Главная страница Случайная страница
КАТЕГОРИИ:
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Проблема гетероскедастичности
|
|
При проведении регрессионного анализа, основанного на методе наименьших квадратов, на практике следует обратить серьезное внимание на проблемы, связанные с выполнимостью свойств случайных отклонений моделей. Как мы отмечали ранее, свойства оценок коэффициентов регрессии напрямую зависят от свойств случайного члена в уравнении регрессии. Для получения качественных оценок необходимо следить за выполнимостью предпосылок МНК, т. к. при их нарушении MIIK может давать оценки с плохими статистическими свойствами. Одной из ключевых предпосылок МНК является условие постоянства дисперсий случайных отклонений.
Выполнимость данной предпосылки называется гомоскедастичностью (постоянством дисперсии отклонений). Невыполнимость данной предпосылки называется гетероскедастичностъю (непостоянством дисперсий отклонений). Необходимо выяснить суть гетероскедастичности, ее причины и последствия, а рассмотреть способы смягчения этих последствий.
При рассмотрении выборочных данных требование постоянства дисперсии случайных отклонений может вызвать определенное недоумение в силу того, что при каждом i-м наблюдении имеется единственное значение ошибки e i. Откуда же появляется разброс? Дело в том, что при рассмотрении выборочных данных мы имеем дело с конкретными реализациями зависимой переменной у i, и соответственно с определенными случайными отклонениями e i. i = 1, 2..... n. Но до осуществления выборки эти показатели априори могли принимать произвольные значения на основе некоторых вероятностных распределений. Одним из требований к этим распределениям является равенство дисперсий. Данное условие подразумевает, что несмотря на то что при каждом конкретном наблюдении случайное отклонение может быть большим либо маленьким, положительным либо отрицательным, не должно быть некой априорной причины, вызывающей большую ошибку (отклонение) при одних наблюдениях и меньшую - при других.
Однако на практике гетероскедастичность не так уж и редка. Зачастую есть основания считать, что вероятностные распределения случайных отклонений e i при различных наблюдениях будут различными. Это не означает, что случайные отклонения обязательно будут большими при определенных наблюдениях и малыми – при других, но это означает, что априорная вероятность этого велика. Поэтому важно понимать суть этого явления и его последствия. На рис. приведены 2 примера линейной регрессии – зависимости потребления С от дохода I:
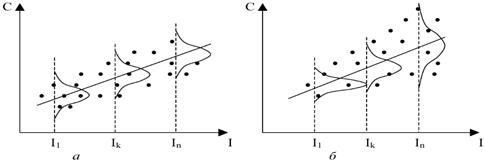
В обоих случаях с ростом дохода растет среднее значение потребления. Но если на рис. а дисперсия потребления остается одной и той же для различных уровней дохода, то на рис. при аналогичной зависимости среднего потребления от дохода дисперсия потребления не остается постоянной, а увеличивается с ростом дохода. Фактически это означает, что во втором случае субъекты с большим доходом в среднем потребляют больше, чем субъекты с меньшим доходом, и, кроме того, разброс в их потреблении более существенен для большего уровня дохода. Фактически люди с большими доходами имеют больший простор для распределения своего дохода. Реалистичность данной ситуации не вызывает сомнений. Разброс значений потребления вызывает разброс точек наблюдения относительно линии регрессии, что и определяет дисперсию случайных отклонений. Динамика изменения дисперсий отклонений для данного примера проиллюстрирована на рис. 8.2. При гомоскедастичности (рис. а) дисперсии постоянны, а при гетероскедасгичности (рис. б) дисперсии изменяются (в нашем примере - увеличиваются).
Проблема гетероскедастичности в большей степени характерна для перекрестных данных и довольно редко встречается при рассмотрении временных рядов. Это можно объяснить следующим образом. При перекрестных данных учитываются экономические субъекты (потребители, домохозяйства, фирмы, отрасли, страны и т. д.), имеющие различные доходы, размеры, потребности и т. д. Но в этом случае возможны проблемы, связанные с эффектом масштаба. Во временных рядах обычно рассматриваются одни и те же показатели в различные моменты времени (например, ВНП, чистый экспорт, темпы инфляции и т. д. в определенном регионе за определенный период времени). Однако при увеличении (уменьшении) рассматриваемых показателей с течением времени может возникнуть проблема гетероскедастичности.
Но МНК дает наилучшие линейные несмещенные оценки лишь при выполнении ряда предпосылок, одной из которых является постоянство дисперсии отклонений (гомоскедастичность) для всех наблюдений. При невыполнимости данной предпосылки (при гетероскедастичности) последствия будут следующими.
1. Оценки коэффициентов по-прежнему остаются несмещенными и линейными.
2. Оценки не будут эффективными (т. е. они не будут иметь наименьшую дисперсию по сравнению с другими оценками данного параметра). Они не будут даже асимптотически эффективными. Увеличение дисперсии оценок снижает вероятность получения максимально точных оценок.
3. Дисперсии оценок будут рассчитываться со смещением. Смещенность появляется вследствие того, что необъясненная уравнением регрессии дисперсия, которая используется при вычислении оценок дисперсий всех коэффициентов, не является более несмещенной.
4. Вследствие вышесказанного все выводы, получаемые на основе соответствующих статистик, а также интервальные оценки будут ненадежными. Следовательно, статистические выводы, получаемые при стандартных проверках качества оценок, могут быть ошибочными и приводить к неверным заключениям по построенной модели. Вполне вероятно, что стандартные ошибки коэффициентов будут занижены, а следовательно, t-статистики будут завышены. Это может привести к признанию статистически значимыми коэффициентов, таковыми на самом деле не являющимися.
Причину неэффективности оценок МНК при гетероскедастичности легко пояснить следующим примером парной регрессии.

Из рис. видно, что для каждого конкретного значения xi\ СВ X переменная Y принимает значение уi из некоторого множества, имеющего свое распределение, отличное одно от другого в силу непостоянства дисперсий.
По МНК минимизируется сумма квадратов отклонений. Но в этом случае каждое конкретное значение е i2 имеет одинаковый " вес" вне зависимости от того, получено оно из распределения с маленькой дисперсией или с большой. Но это противоречит логике, т. к. точка, полученная из распределения с меньшей дисперсией, более точно определяет направление линии регрессии. Поэтому она должна иметь больший " вес", чем точка из распределения с большей дисперсией. Следовательно, методы оценивания, учитывающие " веса" точек наблюдений, позволяют получать более точные (эффективные) оценки. Учет " весов" точек характерен, например, для метода взвешенных наименьших квадратов, рассматриваемого ниже.