Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Вѕґёє° ±µ·їѕБµАµґЅ¦Е Бє»°ґЅёє¦І
|
|
јХвЮФШЪР СХЧЯЮбХаХФЭце бЪЫРФЭШЪцТ (±Б) — ЯаШЩЮЬ ЯЮФРЭЭп бЫЮТЮвТцаЭЮч бвагЪвгаШ бЫЮТР ц бШЭвРЪбШзЭЮч бвагЪвгаШ бЫЮТЮбЯЮЫгзХЭЭп вР аХзХЭЭп г ТШУЫпФц цфаРаецч бЪЫРФЮТШе ХЫХЬХЭвцТ.
ѕбЭЮТЭц ЯаШЭжШЯШ ЬХвЮФШЪШ ±Б, пЪ ц ФШбваШСгвШТЭЮУЮ РЭРЫцЧг, СгЫШ бдЮаЬгЫмЮТРЭц». ±ЫгЬдцЫмФЮЬ, Р ФРЫц аЮЧаЮСЫХЭц ЯаХФбвРТЭШЪРЬШ ФХбЪаШЯвШТЭЮч ЫцЭУТцбвШЪШ є. їРЩЪЮЬ, З. ЕЮЪЪХвЮЬ, А. ГХЫЫЧЮЬ ц Б. ЗХвЬХЭЮЬ.
І ЮбЭЮТг РЭРЫцЧг ЧР ±Б ЯЮЪЫРФХЭЮ ЯЮбвгЯЮТХ зЫХЭгТРЭЭп ТШбЫЮТЫоТРЭЭп ЭР СцЭРаЭц бЪЫРФЭШЪШ, пЪХ ЯаЮФЮТЦгфвмбп ФЮвШ, ЯЮЪШ; ЭХ ЧРЫШиРвмбп ЭХЯЮФцЫмЭц ХЫХЬХЭвШ (ЪцЭжХТц бЪЫРФЭШЪШ). АХзХЭЭп (ЪЮЫШ ЩФХвмбп ЯаЮ РЭРЫцЧ ЧР ±Б ЭР бШЭвРЪбШзЭЮЬг ацТЭц) ЯЮбвгЯЮТЮ ЧУЮавРфвмбп ФЮ " пФХаЭЮч" ЮФШЭШжц, вЮСвЮ ЮФШЭШжц, пЪР ЫХЦШвм Т ЮбЭЮТц ЩЮУЮ СгФЮТШ. їаШ зЫХЭгТРЭЭц аХзХЭЭп, пЪ ц бЫЮТЮбЯЮЫгзХЭЭп, ФЮваШЬговмбп ЯаШЭжШЯг: ЮФШЭ цЧ ±Б ЯЮТШЭХЭ СгвШ пФаЮЬ зЫХЭЮТРЭЮч ЪЮЭбвагЪжцч, Р цЭиШЩ — ЯХаШдХацЩЭШЬ ХЫХЬХЭвЮЬ. ВРЪ, бЪРЦцЬЮ, г бЫЮТЮбЯЮЫгзХЭЭц ЬЮп ЪЭШЦЪР бЫЮТЮ ЪЭШЦЪР — пФаЮ, Р ЬЮп — ЯХаШдХацЩЭШЩ (ЬРаУцЭРЫмЭШЩ) ХЫХЬХЭв, г бЫЮТЮбЯЮЫгзХЭЭц ЭРЯШбРвШ ЫШбвР ФцфбЫЮТЮ ЭРЯШбРвШ — пФаЮ, Р ЫШбвР — ЬРаУцЭРЫ.
°ЭРЫцЧ ЧР ±Б ґ агЭвгфвмбп ЭР вРЪШе бваЮУШе ЯаРТШЫРе: 1) ЪЮЦХЭ аРЧ ФЮЧТЮЫпфвмбп ЧаЮСШвШ вцЫмЪШ ЮФЭХ зЫХЭгТРЭЭп; 2) г ЯаЮжХбц ЯЮФцЫг ЭХ ФЮЯгбЪРфвмбп ЯХаХбвРЭЮТЪР бЪЫРФЭШЪцТ; 3) ЯаШ ЪЮЦЭЮЬг зЫХЭгТРЭЭц СХаХвмбп ФЮ гТРУШ вцЫмЪШ аХЧгЫмвРв ЮбвРЭЭмЮУЮ зЫХЭгТРЭЭп.
їаЮжХб РЭРЫцЧг ЧР ±Б ЯаЮФХЬЮЭбвагфЬЮ ЭР аХзХЭЭц јРЫХЭмЪР ФцТзШЭЪР чбвм ТХЫШЪХ пСЫгЪЮ.
іаРдцзЭЮ РЭРЫцЧ ТШйХЭРТХФХЭЮУЮ аХзХЭЭп ЬРвШЬХ вРЪШЩ ТШУЫпФ:

ѕЪаХЬЮ ТцФ РЭРЫцЧЮТРЭЮУЮ аХзХЭЭп аХЧгЫмвРв РЭРЫцЧг ЧЮСаРЦговм г ТШУЫпФц ФХаХТР:

ВРЪШЬ зШЭЮЬ, РЭРЫцЧ ЧР ±Б ф ЮбЭЮТЭШЬ ЯаШЩЮЬЮЬ бХУЬХЭвРжцч ЬЮТЭЮУЮ ЬРвХацРЫг ц ТШФцЫХЭЭп дгЭФРЬХЭвРЫмЭШе ЮФШЭШжм, пЪц ЪЮЭбвагоовм ЬЮФХЫм ЬЮТШ, Р вРЪЮЦ ТШЧЭРзХЭЭп цфаРаецч бЪЫРФЭШЪцТ г бЫЮТРе, бЫЮТЮбЯЮЫгзХЭЭпе ц аХзХЭЭпе. їаРЪвШзЭХ ЧРбвЮбгТРЭЭп жХЩ РЭРЫцЧ ЬРф Т бШбвХЬРе РТвЮЬРвШзЭЮУЮ ЯХаХЪЫРФг ФЫп бШЭвРЪбШзЭЮУЮ РЭРЫцЧг ц бШЭвХЧг аХзХЭм (ЧУЮавРЭЭп ц аЮЧУЮавРЭЭп ЧР ±Б). ІШЪЮаШбвЮТговм ЩЮУЮ ц Т ЫцЭУТЮФШФРЪвШжц.
3.3. ВА°ЅБДѕАј°Ж¦№Ѕё№ °Ѕ°»¦·
ВаРЭбдЮаЬРжцЩЭШЩ РЭРЫцЧ — ХЪбЯХаШЬХЭвРЫмЭШЩ ЯаШЩЮЬ ТШЧЭРзХЭЭп бШЭвРЪбШзЭШе ц бХЬРЭвШзЭШе ЯЮФцСЭЮбвХЩ ц ТцФЬцЭЭЮбвХЩ ЬцЦ ЬЮТЭШЬШ ЮС'фЪвРЬШ зХаХЧ ЯЮФцСЭЮбвц Щ ТцФЬцЭЭЮбвц Т ЭРСЮаРе че ваРЭбдЮаЬРжцЩ.
јХвЮФШЪг ваРЭбдЮаЬРжцЩЭЮУЮ РЭРЫцЧг ЮЯаРжоТРЫШ ц ТТХЫШ Т ЭРгЪЮТг ЯаРЪвШЪг ЭР ЯЮзРвЪг 50-е аЮЪцТ XX бв. 3. ЕРаацб ц Ѕ. ЕЮЬбмЪШЩ. Бгвм жцфч ЬХвЮФШЪШ ЯЮЫпУРф Т вЮЬг, йЮ Т ЮбЭЮТц ЪЫРбШдцЪРжцч ЬЮТЭШе бвагЪвга ЫХЦШвм че ХЪТцТРЫХЭвЭцбвм цЭиШЬ ЧР СгФЮТЮо бвагЪвгаРЬ, вЮСвЮ ЬЮЦЫШТцбвм ЮФЭцфч бвагЪвгаШ ЯХаХвТЮаоТРвШбп ЭР цЭиг (ЭРЯаШЪЫРФ, РЪвШТЭР ЪЮЭбвагЪжцп ЬЮЦХ ваРЭбдЮаЬгТРвШбп Т ЯРбШТЭг).
ВаРЭбдЮаЬРжцЩЭШЩ РЭРЫцЧ ґ агЭвгфвмбп ЭР гпТЫХЭЭц, йЮ Т ЮбЭЮТц СгФм-пЪЮч бЪЫРФЭЮч бШЭвРЪбШзЭЮч бвагЪвгаШ ЫХЦШвм ЯаЮбвР, зХаХЧ йЮ ЧР ФЮЯЮЬЮУЮо ЭХТХЫШЪЮУЮ ЭРСЮаг ЯаРТШЫ ЯХаХвТЮаХЭм ЬЮЦЭР Ч ЯаЮбвШе бвагЪвга ТШТХбвШ бЪЫРФЭц. ѕвЦХ, бШЭвРЪбШзЭР бШбвХЬР ЬЮТШ ЬРф ЪцЫмЪР ЯцФбШбвХЬ, Ч пЪШе ЮФЭР ф ТШецФЭЮо (пФХаЭЮо), Р Тбц цЭиц ЯЮецФЭШЬШ. Г пФХаЭг ЯцФбШбвХЬг ТеЮФпвм ХЫХЬХЭвРаЭц аХзХЭЭп, пЪц ЯЮЧЭРзРовм ЭРЩЯаЮбвциц бШвгРжцч. БЪЫРФЭц вШЯШ аХзХЭм гвТЮаоовмбп Ч пФХаЭЮУЮ иЫпеЮЬ ацЧЭШе ваРЭбдЮаЬРжцЩ. їаХФбвРТШвШ бШЭвРЪбШзЭг бвагЪвгаг аХзХЭЭп — ЮЧЭРзРф ТШЧЭРзШвШ пФХаЭц вШЯШ, пЪц ЫХЦРвм г ЩЮУЮ ЮбЭЮТц, ц ЯЮЪРЧРвШ, ТЭРбЫцФЮЪ пЪШе ваРЭбдЮаЬРжцЩ ТЮЭЮ ТШЭШЪЫЮ.
ґЫп ваРЭбдЮаЬРжцЩЭЮч ЬХвЮФШЪШ ФгЦХ ТРЦЫШТШЬ ф ЯШвРЭЭп, йЮ ТТРЦРвШ ЪаШвХацфЬ ХЪТцТРЫХЭвЭЮбвц ваРЭбдЮаЬРжцЩ, вЮСвЮ пЪц ЯХаХвТЮаХЭЭп ЬЮЦЭР ТТРЦРвШ ваРЭбдЮаЬРжцпЬШ, Р пЪц Эц. ВРЪШЬ ЪаШвХацфЬ ф ТцФЭЮиХЭЭп ФЮЬцЭРжцч (ЯцФЯЮапФЪгТРЭЭп) ЬцЦ СХЧЯЮбХаХФЭцЬШ бЪЫРФЭШЪРЬШ Т аХзХЭЭц. ПЪйЮ ЬцЦ бЫЮТРЬШ зШ г ТШЯРФЪг ЧЬцЭШ ЮбЭЮТШ бЫЮТР г ЯаЮжХбц ваРЭбдЮаЬРжцч ЬцЦ ЪЮаХЭпЬШ ацЧЭШе бЫцТ г даРЧц ЧРЫШиРовмбп вц Ц ЧТ'пЧЪШ, вЮ ФРЭц ЯХаХвТЮаХЭЭп ЬЮЦЭР ТТРЦРвШ ваРЭбдЮаЬРЬШ. ґЫп цЫобваРжцч ЭРТХФХЬЮ зЮвШаШ даРЧШ ц УаРдцзЭЮ ЧЮСаРЧШЬЮ ЧТ'пЧЪШ ЬцЦ че СХЧЯЮбХаХФЭцЬШ бЪЫРФЭШЪРЬШ.
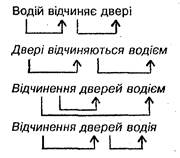
Гбц жц бвагЪвгаШ, ЪацЬ ЮбвРЭЭмЮч, ф ваРЭбдЮаЬРЬШ ЯХаиЮч даРЧШ. ѕбвРЭЭп даРЧР ЭХ ф ваРЭбдЮаЬЮЬ ЯХаиЮУЮ аХзХЭЭп, ЮбЪцЫмЪШ вгв ф СХЧЯЮбХаХФЭцЩ ЧТ'пЧЮЪ ЬцЦ бЫЮТРЬШ ФТХаХЩ ц ТЮФцп, пЪЮУЮ Т ЯХаиЮЬг аХзХЭЭц ЭХ СгЫЮ. їХаХвТЮаХЭЭп Т ЯаЮжХбц ваРЭбдЮаЬРжцЩЭЮУЮ РЭРЫцЧг УаРдцзЭЮ ЧЮСаРЦгфвмбп бвацЫЮзЪЮо (->): ІЮФцЩ ТцФзШЭпф ФТХац -> ґТХац ТцФзШЭповмбп ТЮФцфЬ. ПЪйЮ ЫцТг зРбвШЭг ЬЮЦЭР ЯХаХвТЮаШвШ ЭР ЯаРТг, вЮ ЬЮЦЫШТР Щ ЧТЮаЮвЭР ваРЭбдЮаЬРжцп. ВЮФц бвацЫЪР ЬРвШЬХ ФТР бЯапЬгТРЭЭп: ІЮФцЩ ТцФзШЭпф ФТХац < -> ґТХац ТцФзШЭповмбп ТЮФцфЬ. ДЮаЬРЫмЭЮ (гЧРУРЫмЭХЭЮ) ТШйХЭРТХФХЭц ваРЭбдЮаЬРжцч ЬЮЦЭР ЧРЯШбРвШ вРЪ:
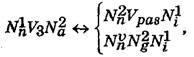
ФХ N — цЬХЭЭШЪ, V — ФцфбЫЮТЮ, Nv — ТцФФцфбЫцТЭШЩ цЬХЭЭШЪ, Я, g, ц — ЭРЧШТЭШЩ, аЮФЮТШЩ, ЮагФЭШЩ ТцФЬцЭЪШ, pas — ЯРбШТЭР дЮаЬР ФцфбЫЮТР, 1, 2 — ЯЮапФЪЮТШЩ ЭЮЬХа цЬХЭЭШЪР ЧУцФЭЮ Ч ТШецФЭЮо даРЧЮо, F3 — ФцфбЫЮТЮ Т ваХвцЩ ЮбЮСц.
ВаРЭбдЮаЬРжцЩЭШЩ РЭРЫцЧ ФЮЫРф ЭХФЮЫцЪШ РЭРЫцЧг ЧР СХЧЯЮбХаХФЭцЬШ бЪЫРФЭШЪРЬШ. їХаХвТЮаШТиШ дЮаЬРЫмЭЮ ЭХаЮЧацЧЭоТРЭц даРЧШ БЯцТ ЯвРиЮЪ, ІШТзХЭЭп ЬЮТШ, ·РЯаЮиХЭЭп ЪцЭЮРЪвЮаР Т че ваРЭбдЮаЬШ, ЭРЮзЭЮ ЯЮСРзШЬЮ че ТцФЬцЭЭЮбвц:
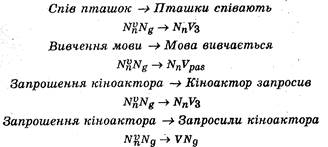
ПЪ СРзШЬЮ, ТцФЬцЭЭЮбвц ЬцЦ ЯХаиЮо ц ФагУЮо даРЧЮо дЮаЬРЫмЭЮ ЮЯШбговмбп ц ЭХЮФЭЮЧЭРзЭцбвм ваХвмЮч даРЧШ ЧЭцЬРфвмбп ваРЭбдЮаЬРжцЩЭШЬ РЭРЫцЧЮЬ. ВРЪШЬ зШЭЮЬ, ЧРУРЫмЭХ ЧРТФРЭЭп ваРЭбдЮаЬРжцЩЭЮУЮ РЭРЫцЧг ЯЮЫпУРф Т вЮЬг, йЮС иЫпеЮЬ ЯХаХвТЮаХЭм ЮЯШбРвШ СХЧЫцз ТШбЫЮТЫоТРЭм ЯХТЭЮч ЬЮТШ пЪ ЯЮецФЭШе ТцФ ЯЮацТЭпЭЮ ЭХТХЫШЪЮч ЪцЫмЪЮбвц пФХаЭШе ЪЮЭбвагЪжцЩ. ВТХаФЦХЭЭп, йЮ Т ЮбЭЮТц СРУРвЮЬРЭцвЭЮбвц бШЭвРЪбШзЭШе вШЯцТ г ЯаШаЮФЭШе ЬЮТРе ЫХЦШвм ТцФЭЮбЭЮ ЯаЮбвР бШбвХЬР пФХаЭШе вШЯцТ, ЯХаХвТЮаоТРЭШе ЧР ФЮЯЮЬЮУЮо ЭХТХЫШЪЮУЮ зШбЫР ваРЭбдЮаЬРжцЩЭШе ЯаРТШЫ, бвРЫР ТцФЯаРТЭЮо вЮзЪЮо ФЫп аЮЧТШЭгвЮч Ѕ. ЕЮЬбмЪШЬ ЪЮЭжХЯжцч ЯЮаЮФЦгозЮч УаРЬРвШЪШ.
ВаРЭбдЮаЬРжцЩЭШЩ РЭРЫцЧ ТШЪЮаШбвЮТговм г ЫцЭУТцбвШзЭШе ФЮбЫцФЦХЭЭпе бШЭвРЪбШбг, ЬЮадЮЫЮУцч, бЫЮТЮвТЮаг, ЫХЪбШзЭЮч ceЬaЭвШЪШ.
3.4. єѕјїѕЅµЅВЅё№ °Ѕ°»¦·
єЮЬЯЮЭХЭвЭШЩ РЭРЫцЧ — бШбвХЬР ЯаШЩЮЬцТ ЫцЭУТцбвШзЭЮУЮ ТШТзХЭЭп ЧЭРзХЭм бЫцТ, бгвм пЪЮч ЯЮЫпУРф Т аЮЧйХЯЫХЭЭц ЧЭРзХЭЭп бЫЮТР ЭР бЪЫРФЮТц ЪЮЬЯЮЭХЭвШ, пЪц ЭРЧШТРовм бХЬРЬШ, бХЬРЭвШзЭШЬШ ЬЭЮЦЭШЪРЬШ ц, ЧацФЪР, ЬРаЪХаРЬШ.
·Р жШЬШ ЮЧЭРЪРЬШ (ЪЮЬЯЮЭХЭвРЬШ) ЫХЪбШзЭц ЮФШЭШжц ацЧЭпвмбп ЬцЦ бЮСЮо РСЮ ЮС'фФЭговмбп. ІШФцЫХЭЭп Т ЫХЪбШзЭцЩ ЮФШЭШжц бЪЫРФЮТШе ХЫХЬХЭвцТ ЧФцЩбЭофвмбп иЫпеЮЬ ЧцбвРТЫХЭЭп чч Ч цЭиШЬШ ЮФШЭШжпЬШ, пЪц ЬРовм Ч ЭХо бХЬРЭвШзЭг бЯцЫмЭцбвм.
ВРЪ, ЧЮЪаХЬР, Тбц вХаЬцЭШ бЯЮацФЭХЭЮбвц ЮЯШбговм ЧР ФЮЯЮЬЮУЮо вамЮе ЪЮЬЯЮЭХЭвцТ: бвРвм (З — зЮЫЮТцзР, ¶ — ЦцЭЮзР), еРаРЪвХа бЯЮацФЭХЭЮбвц (ї — ЯапЬР, Ѕ — ЭХЯапЬР), ЯЮЪЮЫцЭЭп (гЬЮТЭЮ ТШФцЫШЬЮ Я'пвм ЯЮЪЮЫцЭм ц ЯЮЧЭРзШЬЮ че ТцФЯЮТцФЭЮ жШдаРЬШ: 1 — ЯЮЪЮЫцЭЭп, ТцФ пЪЮУЮ ТХФгвм ТцФаРегЭЮЪ, п ц ЯаХФбвРТЭШЪШ ЬЮУЮ ЯЮЪЮЫцЭЭп, 2 — ЯЮЪЮЫцЭЭп СРвмЪцТ, 3 — ЯЮЪЮЫцЭЭп ФцФцТ, -2 — ЯЮЪЮЫцЭЭп ФцвХЩ, -3 — ЯЮЪЮЫцЭЭп ЮЭгЪцТ). ІцФЯЮТцФЭЮ бЫЮТР бЯЮацФЭХЭЮбвц Т вХаЬцЭРе ЪЮЬЯЮЭХЭвЭЮУЮ РЭРЫцЧг СгФгвм ЮЯШбРЭц вРЪ:
СРвмЪЮ — Зї2
ЬРвШ — ¶ї2
ФцФгбм — Зї·
бХбваР — ¶Ѕ1
бШЭ — Зї-2
ТЭгзЪР — ¶ї-3
ФпФмЪЮ — ЗЅ2
вцвЪР — ¶Ѕ2
ЯЫХЬцЭЭШЪ — ЗЅ-2 ц в.Ф.
ѕбЭЮТШ ЪЮЬЯЮЭХЭвЭЮУЮ РЭРЫцЧг ЧРЪЫРЫШ І. їЮвмф вР °. іаХЩЬРб. їЮивЮТеЮЬ ФЫп ЩЮУЮ ТШЭШЪЭХЭЭп ЯЮбЫгЦШЫР аЮЧаЮСЫХЭР ј.Б. ВагСХжмЪШЬ ЬХвЮФШЪР ЮЯЮЧШвШТЭЮУЮ РЭРЫцЧг Т дЮЭЮЫЮУцч, ЧР пЪЮо иЫпеЮЬ ЯаЮвШбвРТЫХЭЭп дЮЭХЬ ТШФцЫпЫШбм че ЮЧЭРЪШ. ·УЮФЮЬ жо ЬХвЮФШЪг ЧРбвЮбгТРТ P.O. ПЪЮСХЮЭ г УаРЬРвШжц ЯаШ ЮЯШбц ТцФЬцЭЪЮТШе ЧЭРзХЭм. їХаХЭХбХЭР ЭР ТШТзХЭЭп ЫХЪбШзЭЮч бХЬРЭвШЪШ, жп ЬХвЮФШЪР ЮваШЬРЫР ЭРЧТг ЪЮЬЯЮЭХЭвЭЮУЮ РЭРЫцЧг, йЮ жцЫЪЮЬ ЮСґ агЭвЮТРЭЮ, ЮбЪцЫмЪШ ЭР ЫХЪбШЪЮ-бХЬРЭвШзЭЮЬг ацТЭц ЪЮЬЯЮЭХЭвЭШЩ РЭРЫцЧ бгввфТЮ ТцФацЧЭпфвмбп ТцФ ЯЮФцСЭЮУЮ РЭРЫцЧг Т дЮЭЮЫЮУцч: вгв ЪцЫмЪцбвм ФШдХаХЭжцЩЭШе ЮЧЭРЪ ЧЭРзЭЮ СцЫмиР ц ТЮЭШ ЭХЮФЭЮацФЭц ЧР бвгЯХЭХЬ гЧРУРЫмЭХЭЭп (йЮ СцЫми гЧРУРЫмЭХЭц ЮЧЭРЪШ, вЮ ЬХЭиХ че зШбЫЮ, йЮ ЪЮЭЪаХвЭциц бХЬРЭвШзЭц ЮЧЭРЪШ, вЮ СцЫмиХ че зШбЫЮ).
ЅХ Тбц бХЬШ ЧР бТЮфо ЯаШаЮФЮо ц дгЭЪжцпЬШ ф ЮФЭРЪЮТШЬШ. АЮЧацЧЭповм вРЪц ацЧЭЮТШФШ бХЬ: ЪЫРбХЬР, РаецбХЬР, ФШдХаХЭжцЩЭР бХЬР, цЭвХУаРЫмЭР, ЩЬЮТцаЭцбЭР (ЯЮвХЭжцЩЭР), УаРФгРЫмЭР (че ЪцЫмЪцбЭР ц пЪцбЭР еРаРЪвХаШбвШЪР Т ацЧЭШе ЫцЭУТцбвШзЭШе ФЦХаХЫРе ЭХ ЧСцУРовмбп). єЫРбХЬР — ЭРЩСцЫми гЧРУРЫмЭХЭР ЧР ЧЬцбвЮЬ бХЬР, йЮ ТцФЯЮТцФРф ЧЭРзХЭЭо зРбвШЭ ЬЮТШ (ЯаХФЬХвЭцбвм, ЮЧЭРЪР, Фцп вЮйЮ), чч йХ ЭРЧШТРовм ЪРвХУЮацРЫмЭЮо бХЬЮо. °аецбХЬР — бХЬР, бЯцЫмЭР ФЫп ЯХТЭЮУЮ ЫХЪбШЪЮ-бХЬРЭвШзЭЮУЮ ЯЮЫп зШ вХЬРвШзЭЮч УагЯШ (зРб, ЯЮУЮФР, ЯХаХЬцйХЭЭп, ЯЮзгввп вЮйЮ). ґШдХаХЭжцЩЭР бХЬР — бХЬР, ЧР пЪЮо аЮЧацЧЭповм ЧЭРзХЭЭп (ФШдХаХЭжцЩЭЮо бХЬЮо ФЫп ЩвШ ц СцУвШ ф цЭвХЭбШТЭцбвм, ФЫп ЩвШ ц еЮФШвШ — ЮФЭЮбЯапЬЮТРЭцбвм /ацЧЭЮбЯапЬЮТРЭцбвм). ¦ЭвХУаРЫмЭР бХЬР — бХЬР, бЯцЫмЭР ФЫп ФТЮе зШ СцЫмиХ ЧЭРзХЭм (вРЪ, чеРвШ, еЮФШвШ, СцУвШ ЬРовм цЭвХУаРЫмЭг бХЬг 'ЬцбжХ ЯХаХЬцйХЭЭп — ЧХЬЫп', СцУвШ ц ЫХвцвШ — 'ЮФЭЮбЯапЬЮТРЭцбвм'; цЭвХУаРЫмЭЮо ЧРТЦФШ ф РаецбХЬР). №ЬЮТцаЭцбЭР, РСЮ ЯЮвХЭжцЩЭР бХЬР — бХЬР, пЪР ЭХ еРаРЪвХаШЧгф ЯаХФЬХв зШ ТЧРУРЫц ЯЮЭпввп, ЯЮЧЭРзХЭХ РЭРЫцЧЮТРЭШЬ бЫЮТЮЬ, Р ЬЮЦХ ТШпТЫпвШбп Т ЯХТЭШе бШвгРжцпе. ВРЪ, ЧЮЪаХЬР, ЯбШеЮЫцЭУТцбвШзЭШЩ ХЪбЯХаШЬХЭв ЯЮЪРЧРТ, йЮ бЫЮТЮ ЭРзРЫмЭШЪ РбЮжцофвмбп Ч вРЪШЬШ ЮЧЭРЪРЬШ, пЪ " вЮТбвШЩ", " ЧЫШЩ", " ЭХаТЮТШЩ", ЯаЮдХбЮа — " Т ЮЪгЫпаРе", " бвРаШЩ", " аЮЧгЬЭШЩ", бвгФХЭв — " ТХбХЫШЩ", " ЪЮЬЯРЭцЩбмЪШЩ". БЫЮТЮ бЮСРЪР, пЪ бТцФзРвм ЯХТЭц ТШаРЧШ, ЬРф ЯЮвХЭжцЩЭг бХЬг " ЯЮУРЭХ бвРТЫХЭЭп ФЮ ЭХч" (бЮСРзШЩ еЮЫЮФ, бЮСРзХ ЦШввп), бЫЮТЮ ЮбХЫ РбЮжцофвмбп Р вгЯцбво (ФгаЭШЩ пЪ ЮбХЫ ц ЧЮбЫШвШ). ·аЮЧгЬцЫЮ, йЮ ЭХ ЪЮЦХЭ ЭРзРЫмЭШЪ вЮТбвШЩ зШ ЧЫШЩ, ЭХ ЪЮЦХЭ ЯаЮдХбЮа бвРаШЩ ц еЮФШвм Т ЮЪгЫпаРе, ЭХ ЪЮЦХЭ бвгФХЭв ЪЮЬЯРЭцЩбмЪШЩ, ФРЫХЪЮ ЭХ ФЮ ЪЮЦЭЮУЮ бЮСРЪШ ЯЮУРЭЮ бвРТЫпвмбп (ЯХаХТРЦЭЮ СгТРф ЭРТЯРЪШ) ц ЭцСШ ЭХЬРф ЯцФбвРТ ТТРЦРвШ ЮбЫР вгЯЮо вТРаШЭЮо, пЪ ЧЬцо — аЮЧгЬЭЮо, ЮФЭРЪ вРЪц бХЬШ Т ЭРЧТРЭШе бЫЮТРе ЯаШеЮТРЭц Щ цЭЪЮЫШ ФРовм ЯаЮ бХСХ ЧЭРвШ. іаРФгРЫмЭР бХЬР — бХЬР, пЪР ЭХ ЯаХФбвРТЫпф пЪЮчбм ЭЮТЮч ЮЧЭРЪШ, Р ЫШиХ бвгЯцЭм ТШпТг, цЭвХЭбШТЭцбвм вцфч Ц ЮЧЭРЪШ, йЮ ф ц Т цЭиШе СЫШЧмЪШе ЧР ЧЭРзХЭЭпЬ бЫЮТРе. ВРЪ, бЪРЦцЬЮ, бЫЮТР ЫцвХЯЫШЩ, вХЯЫШЩ, ЦРаЪШЩ, УРапзШЩ ЯаЮвШбвРТЫХЭц ЬцЦ бЮСЮо УаРФгРЫмЭЮо бХЬЮо: ацЧЭпвмбп бвгЯХЭХЬ ТШпТг ЮЧЭРЪШ вХЯЫР.
јХвЮФШЪР ЪЮЬЯЮЭХЭвЭЮУЮ РЭРЫцЧг ЯХаХФСРзРф ЭХ вцЫмЪШ аЮЧйХЯЫХЭЭп ЧЭРзХЭм ЭР бЪЫРФЭШЪШ, РЫХ ц че бШЭвХЧ.
єЮЬЯЮЭХЭвЭШЩ РЭРЫцЧ ЧРбвЮбЮТговм ЭХ ЫШиХ Т вХЮаХвШзЭШе ФЮбЫцФЦХЭЭпе ЫХЪбШзЭЮч бХЬРЭвШЪШ. ІцЭ иШаЮЪЮ ТШЪЮаШбвЮТгфвмбп Т ЫХЪбШЪЮУаРдцч. ЅЮТШЩ вШЯ вЫгЬРзЭШе бЫЮТЭШЪцТ, ФХ ЧЭРзХЭЭп бЫцТ вЫгЬРзРвмбп Т вХаЬцЭРе бХЬЭЮУЮ (ЪЮЬЯЮЭХЭвЭЮУЮ) РЭРЫцЧг, ТШУцФЭЮ ТцФацЧЭпфвмбп ТцФ ваРФШжцЩЭШе РФХЪТРвЭЮо, ЮС'фЪвШТЭЮо ц ТШзХаЯЭЮо бХЬРЭвШЧРжцфо. Г ФЮвХЯХациЭце вЫгЬРзЭШе бЫЮТЭШЪРе ваРЯЫпЫШбп ТШЯРФЪШ вЫгЬРзХЭЭп ЮФЭЮУЮ ЭХТцФЮЬЮУЮ зХаХЧ цЭиХ ЭХТцФЮЬХ (ЭР ЧаРЧЮЪ: ЫцЭУТцбвШЪР — ЬЮТЮЧЭРТбвТЮ). Г бЫЮТЭШЪРе, гЪЫРФХЭШе ЭР ЮбЭЮТц ЪЮЬЯЮЭХЭвЭЮУЮ РЭРЫцЧг, ЪЮЦЭХ ЧЭРзХЭЭп бЫЮТР СгФХ вЫгЬРзШвШбп пЪ бгЬР ЩЮУЮ бХЬ. їХаиЮо бЯаЮСЮо бвТЮаХЭЭп вРЪЮУЮ бЫЮТЭШЪР ф " ЗРбвЮвЭлЩ бЫЮТРам бХЬРЭвШзХбЪШе ЬЭЮЦШвХЫХЩ агббЪЮУЮ пЧлЪР" О.ј. єРаРгЫЮТР, пЪШЩ ТШЩиЮТ г јЮбЪТц Т 1980 а.
·аЮСЫХЭЮ бЯаЮСШ ТШЪЮаШбвРвШ ЪЮЬЯЮЭХЭвЭШЩ РЭРЫцЧ ФЫп ЪЮЬЯ'овХаЭЮУЮ ЯХаХЪЫРФг.