬ вЮУЮ, ЬЮЦгвм ТеЮФШвШ пЪ бЪЫРФЮТР зРбвШЭР Т цЭиц ЬХвЮФШ. ѕбвРЭЭцЬ зРбЮЬ ТШЪЮаШбвРЭЭп жШе ЬХвЮФцТ ФЮ ТШТзХЭЭп ЬЮТЭЮУЮ ЬРвХацРЫг ЧЭРзЭЮ ЧаЮбЫЮ, ц ЬЮЦЭР УЮТЮаШвШ, йЮ Т ЬРвХЬРвШзЭцЩ ЫцЭУТцбвШжц ТШЮЪаХЬШЫШЫШбп ФТР аЮЧФцЫШ, РСЮ ЭРЯапЬШ — ЫцЭУТЮбвРвШбвШЪР ц бвШЫЮбвРвШбвШЪР.
ѕбЭЮТЭР гТРУР ЫцЭУТЮбвРвШбвШЪШ ЧТХаЭХЭР ЭР ФЮбЫцФЦХЭЭп вЮУЮ, йЮ Т ЬЮТц ТШЧЭРзРфвмбп ЯаРТЮЬ ТШСЮаг ЬЮТжп, Р йЮ ЧгЬЮТЫХЭЮ чч цЬРЭХЭвЭЮо бвагЪвгаЮо ц пЪ жц ФТР ЯРаРЬХваШ ЪцЫмЪцбЭЮ бЯцТТцФЭЮбпвмбп ЬцЦ бЮСЮо. ІШпТЫпфвмбп, йЮ ЮФШЭШжц СгФм-пЪЮУЮ ЬЮТЭЮУЮ ацТЭп ЬРовм бвРЫц ФЫп ЯХТЭЮУЮ ЯХацЮФг ЪцЫмЪцбЭц ЯЮЪРЧЭШЪШ че ТШЪЮаШбвРЭЭп. їЮФцСЭцбвм ЬцЦ зЫХЭРЬШ ЮФЭЮУЮ ЬЮТЭЮУЮ ЪЮЫХЪвШТг ЯЮЫпУРф ЭХ вцЫмЪШ Т вЮЬг, пЪц ЬЮТЭц ЮФШЭШжц (дЮЭХЬШ, ЫХЪбХЬШ, УаРЬРвШзЭц дЮаЬШ ц бШЭвРЪбШзЭц ЪЮЭбвагЪжцч) ТЮЭШ ТШЪЮаШбвЮТговм, Р Щ г вЮЬг, пЪ зРбвЮ ТЮЭШ че гЦШТРовм.
ѕвЦХ, бвРф ЧаЮЧгЬцЫЮ, зЮЬг ЭШЭц вРЪЮУЮ ТХЫШЪЮУЮ ЯЮиШаХЭЭп ЭРСгЫШ вРЪ ЧТРЭц зРбвЮвЭц бЫЮТЭШЪШ, г пЪШе бЫЮТР аЮЧвРиЮТРЭц ЭХ ЧР РЫдРТцвЮЬ, Р ЧР бЯРФЮЬ зРбвЮв, вЮСвЮ ЯХаиШЬ цФХ ЭРЩСцЫми зРбвЮвЭХ бЫЮТЮ, ЧР ЭШЬ бЫЮТЮ ЭШЦзХ аРЭУЮЬ ЧР зРбвЮвЮо ТцФ ЯХаиЮУЮ ц в.Ф. ІцФЮЬц вРЪц зРбвЮвЭц бЫЮТЭШЪШ: Yosselson H. The Russian Word Count and Frequency Analysis of Grammatical Categories of Standard Literary Russian. — Detroit, 1953; ИвХЩЭдХЫмФв 9.°. ЗРбвЮвЭлЩ бЫЮТРам бЮТаХЬХЭЭЮУЮ агббЪЮУЮ ЫШвХаРвгаЭЮУЮ пЧлЪР. — ВРЫЫШЭЭ, 1963 (ЯХаХТШФРТРТбп Т јЮбЪТц Т 1969 ц 1973 аЮЪРе); ЗРбвЮвЭШЩ бЫЮТРам агббЪЮУЮ пЧлЪР / їЮФ аХФ.».Ѕ.·РбЮаШЭЮЩ. — ј., 1977. І ГЪаРчЭц Т 1981 а. ТШЩиЮТ ФТЮвЮЬЭШЩ " ЗРбвЮвЭШЩ бЫЮТЭШЪ бгзРбЭЮч гЪаРчЭбмЪЮч егФЮЦЭмЮч ЯаЮЧШ". ЗРбвЮвЭц бЫЮТЭШЪШ ЬРовм ТХЫШЪХ ЯаРЪвШзЭХ ЧЭРзХЭЭп. ЅР че ЮбЭЮТц бвТЮаоовм ЯцФагзЭШЪШ цЭЮЧХЬЭШе ЬЮТ, вХЪбвШ пЪШе СгФговмбп ЭР ЭРЩСцЫми гЦШТРЭцЩ ЫХЪбШжц, ц бЫЮТЭШЪШ-ЬцЭцЬгЬШ. ПЪйЮ ЧТРЦШвШ ЭР вХ, йЮ 1100 (ЧР цЭиШЬШ ФРЭШЬШ — 1000) ЭРЩСцЫми зРбвЮвЭШе бЫцТ ЯЮЪаШТРф 80% вХЪбвг, вЮ ЧЭРзХЭЭп зРбвЮвЭШе бЫЮТЭШЪцТ ФЫп ЫцЭУТЮФШФРЪвШЪШ ЭХЮжцЭХЭЭХ: ТРавЮ ЧЭРвШ 1100 бЫцТ ц ЬЮЦЭР аЮЧЬЮТЫпвШ цЭЮЧХЬЭЮо ЬЮТЮо, зШвРвШ Щ аЮЧгЬцвШ вХЪбвШ (ЧЭРзХЭЭп 20% ЭХТцФЮЬШе бЫцТ ЬЮЦЭР пЪЮобм ЬцаЮо ТШЧЭРзШвШ ЧР ЪЮЭвХЪбвЮЬ).
БвРвШбвШзЭц ЧРЪЮЭЮЬцаЭЮбвц ЫХЦРвм Т ЮбЭЮТц ЮаУРЭцЧРжцч бЫЮТЭШЪР ц вХЪбвг СгФм-пЪЮч ЬЮТШ. °ЬХаШЪРЭбмЪШЩ ФЮбЫцФЭШЪ ґЦ. ЖШЯд ФцЩиЮТ ТШбЭЮТЪг, йЮ цбЭгф ЧРЫХЦЭцбвм ЬцЦ зШбЫЮЬ ацЧЭШе ЧЭРзХЭм ЮФЭЮУЮ бЫЮТР ц ЩЮУЮ ТцФЭЮбЭЮо зРбвЮвЮо ТЦШТРЭЭп.
БвШЫЮбвРвШбвШЪР — жХ ТШЧЭРзХЭЭп ц еРаРЪвХаШбвШЪР бвШЫцбвШзЭШе ЮбЮСЫШТЮбвХЩ ЮЪаХЬШе вТЮацТ РСЮ РТвЮацТ зХаХЧ ЪцЫмЪцбЭц ТцФЭЮиХЭЭп ТШЪЮаШбвРЭШе ЬЮТЭШе ХЫХЬХЭвцТ. І ЮбЭЮТц бвРвШбвШзЭЮУЮ ЯцФеЮФг ФЮ ФЮбЫцФЦХЭЭп бвШЫцбвШзЭШе пТШй ЫХЦШвм аЮЧгЬцЭЭп ЫцвХаРвгаЭЮУЮ бвШЫо пЪ цЭФШТцФгРЫмЭЮУЮ бЯЮбЮСг ТЮЫЮФцЭЭп ЧРбЮСРЬШ ЬЮТШ. їаШ жмЮЬг ФЮбЫцФЭШЪ РСбваРУгфвмбп ТцФ ЯШвРЭЭп ЯаЮ пЪцбЭг ЧЭРзХЭЭХТцбвм ЮСзШбЫоТРЭШе ЬЮТЭШе ХЫХЬХЭвцТ, ЧЮбХаХФЦгозШ бТЮо гТРУг вцЫмЪШ ЭР ЪцЫмЪцбЭЮЬг РбЯХЪвц.
ЅРЩЯаЮбвциШЬ ацЧЭЮТШФЮЬ бвРвШбвШзЭЮУЮ ЯцФеЮФг ФЮ ТШТзХЭЭп ЬЮТШ ЯШбмЬХЭЭШЪцТ РСЮ ЮЪаХЬШе вТЮацТ ф ЯцФаРегЭЮЪ гЦШТРЭЮбвц бЫцТ, ЮбЪцЫмЪШ СРУРвбвТЮ бЫЮТЭШЪР ЯХТЭШЬ зШЭЮЬ еРаРЪвХаШЧгф че ЬЮТг. ґЮбШвм ЯЮацТЭпвШ вРЪц дРЪвШ: бЫЮТЭШЪЮТШЩ ЧРЯРб ЯХаХбцзЭЮч ЫоФШЭШ бвРЭЮТШвм 7— 10 вШбпз бЫцТ, г вТЮаРе ѕ. їгиЪцЭР ТЦШвЮ 21280 бЫцТ, Р Т аЮбцЩбмЪЮЬЮТЭШе вТЮаРе В. ИХТзХЭЪР — 21548 бЫцТ.
ґЫп ЪЮЦЭЮУЮ ЯШбмЬХЭЭШЪР, пЪ ц СгФм-пЪЮУЮ ЬЮТжп, еРаРЪвХаЭР бТЮп бЯХжШдцзЭР зРбвЮвЭцбвм ЬЮТЭШе ХЫХЬХЭвцТ, цЭиШЬШ бЫЮТРЬШ, ЪЮЦЭЮЬг РТвЮаЮТц ЯаШвРЬРЭЭц бТЮч гЫоСЫХЭц, Р вЮЬг Щ зРбвЮвЭц бЫЮТР, бЫЮТЮбЯЮЫгзХЭЭп, даРЧШ, бШЭвРЪбШзЭц ЪЮЭбвагЪжцч вЮйЮ. ВРЪ, бЪРЦцЬЮ, 56 ЭРЩзРбвЮвЭциШе бЫцТ г вТЮаРе ѕ. їгиЪцЭР ЯЮЪаШТРовм 40 ТцФбЮвЪцТ вХЪбвг, 1000 бЫцТ — 70 ТцФбЮвЪцТ, 8000 — 95 ТцФбЮвЪцТ, цЭиц 13280 бЫцТ — гбмЮУЮ ЫШиХ 5 ТцФбЮвЪцТ вХЪбвг. БРЬХ вЮЬг ТцФЭЮбЭР зРбвЮвЭцбвм ТШЪЮаШбвЮТгфвмбп вРЪЮЦ ФЫп ТбвРЭЮТЫХЭЭп бЯаРТЦЭмЮУЮ РТвЮабвТР ТШпТЫХЭШе СХЧ ЧРЧЭРзХЭЭп РТвЮаР вТЮацТ, Р вРЪЮЦ ФЫп ФРвгТРЭЭп ЮЪаХЬШе вТЮацТ вЮУЮ бРЬЮУЮ РТвЮаР ЭР ЮбЭЮТц ЯЮЯХаХФЭмЮ ЯаЮТХФХЭЮУЮ ЯцФаРегЭЪг ТцФЭЮбЭЮч зРбвЮвШ ТЦШТРЭЭп ЭШЬ бЫцТ г ацЧЭц ЯХацЮФШ ЩЮУЮ вТЮазЮбвц. БЯХжШдцзЭШЬШ ФЫп ЪЮЦЭЮУЮ РТвЮаР ф Щ ацФЪЮ ТЦШТРЭц бЫЮТР.
їаШ ТШТзХЭЭц ЬЮТЭШе дгЭЪжцЮЭРЫмЭШе бвШЫцТ ЧРбвЮбЮТговм ФТР ацЧЭЮТШФШ бвРвШбвШЪШ: ЩЬЮТцаЭцбЭШЩ ц бШЬЯвЮЬРвШзЭШЩ. №ЬЮТцаЭцбЭР бвРвШбвШЪР ФЮЯЮЬРУРф ТбвРЭЮТШвШ бвгЯцЭм ФЮбвЮТцаЭЮбвц ЮФХаЦРЭШе аХЧгЫмвРвцТ, ТХЫШзШЭг Щ ЪцЫмЪцбвм ТШСцаЮЪ ФЫп РЭРЫцЧг цЧ ЧРФРЭЮо вЮзЭцбво, ТШСаРвШ ЮС'фЪвШТЭц ЪаШвХацч ФЫп ФШдХаХЭжцРжцч ацЧЭШе бвШЫцТ, ТШЧЭРзШвШ ТцФбвРЭм ЬцЦ бвШЫпЬШ. БШЬЯвЮЬРвШзЭг бвРвШбвШЪг ЧРбвЮбЮТговм ЯаШ бвРвШбвШзЭЮЬг ЮЯШбц дгЭЪжцЮЭРЫмЭШе бвШЫцТ, ЮбЪцЫмЪШ ЧР чч ФЮЯЮЬЮУЮо ЬЮЦЭР ТШпТШвШ ЯаЮжХЭвЭХ бЯцТТцФЭЮиХЭЭп ЬцЦ ацЧЭШЬШ вШЯРЬШ ЬЮТЭШе пТШй.
єацЬ бвРвШбвШзЭШе ЬХвЮФцТ, г ЬЮТЮЧЭРТбвТц ЧРбвЮбЮТговм ЬХвЮФШ вХЮацч цЭдЮаЬРжцч, ЬРвХЬРвШзЭЮч ЫЮУцЪШ, вХЮацч ЩЬЮТцаЭЮбвц Щ вХЮацч ЬЭЮЦШЭ.
ґРЭц вХЮацч цЭдЮаЬРжцч ТШЪЮаШбвЮТговмбп ФЫп ЭРЩ ХЪЮЭЮЬЭциЮч ЯХаХФРзц цЭдЮаЬРжцч ЧРбЮСРЬШ ЬЮТШ. єЮЦЭР ЬЮТР ЬРф ЧЭРзЭг ЪцЫмЪцбвм ЭРФЫШиЪЮТЮч цЭдЮаЬРжцч. ЙЮС ЯХаХЪЮЭРвШбп Т вЮЬг, ТРавЮ ЧТХаЭгвШбп ФЮ дХЭЮЬХЭг вХЫХУаРЬШ: ЭХЧТРЦРозШ ЭР бЪЮаЮзХЭЭп бЫцТ ц гбгЭХЭЭп ФХпЪШе бЫгЦСЮТШе бЫцТ, чч ЧЬцбв ЧРЫШиРфвмбп ЧаЮЧгЬцЫШЬ. Г ЬЮТЫХЭЭц, ЧЮЪаХЬР, ЯЮТвЮаофвмбп (цЭЪЮЫШ ЯЮ Я'пвм ц СцЫмиХ аРЧцТ) ТЪРЧцТЪР ЭР ацФ, зШбЫЮ, ТцФЬцЭЮЪ, ТЦШТРовмбп ЯцФапФ бШЭЮЭцЬШ, вР бРЬР ФгЬЪР зРбвЮ ФгСЫофвмбп (гвЮзЭХЭЭп, йЮ ЯЮзШЭРовмбп бЫЮТРЬШ вЮСвЮ, цЭРЪиХ, цЭиШЬШ бЫЮТРЬШ вЮйЮ) вР цЭ. ІбвРЭЮТЫХЭЮ, йЮ, ЭРЯаШЪЫРФ, аЮбцЩбмЪР ЬЮТР ЬРф 39, 8 % ЭРФЫШиЪЮТЮч цЭдЮаЬРжцч, РЭУЫцЩбмЪР — 30, 7 %. АцЧЭШЬ бвгЯХЭХЬ ЭРФЫШиЪЮТЮХвц еРаРЪвХаШЧговмбп бвШЫц вцфч бРЬЮч ЬЮТШ. ЅРЩСцЫмиР ЭРФЫШиЪЮТцбвм ЯаШвРЬРЭЭР ФцЫЮТЮЬг бвШЫо, ЬХЭиР — ЯгСЫцжШбвШзЭЮЬг ц егФЮЦЭмЮ-СХЫХваШбвШзЭЮЬг ц ЭРЩЬХЭиР — ЭХЯцФУЮвЮТЫХЭЮЬг гбЭЮЬг ЬЮТЫХЭЭо. ЅРФЫШиЪЮТцбвм цЭдЮаЬРжцч Т ЬЮТц ЭХ ЬЮЦЭР аЮЧжцЭоТРвШ пЪ ЭХФЮЫцЪ. ЗРбвЮ ЭРФЫШиЪЮТцбвм ЯаШ ЯХаХиЪЮФРе ЭР ЪРЭРЫц ЧТ'пЧЪг ф ФЮЯЮЬцЦЭШЬ ЧРбЮСЮЬ бЯаШЩЭпввп ЯЮТЭЮч цЭдЮаЬРжцч.
· ЬРвХЬРвШзЭЮч ЫЮУцЪШ ЬЮТЮЧЭРТбвТЮ ЧРЯЮЧШзШЫЮ бШЬТЮЫцзЭг ЬЮТг. ВРЪ, ЧЮЪаХЬР, ЧЭРЪ 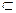 ЮЧЭРзРф ТеЮФЦХЭЭп,
ЮЧЭРзРф ТеЮФЦХЭЭп, 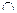 — ЯХаХвШЭ,
— ЯХаХвШЭ,  — ЯЮфФЭРЭЭп,
— ЯЮфФЭРЭЭп,  — ц, v — РСЮ, + — дгЭЪжцо, Р, Т, б — ЧЬцЭЭц, > — СцЫмиХ, < — ЬХЭиХ, ~ — ЯЮФцСЭЮ. ІШЪЮаШбвРЭЭп ХЫХЬХЭвцТ ЬРвХЬРвШзЭЮч ЫЮУцЪШ ТЯЫШЭгЫЮ ЭР ЧСРУРзХЭЭп ЯаШЩЮЬцТ ФЮбЫцФЦХЭЭп ЬЮТШ — РЫУЮаШвЬцЧРжцо, УаРдцзЭц ЮСзШбЫХЭЭп, ЬРваШзЭХ ТШЧЭРзХЭЭп цбвШЭЭЮбвц дгЭЪжцЩ бЪЫРФЭШе ТШбЫЮТЫоТРЭм вЮйЮ. ·РбвЮбгТРЭЭп ЫЮУцЪЮ-ЬРвХЬРвШзЭШе ЬХвЮФШЪ ц ЯаШЩЮЬцТ ЬЮФХЫоТРЭЭп ЧгЬЮТШЫЮ ЯЮпТг ацЧЭШе ТШФцТ ЫЮУцЪЮ-ЬРвХЬРвШзЭЮУЮ ЬЮФХЫоТРЭЭп ЬЮТШ, ЬШбЫХЭЮУЮ ХЪбЯХаШЬХЭвг ц УцЯЮвХвШЪЮ-ФХФгЪвШТЭЮУЮ бЯЮбЮСг ФЮбЫцФЦХЭЭп.
— ц, v — РСЮ, + — дгЭЪжцо, Р, Т, б — ЧЬцЭЭц, > — СцЫмиХ, < — ЬХЭиХ, ~ — ЯЮФцСЭЮ. ІШЪЮаШбвРЭЭп ХЫХЬХЭвцТ ЬРвХЬРвШзЭЮч ЫЮУцЪШ ТЯЫШЭгЫЮ ЭР ЧСРУРзХЭЭп ЯаШЩЮЬцТ ФЮбЫцФЦХЭЭп ЬЮТШ — РЫУЮаШвЬцЧРжцо, УаРдцзЭц ЮСзШбЫХЭЭп, ЬРваШзЭХ ТШЧЭРзХЭЭп цбвШЭЭЮбвц дгЭЪжцЩ бЪЫРФЭШе ТШбЫЮТЫоТРЭм вЮйЮ. ·РбвЮбгТРЭЭп ЫЮУцЪЮ-ЬРвХЬРвШзЭШе ЬХвЮФШЪ ц ЯаШЩЮЬцТ ЬЮФХЫоТРЭЭп ЧгЬЮТШЫЮ ЯЮпТг ацЧЭШе ТШФцТ ЫЮУцЪЮ-ЬРвХЬРвШзЭЮУЮ ЬЮФХЫоТРЭЭп ЬЮТШ, ЬШбЫХЭЮУЮ ХЪбЯХаШЬХЭвг ц УцЯЮвХвШЪЮ-ФХФгЪвШТЭЮУЮ бЯЮбЮСг ФЮбЫцФЦХЭЭп.
ГбХ Т ЬЮТц ЯцФЯЮапФЪЮТгфвмбп ЭХ ЦЮабвЪШЬ, Р ЩЬЮТцаЭцбЭШЬ ЧРЪЮЭЮЬцаЭЮбвпЬ. ВЮЬг жцЫЪЮЬ ЯаШаЮФЭЮ, йЮ Т ФЮбЫцФЦХЭЭц ЬЮТЭШе ЮФШЭШжм ТШЪЮаШбвЮТговм вХЮацо ЩЬЮТцаЭЮбвц. їцФ ЩЬЮТцаЭцбво аЮЧгЬцовм ТцФЭЮиХЭЭп бХаХФЭмЮУЮ бЯЮбвХаХЦгТРЭЮУЮ зШбЫР ТФРЫШе аХЧгЫмвРвцТ ФЮ ЧРУРЫмЭЮУЮ зШбЫР ХЪбЯХаШЬХЭвцТ (ЯЮФцЩ). ЅРЩЯаЮбвциХ ЯШвРЭЭп, пЪХ ФЮЯЮЬРУРф Ч'пбгТРвШ вХЮацп ЩЬЮТцаЭЮбвц, — зРбвЮвЭцбвм ЧТгЪцТ г ЬЮТЫХЭЭц. ПЪйЮ ЮУагСЫХЭЮ ЮвЮвЮЦЭШвШ ЧТгЪ Ч СгЪТЮо, вЮ Т СгФм-пЪЮЬг аЮбцЩбмЪЮЬг вХЪбвц ЭР 1000 СгЪТ ц ЯаЮСцЫцТ СгФХ 175 ЯаЮСцЫцТ, 90 — Ю, 62 — Р, 53 — в, 45 — б, 40 — а, 38 — Т... ц вцЫмЪШ 2 — д. ЖХЩ вШЯ ЩЬЮТцаЭЮбвц ЭРЧШТРфвмбп бХаХФЭмЮо ЩЬЮТцаЭцбво. їЮФцСЭц ФЮбЫцФЦХЭЭп ТШЪЮаШбвЮТговм ФЫп бЪЫРФРЭЭп ФагЪРабмЪШе ЪРб, ФЫп ЮЯШбг ЮбЮСЫШТЮбвХЩ ЮЪаХЬШе ЬЮТ, ацЧЭШе бвШЫцТ ЮФЭцфч ЬЮТШ РСЮ цЭФШТцФгРЫмЭЮУЮ РТвЮабмЪЮУЮ бвШЫо.
°бЯХЪв ЬЮТШ, ФЮ пЪЮУЮ ЧРбвЮбЮТговм вХЮацо ЩЬЮТцаЭЮбвц, ЭРЧШТРфвмбп вХЮаХвШЪЮ-ЩЬЮТцаЭцбЭШЬ.
ВХЮацо ЬЭЮЦШЭ ТШЪЮаШбвЮТговм ФЫп ФЮбЫцФЦХЭЭп ЪЫРбцТ ЬЮТЭШе ХЫХЬХЭвцТ, пЪц бЪЫРФРовм гЦХ ЭХ ЬЮТЫХЭЭфТШЩ ЫРЭжоЦЮЪ, Р ЯРаРФШУЬРвШЪг ЬЮТШ. јЭЮЦШЭг ваРЪвговм пЪ бгЪгЯЭцбвм ЮС'фЪвцТ, ЮС'фФЭРЭШе пЪЮобм бЯцЫмЭЮо ЮЧЭРЪЮо. ѕЧЭРЪР, пЪР ЮС'фФЭгф ЮС'фЪвШ г бЪЫРФц ЬЭЮЦШЭШ, ЬЮЦХ СгвШ пЪЮо ЧРТУЮФЭЮ. ВРЪ, бЪРЦцЬЮ, Тбц дЮЭХЬШ ЯХТжЮч ЬЮТШ, гбц бЫЮТЮдЮаЬШ ЯХТЭЮУЮ вХЪбвг, Тбц вХЪбвШ гЪаРчЭбмЪЮч ЬЮТШ ЬЮЦЭР цЭвХаЯаХвгТРвШ пЪ ЮЪаХЬц ЬЭЮЦШЭШ. ѕС'фЪвШ, йЮ бЪЫРФРовм ФРЭг ЬЭЮЦШЭг, ЭРЧШТРовм ХЫХЬХЭвРЬШ. їЮЧЭРзРовм ЬЭЮЦШЭг дцУгаЭШЬШ ФгЦЪРЬШ. ВРЪ, ЧРЯШб ° = {е, г,..., z} зШвРфвмбп вРЪ: цбЭгф ЬЭЮЦШЭР °, пЪР бЪЫРФРфвмбп Ч ХЫХЬХЭвцТ е, г,.... z.
јЭЮЦШЭг ЧРФРовм ФТЮЬР бЯЮбЮСРЬШ: ЯаЮбвШЬ ЯХаХаРегТРЭЭпЬ чч ХЫХЬХЭвцТ РСЮ ТЪРЧцТЪЮо ЭР ЮЧЭРЪг жШе ХЫХЬХЭвцТ. ЅРЯаШЪЫРФ: ° = {ґ, Ъ, е, ґ ', Ъ', е'} РСЮ ° ф ЬЭЮЦШЭР ЧРФЭмЮпЧШЪЮТШе ЯаШУЮЫЮбЭШе гЪаРчЭбмЪЮч ЬЮТШ.
јЭЮЦШЭР ЬЮЦХ бЪЫРФРвШбп ЭХ вцЫмЪШ Ч СРУРвмЮе, Р Щ Ч ЮФЭЮУЮ ХЫХЬХЭвР (ЭРЯаШЪЫРФ, ЬЭЮЦШЭР бХаХФЭмЮпЧШЪЮТШе бЪЫРФРфвмбп Ч ЮФЭЮУЮ ЧТгЪР [j]), ЬЮЦХ СгвШ Щ ЯЮаЮЦЭмЮо (ЭРЯаШЪЫРФ, ЬЭЮЦШЭШ ФЮТУШе ц ЪЮаЮвЪШе УЮЫЮбЭШе Т гЪаРчЭбмЪцЩ ЬЮТц). µЫХЬХЭвЮЬ ЬЭЮЦШЭШ ЬЮЦХ СгвШ цЭиР ЬЭЮЦШЭР (ФЧТцЭЪц ЯаШУЮЫЮбЭц — ЯцФЬЭЮЦШЭР ЬЭЮЦШЭШ ЯаШУЮЫЮбЭШе, Р ЯаШУЮЫЮбЭц — ЯцФЬЭЮЦШЭР ЬЭЮЦШЭШ ЧТгЪцТ). ЅРЫХЦЭцбвм ХЫХЬХЭвР ЬЭЮЦШЭц ЧРЯШбгфвмбп вРЪ: е ф °, йЮ зШвРфвмбп: " ХЫХЬХЭв е ЭРЫХЦШвм ФЮ ЬЭЮЦШЭШ °", Р ЭРЫХЦЭцбвм ЯцФЬЭЮЦШЭШ ЬЭЮЦШЭц ЧРЯШбгфвмбп, пЪ ° б ј (ЬЭЮЦШЭР ° ф ЯцФ ЬЭЮЦШЭЮо ЬЭЮЦШЭШ ј). ґТц ц СцЫмиХ ЬЭЮЦШЭ ЬЮЦгвм ЬРвШ бЯцЫмЭц ХЫХЬХЭвШ. Г вРЪЮЬг аРЧц УЮТЮапвм, йЮ жц ЬЭЮЦШЭШ ЯХаХвШЭРовмбп (ЭРЯаШЪЫРФ, ЬЭЮЦШЭШ УгСЭШе ЯаШУЮЫЮбЭШе ц ФЧТцЭЪШе ЯаШУЮЫЮбЭШе). їЮФцЫ ЬЭЮЦШЭ ЭР ЯцФЬЭЮЦШЭШ, пЪц ЭХ ЯХаХвШЭРовмбп, ф ЪЫРбШдцЪРжцфо ХЫХЬХЭвцТ.
АЮЧУЫпЭХЬЮ дЮЭХЬШ пЪ ЬЭЮЦШЭг. І ЬЮТц ЪЮЦЭР дЮЭХЬР ЯаЮвШбвРТЫХЭР ТбцЬ цЭиШЬ. ґЫп ЮЯШбг бШбвХЬШ дЮЭХЬ СгФм-пЪЮч ЬЮТШ ФЮбвРвЭмЮ 12 ЮЧЭРЪ, ЯаШзЮЬг ЪЮЦЭР Ч жШе ЮЧЭРЪ ЬЮЦХ СгвШ ЭРпТЭЮо РСЮ ТцФбгвЭмЮо. ВРЪШЬ зШЭЮЬ, ЬЭЮЦШЭР СгФХ бЪЫРФРвШбп Ч 212, вЮСвЮ 4096 ХЫХЬХЭвцТ. єЮЦХЭ ХЫХЬХЭв — жХ ЯХТЭХ ЯЮфФЭРЭЭп ЮФЭцфч ЮЧЭРЪШ Ч ФХЪцЫмЪЮЬР цЭиШЬШ Ч ФТРЭРФжпвШ. ѕвЦХ, 12 зЫХЭцТ ЮФЭцфч ЬЭЮЦШЭШ ЬЮЦгвм ЯЮфФЭгТРвШбп 4096 ацЧЭШЬШ бЯЮбЮСРЬШ ц гвТЮаоТРвШ вРЪг ЪцЫмЪцбвм ЯцФЬЭЮЦШЭ. БЪцЫмЪШ ф ЬЮЦЫШТШе ЯцФ ЬЭЮЦШЭ, бвцЫмЪШ ЬЮЦХ СгвШ ц дЮЭХЬ, ЮбЪцЫмЪШ ЪЮЦЭР ЯцФЬЭЮЦШЭР — жХ ЯХТЭХ ЯЮфФЭРЭЭп ЮЧЭРЪ дЮЭХЬ.
°бЯХЪв ЬЮТШ, ФЮ пЪЮУЮ ЧРбвЮбЮТговм вХЮацо ЬЭЮЦШЭ, ЭРЧШТРовм вХЮаХвШЪЮ-ЬЭЮЦШЭЭШЬ.
ѕвЦХ, бгзРбЭХ ЬЮТЮЧЭРТбвТЮ еРаРЪвХаШЧгфвмбп ЯаРУЭХЭЭпЬ ЯЮфФЭРвШ ц аЮЧгЬЭЮ ЪЮЬСцЭгТРвШ ацЧЭц ЧРУРЫмЭЮЭРгЪЮТц вР бЯХжцРЫмЭц ЫцЭУТцбвШзЭц ЬХвЮФШ. ЖХ ЯЮЧШвШТЭЮ ТЯЫШТРф ЭР аЮЧТШвЮЪ ЫцЭУТцбвШЪШ, ЮбЪцЫмЪШ ацЧЭц ЬХвЮФШ ФЮЯЮТЭоовм ЮФШЭ ЮФЭЮУЮ ц аРЧЮЬ ХдХЪвШТЭциХ ФЮЯЮЬРУРовм ТШТзШвШ вРЪШЩ бЪЫРФЭШЩ дХЭЮЬХЭ, пЪ ЬЮТг.